
【机器学习】使用 IQR、Z 分数、LOF 和 DBSCAN 检测异常值
作者 | SHAILESH SHUKLA 编译 | Flin 来源 | analyticsvidhya
作者 | SHAILESH SHUKLA 编译 | Flin 来源 | analyticsvidhya
介绍
你在处理异常值吗?哪种方法更适合检测偏斜或正态分布数据的异常值?
伙计们,无论你是在执行 EDA 之前进行数据清理过程,将数据传递给机器学习模型,还是执行任何统计测试,本文都将帮助你获得许多此类问题的答案以及实际应用。
什么是Inliers和Outliers?
Outliers(异常值)是看起来与给定数据集中的大多数其他值有很大差异的值。异常值通常可能是由于新发明(真正的异常值)、新模式/现象的发展、实验错误、很少发生的事件、异常、由于排版错误导致的错误输入数据、数据记录系统/组件故障等而出现的。
Inliers(正常值)是除异常值之外的分布中的所有数据点。
异常值的识别
全局或点异常值: 偏离分布的单个值/数据点,大多数异常值检测方法通常旨在检测点/全局异常值。
集合异常值:当一组数据点偏离分布时,称为集合异常值。根据特定领域来解释它们的相关性是完全主观的。此外,集合异常值表明新现象或发展的形成。
上下文异常值:这些是基于对其相关性的解释的特定条件,例如语音识别技术中的单一背景噪声。
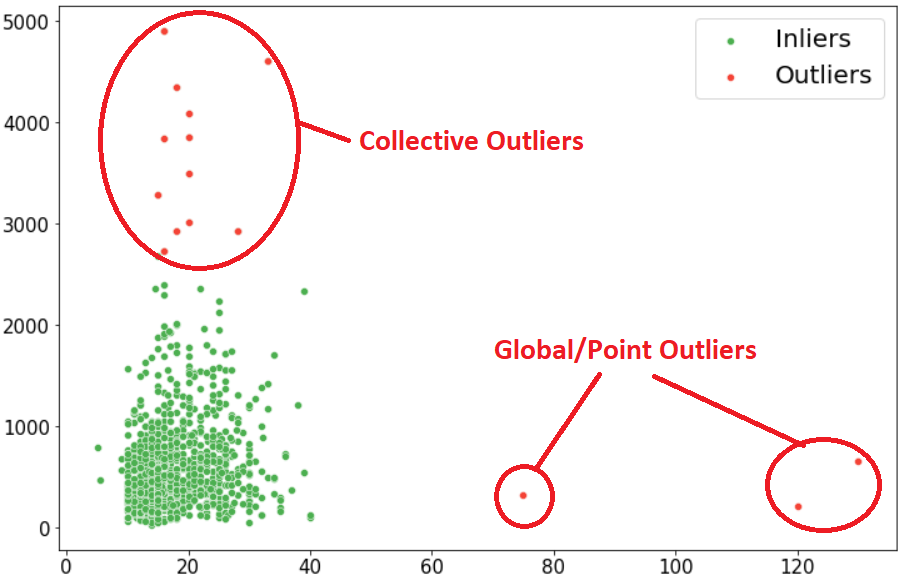
图1:点/全局或集体异常值
为了便于理解,我举了一个例子:关于三年内废钢销售的真实案例研究。
离群值的真实案例
考虑到 2018 年至 2022 年在印度各地销售的钢板废品率 (Rs/Kg) 的真实情况,我们已捕获以了解统计数据并预测未来的价格。尽管如此,在此之前,作为数据清理过程的一部分,我们希望了解异常值的存在及其相应的权重。
导入重要库以加载数据集并进行进一步分析:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as st
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
df=pdf.read_excel("scrap_data.xlsx", skiprows=2)
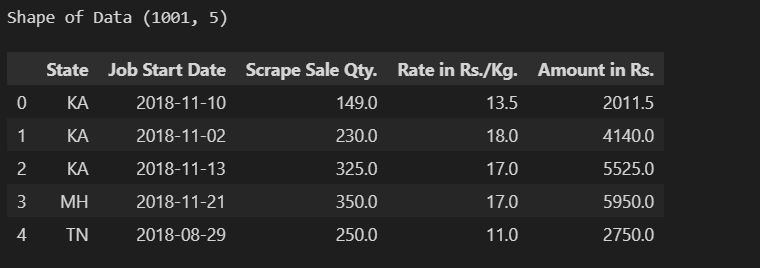
df.head(), print('shape of data:',df.shape)
