
Google AI提出MLP-Mixer:只需MLP就在ImageNet达到SOTA!
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近日,Google AI又发布了一篇与ViT一样的重磅级论文:MLP-Mixer: An all-MLP Architecture for Vision。这篇论文提出的Mixer模型仅包含最简单的MLP结构就能在ImageNet上达到SOTA。那么MLP其实是两层FC层,这不禁让人感叹:
FC is all you need, neither Conv nor Attention!
在数据和资源足够的情况下,或许inductive bias的模型反而成了束缚,还不如最simple的模型来的直接。下面结果图就可以说明一切:当训练数据量较少时,性能BiT>ViT>Mixer,但是随着数据量的增加,三者性能基本相差无几。

从网络架构来看,MLP-Mixer和ViT非常类似:
预处理都是将图像分成patchs,通过linear projection得到一系列patch embeddings;
网络主体都是isotropic design,即由N个连续且相同的layers来组成。
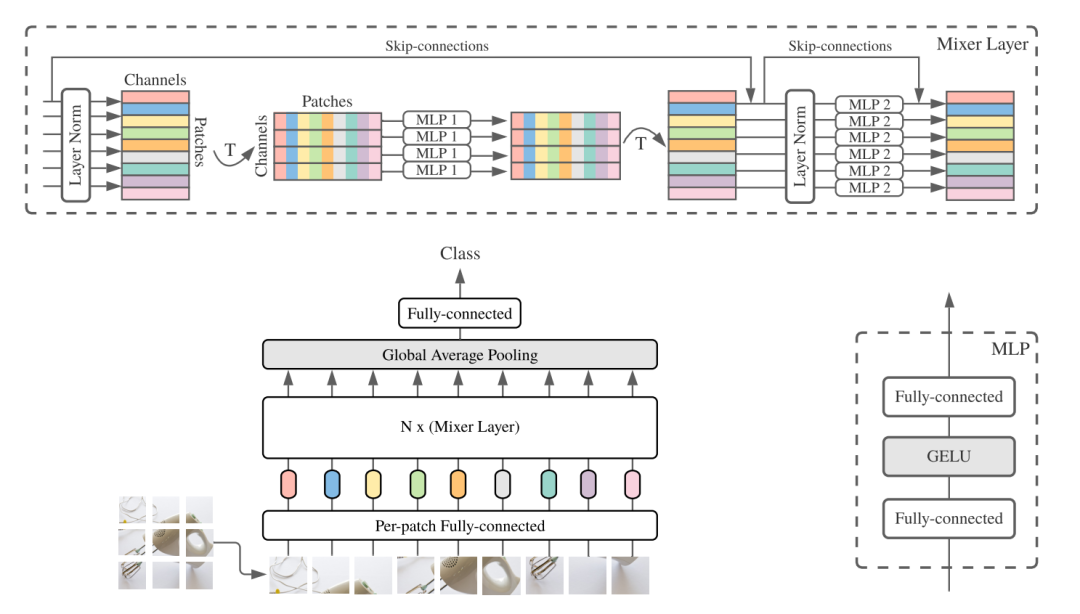
差别主要体现在layers的不同,ViT采用的是transformer layer,而MLP-Mixer采用的是mixer-layer,mixer-layer很简单,只包括两个MLP(还有skip connection):
(1)token-mixing MLP block:输入的特征维度 为 ,操作的维度是tokens,意味着对所有tokens的同一特征做MLP;
,操作的维度是tokens,意味着对所有tokens的同一特征做MLP;
(2)channel-mixing MLP block:输入的特征维度为  ,操作的维度是channels,意味着对各个tokens的所有特征做MLP。
,操作的维度是channels,意味着对各个tokens的所有特征做MLP。

对于图像,大部分的网络无非是从两个方面mix features:
