刷新记录! CVPR2021全新目标检测机制达到SOTA!
随着注意力机制在自然语言处理和计算机视觉等多个人工智能领域风靡,计算机视觉领域刷榜之争可谓是进入白热化阶段。
近期大量工作刷新现有各项任务SOTA:前脚谷歌刚在图像识别ImageNet上准确度超过90,紧接着微软又在目标检测COCO上AP超过60。
在一篇CVPR 2021 论文中,来自微软的研究者提出多重注意力机制统一目标检测头方法Dynamic Head, 可插拔特性提高多种目标检测框架的性能。
在Transformer骨干和额外数据加持下,COCO单模型测试取得新纪录:60.6 AP。

论文地址:https://arxiv.org/abs/2106.08322
方法概述
本文首先对现有目标检测头的改进工作进行了总结,发现近期方法主要通过三个不同的角度出发进行目标检测性能的提升:
尺度感知:目标尺度的差异对应了不同尺度的特征,改进不同级的表达能力可以有效提升目标检测器的尺度感知能力;
空间位置:不相似目标形状的不同几何变换对应了特征的不同空间位置,改进不同空间位置的表达能力可以有效提升目标检测器的空间位置感知能力;
多任务:目标表达与任务的多样性对应了不同通道特征,改进不同通道的表达能力可以有效提升目标检测的任务感知能力。
本文提出一种新颖的动态头框架,它采用多注意力机制将不同的目标检测头进行统一。