为了了解趋势,我尝试在两个主要的自变量(‘Scrap Rate’ and ‘Scrap Weight’)上绘制线图,并参考其销售日期。
plt.figure(figsize =(15,5))
plt.subplot(1,2,1)
sns.lineplot(x=df['Job Start Date'], y=df['Rate in Rs./Kg.'], color='r')
plt.title("Steel Scrap Rate (Rs/Kg)", fontsize=20)
plt.xlabel('Date')
plt.subplot(1,2,2)
sns.lineplot(x=df['Job Start Date'], y=df['Scrape Sale Qty.'], color='b')
plt.title("Steel Scrap Weight (Rs/Kg)", fontsize=20)
plt.xlabel('Date')
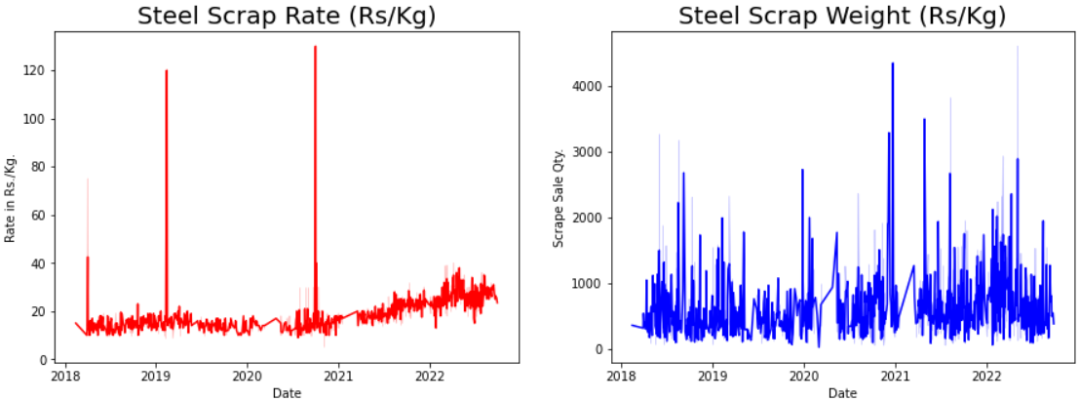
从废品率特征的趋势来看,我们了解到超过 120 Rs/kg 的费率突然飙升,这表明了异常情况的产生,因为一般来说,废品率必须相同并且逐渐增加或减少。但是,就废品重量而言,根据建设项目的规模,在项目结束时产生的废品量随时可能高或低。
让我们尝试应用检测和处理异常值的不同方法。
四分位间距 (IQR)
IQR 通过将数据集分成四个相等的四分位数来测量变异性。首先,将整个数据按升序排序,然后将其分成四个相等的四分位数,分别称为 Q1、Q2、Q3 和 Q4,可以使用以下等式计算。当数据形成偏态分布时,IQR 方法最适合。
第一个四分位数 (Q1) 将最小的 25% 的值与其他 75% 的较大值相除。
Q1 = (n+1)/4 排名值(第 25 个百分位)
第三分位数 (Q3) 将最小的 75% 与最大的 25% 相除。
Q3 = 3(n+1)/4 排名值(第 75 个百分位)
IQR(分位数范围)= Q3– Q1
下限 = Q1 – 1.5 x IQR
上限 = Q3 + 1.5 x IQR
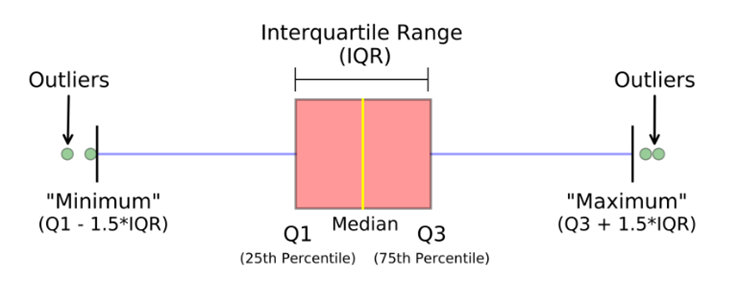
因此,可以将异常值视为给定数据集中大于上限 (Q3+1.5*IQR) 且小于下限 (Q1-1.5*IQR) 的任何值。
让我们绘制箱线图以了解异常值的存在;
plt.figure(figsize=(15,5))
plt.subplot(1,2,1)
sns.boxplot(df['Scrape Sale Qty.'])