(i) at a given spatial location,
(ii) between different spatial locations,
比如卷积其实是同时进行(i)和(ii),特别地1x1卷积只完成(i),single-channel depth-wise conv 只完成(ii);而transformer layer比较复杂,projection layer实现的是(i),self-attention实现的是(ii)(实际上也会涉及(i)),FFN实现的是(i)。而对于mixer-layer,其实就完全分离两个部分了,token-mixing MLP block实现的是(ii),channel-mixing MLP block实现的是(i),这也算是设计上的一个巧妙解释吧。
由于channel mixing MLP是permutation-variant,对tokens的顺序是敏感的,这和ViT不同,因为self-attention是permutation-invariant的。因次Mixer不需要e position
embedding。不过由于token-mixing MLP block的存在,这也意味着网络只能接受固定size的图像输入,毕竟这里MLP的参数依赖于tokens的数量,这对于dense prediction任务来说,可能有点麻烦,因为检测和分割的基本都是变输入。
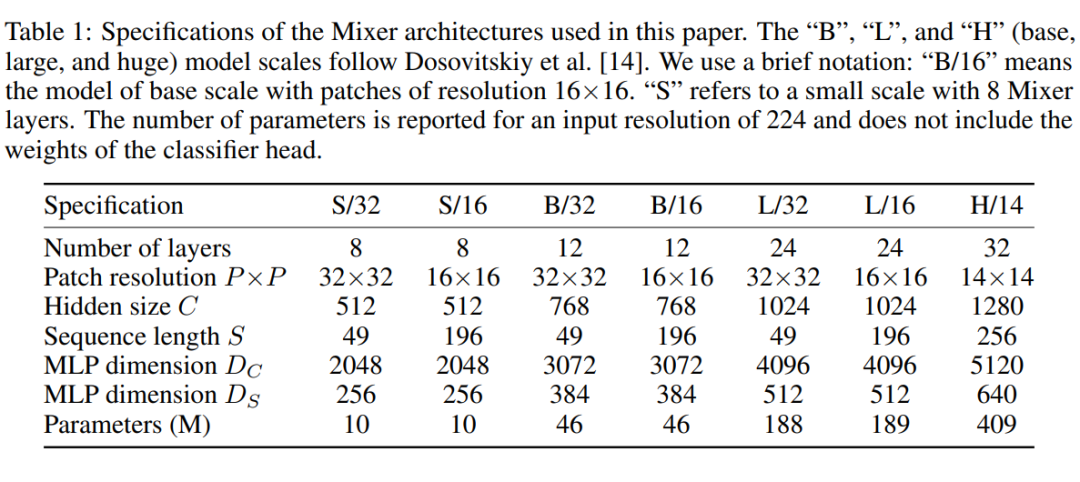
Mixer的网络参数设计和ViT较为类似,具体如下:
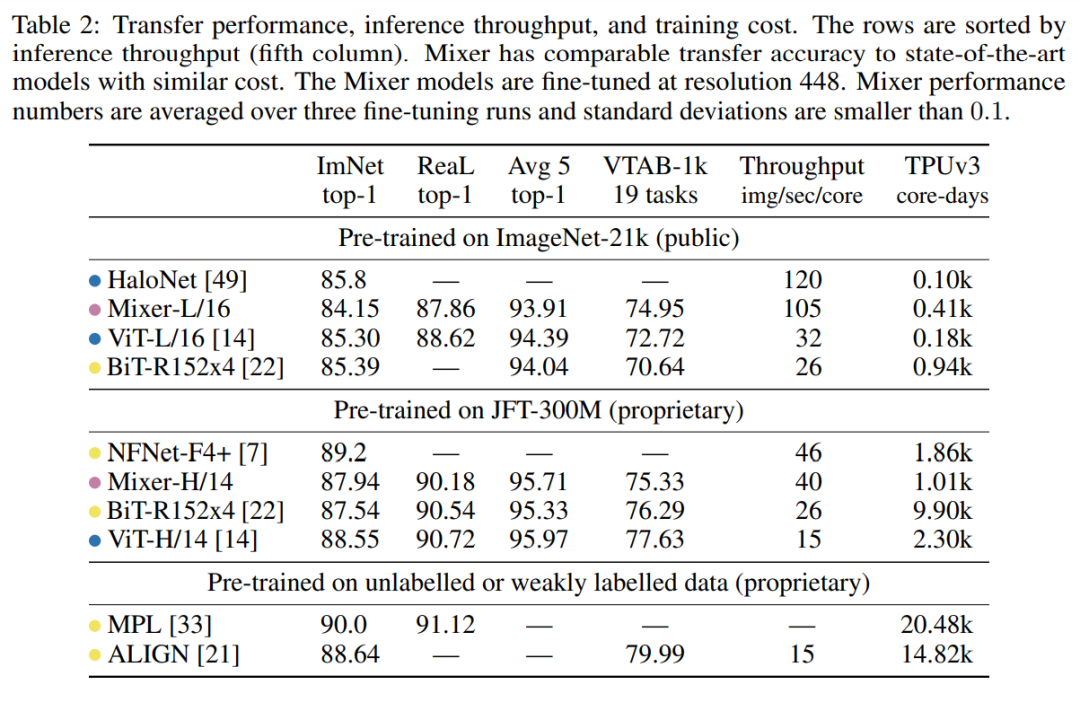
Mixer在不同的数据集上pre-training后迁移到其它任务时,其性能与ViT等其它模型对比如下,可以看到Mixer均可以接近SOTA,而且模型inference time也基本类似。
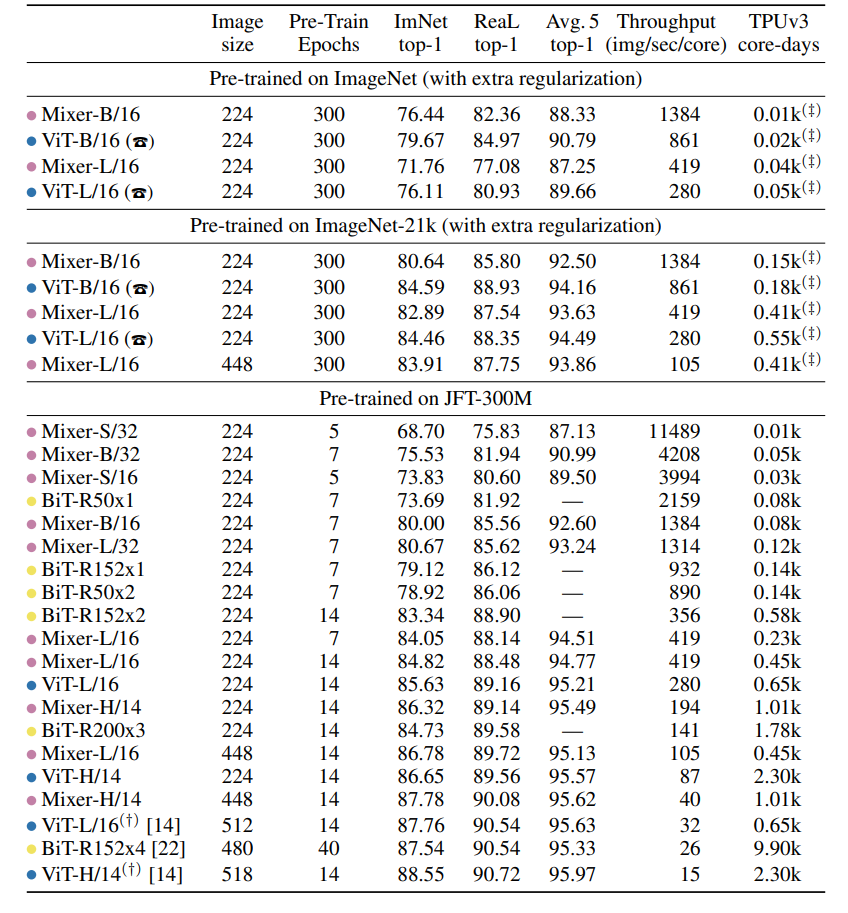
但是这都是需要在比较大的数据集比如ImageNet-21K和JFT-300上进行pre-training,当Mixer训练数据不足时,Mixer容易过拟合,其效果要差于CNN和ViT,下表是不同设置的Mixer与其他模型的对比,比如在ImageNet上训练的话,Mixer-B/16性能就低于ViT-B/16。