通过特征层次之间的注意力机制用于尺度感知,空间位置之间的注意力机制用于空间感知,输出通道内的注意力机制用于任务感知,该方法可以在不增加计算量的情况显著提升模型目标检测头的表达能力。
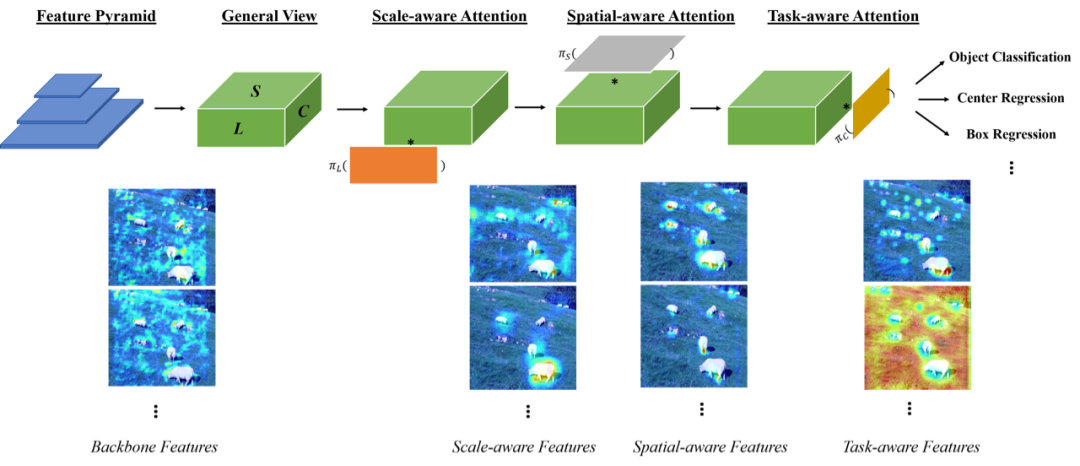
为了达成以上目的,本文对特征金字塔进行重构,将不同层级的特征统一到一个3D张量,并发现在不同维度引入注意力机制可以提高对尺度,空间位置和多任务的感知能力。
因此上述方向可以统一到一个高效注意力学习问题中。本文也是首个尝试采用多注意力机制将三个维度组合构建统一头并最大化其性能的工作。
作者将注意力函数转换为三个序列子注意力函数来解决传统注意力函数在高维度导致计算量激增的问题。
每个注意力函数仅聚焦一个维度:基于SE模块的尺度自注意函数π_L, 基于可变形卷积的空间自注意函数π_S 和 基于动态ReLU激活函数的多任务的自注意函数π_C。
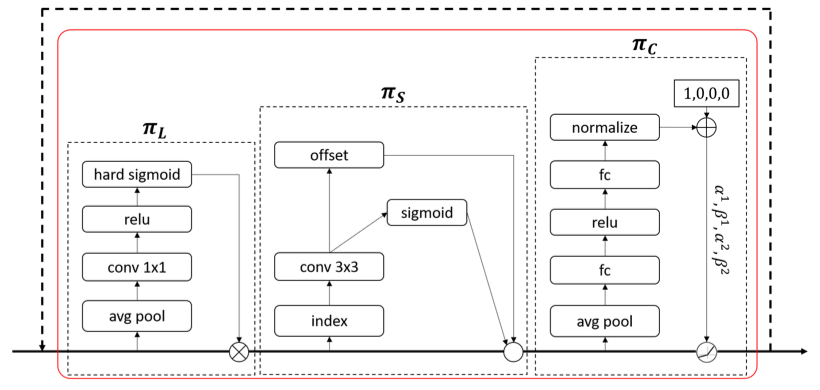
作者将三种自注意函数进行堆叠,形成一个可轻易插拔的模块DyHead,并将其应用于多种目标检测框架中。
实验结果
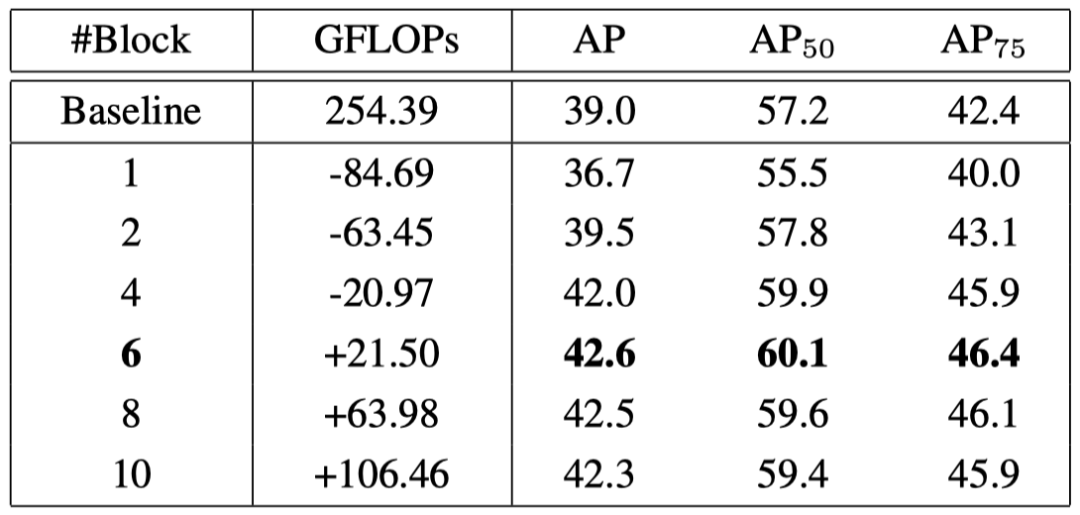
作者首先分析了的计算效率。当采用6个模块时,模型性能提升达到最大,而计算量提升相比骨干网络可以忽略。
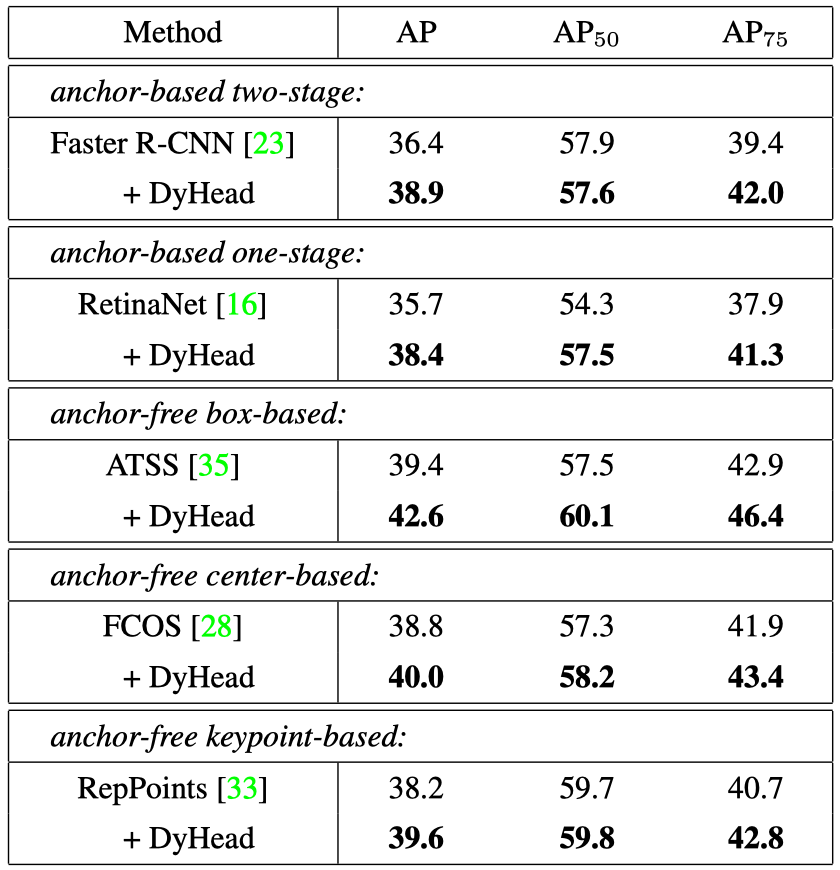