plt.xticks(fontsize = (12))
plt.xlabel('Steel-Scrap Weight (in Kgs)')
plt.legend (title="Steel Scrap Weight", fontsize=10, title_fontsize=15)
plt.subplot(1,2,2)
sns.boxplot(df['Rate in Rs./Kg.'])
plt.xlabel('Steel Scrap Rate Rs/kg')
plt.xticks(fontsize =(12));
plt.legend (title="Steel Scrap Rate", fontsize=10, title_fontsize=15);
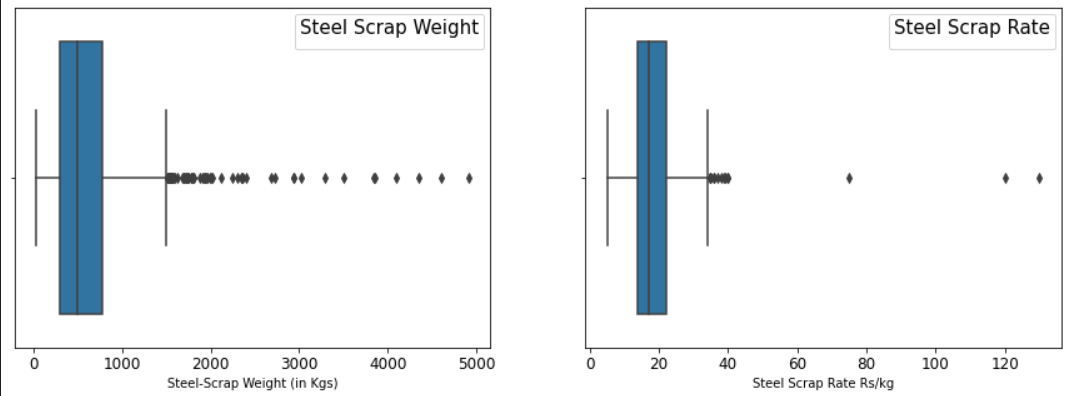
为了使计算更快,我创建了一个函数来导出四分位数范围 (IQR)、下限和上限,并添加了分别删除它们或用上限值或下限值填充它们的条件。
def identifying_treating_outliers(df,col,remove_or_fill_with_quartile):
q1=df[col].quantile(0.25)
q3=df[col].quantile(0.75)
iqr=q3-q1
lower_fence=q1-1.5*(iqr)
upper_fence=q3+1.5*(iqr)
print('Lower Fence;', lower_fence)
print('Upper Fence:', upper_fence)
print('Total number of outliers are left:', df[df[col] upper_fence].shape[0])
if remove_or_fill_with_quartile=="drop":
df.drop(df.loc[df[col]<lower_fence].index,inplace=True)
df.drop(df.loc[df[col]>upper_fence].index,inplace=True)
elif remove_or_fill_with_quartile=="fill":
df[col] = np.where(df[col] < lower_fence, lower_fence, df[col])
df[col] = np.where(df[col] > upper_fence, upper_fence, df[col])
将函数应用于 Scrap Rate 和 Scrap Weight 列:
identifying_treating_outliers(df,'Scrape Sale Qty.','drop')
identifying_treating_outliers(df,'Rate in Rs./Kg.','drop')
应用函数前的 DF 形状 : (1001, 5)
应用函数后的 DF 形状 : (925, 5)
在应用 'indentifying_treating_outliers' 函数后绘制箱线图以检查异常值的状态:
plt.figure(figsize=(15,5))
plt.subplot(1,2,1)
sns.boxplot(df['Scrape Sale Qty.'])