关于Mixer,有人觉得它其实是包含卷积的,比如LeCun大佬就发声了:1st layer "Per-patch fully-connected" == "conv layer with 16x16 kernels and 16x16 stride" , other layers "MLP-Mixer" == "conv layer with 1x1 kernels"。其实这个是从实现的角度来看这个的,但是只有1x1的卷积层还能算的上是CNN吗?其实论文也从另外一个角度说明了Mixer和CNN的联系:channel mixing MLP等价于1x1卷积,token-mixing MLP 等价于一个kernel size为image size的single-channel depth-wise convolutions,但是这里parameter
sharing for token mixing(这里就是, separable convolution,但是conv一般不同的channel会采用不同卷积核,而token-mixing MLP是所有channel的参数都是共享的)。
无独有偶,随后牛津大学也发布了一篇简单的论文:Do You Even Need Attention? A Stack of Feed-Forward Layers Does
Surprisingly Well on ImageNet,其提出的模型结构其实是和Mixer一样,只不过论文里用FFN,而不是MLP,而且实验没有Google的充分:

论文里面也有一小段对这种网络的描述,其实和我们上述所述基本一致:

不论是ViT,或者CNN-ResNet,还是这里的MLP-Mixer,其实最本质的一点,就是它们都是residual net,或许这才是最重要的。
最后不得不说,Google可能又开了一个新坑,可能滋养一大批paper,参考ViT。
推荐阅读
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