作者将DyHead集成到不同检测器进行性能对比,发现所提DyHead可以一致性提升所有主流目标检测器性能:1.2~3.2AP,展示了优异的可插拔扩展性能。
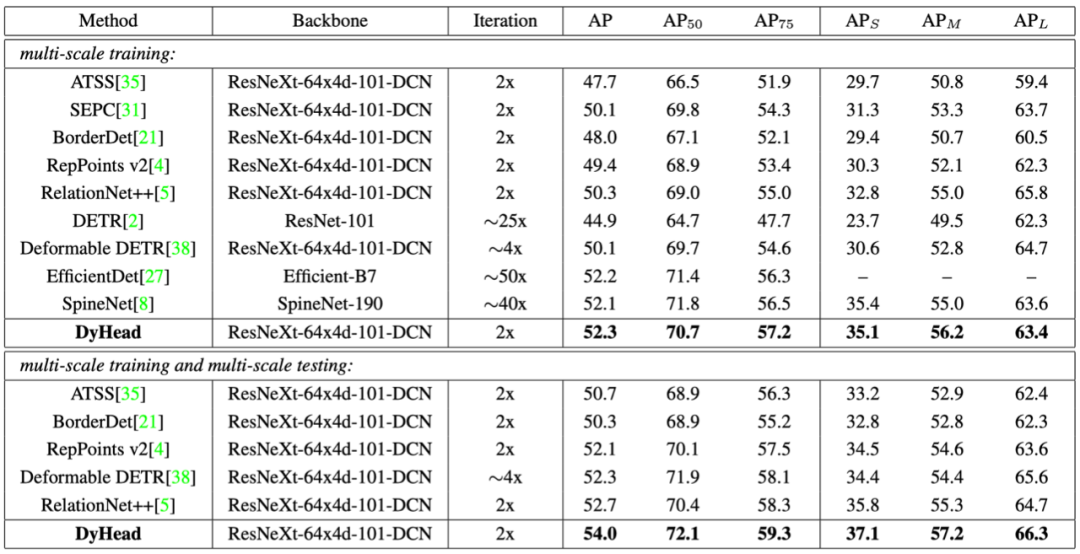
在与其他目标检测方法的对比中,所提方案以较大的优势超越了流行方案。相比仅采用多尺度寻览的方法,所提方案仅需2x训练即可取得新的SOTA指标 52.3AP。相对于谷歌提出的EfficientDet与SpineNet,所提方法训练时间更少(仅1/20);
当同时采用多尺度训练与测试时,所提方法取得了新的SOTA指标54.0AP,以1.3AP指标优于此前最佳。
当引入更优异的Transformer骨干网络、以及通过类似于谷歌自我学习方法生成的额外伪框的ImageNet数据后,所提方案取得了COCO新的记录:60.6 AP,成为首个超过60的单模型方法。

感兴趣的读者可以阅读原文,了解更多研究细节。
论文:
https://arxiv.org/abs/2106.08322
代码:
https: //github.com/microsoft/DynamicHead
-------------------
END
--------------------
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。