plt.xticks(fontsize = (12))
plt.xlabel('Steel-Scrap Weight (in Kgs)')
plt.legend (title="Steel Scrap Weight", fontsize=10, title_fontsize=15)
plt.subplot(1,2,2)
sns.boxplot(df['Rate in Rs./Kg.'])
plt.xlabel('Steel Scrap Rate Rs/kg')
plt.xticks(fontsize =(12));
plt.legend (title="Steel Scrap Rate", fontsize=10, title_fontsize=15);
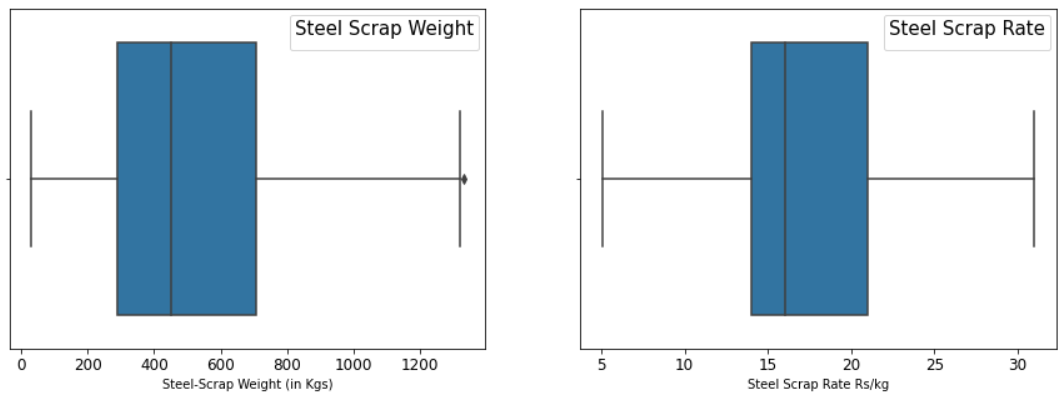
使用 IQR 方法,我们分别从废品率 (Rate > 34 Rs/kg) 和废品重量 (>1503 kg) 中删除了 15 个数据点和 65 个数据点。删除的观察总数为 76。
Z 分数法
值的 Z 分数是该值与平均值之间的差值除以标准差。如果特定数据点的 Z 分数值小于 -3 或大于 +3,则 Z 分数有助于通过值识别异常值。Z 分数可以在数学上表示为;
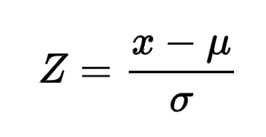
x=特定值, μ=平均值, σ=标准偏差
下图表示使用 Z 分数将数据从正态分布转换为标准正态分布,此处给出了参考文献。
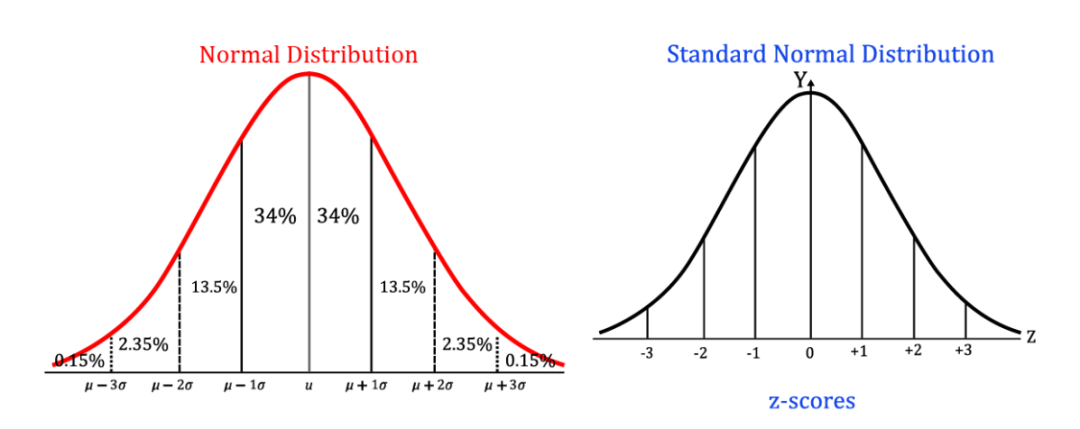
在我们的数据集中,我们将对 Zscore 大于 +3 且小于 -3 的异常值应用 Zscore。只需几行代码就可以帮助我们获得 Zscore,我们可以使用分布图(之前和之后)看到差异。
# Applying Zscore in Scrap Rate column defining dataframe by dfn
zr = st.zscore(df['Rate in Rs./Kg.'])
dfn = df[(zr-3)]
# Applying Zscore in Steel Weight Column defining dataframe by dfnf
zw= st.zscore(dfn['Scrape Sale Qty.'])
dfnf = dfn[(zw-3)]
plt.figure(figsize=(12,5))
plt.subplot(1,2,1)
sns.distplot(df['Rate in Rs./Kg.'])
plt.title('Z Score Plot Before Removing Outlier',fontsize=15)
plt.subplot(1,2,2)
sns.distplot(st.zscore(dfn['Rate in Rs./Kg.']))
plt.title('Z Score Plot After Removing Outlier',fontsize=15)
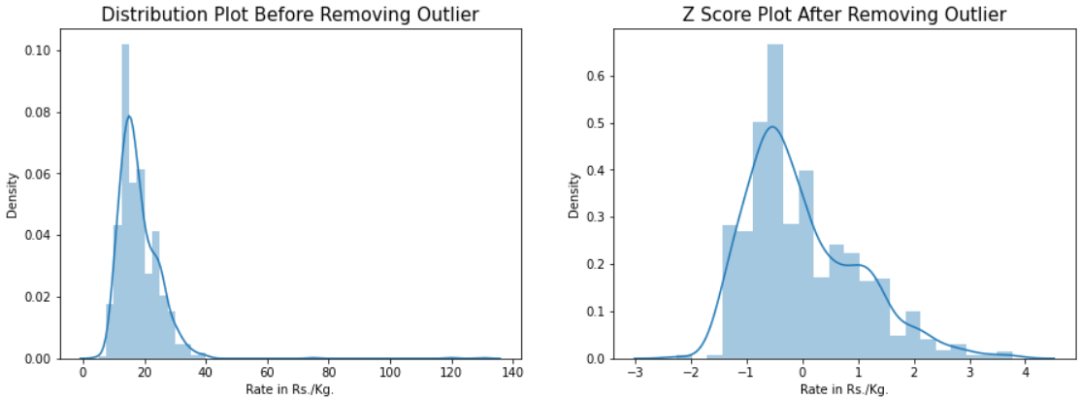
我们的数据形成了一个正偏态分布(偏度值 - 0.874),在上述曲线中,该分布不能被视为近似正态分布。对比应用Zscore前后显示的曲线图,可以看到显著的改善。
print('before df shape', df.shape)
print('After df shape for Observation dropped in Scrap Rate', dfn.shape)
print('After df shape for observation dropped in weight', dfnf.shape)

使用 Z Score 方法,在 Scrap Rate 和 Scrap Weight 列中,我们删除了 Zscore -3 的 21 个数据点(3 个来自 Scrap Rate列,18 个来自 Scrap Weight列)。
局部异常值查找器 (LOF)
Local Outlier Finder 是一种无监督机器学习技术,用于根据数据点的最近邻域密度检测异常值,并且在数据集的分布(密度)不同时效果很好。LOF 基本上考虑了 K 距离(点之间的距离)和 K 邻居(点集位于 K 距离(半径)的圆内)。
Lof 考虑了两个主要参数:
(1) n_neighbors:默认值为 20 的邻居数
(2) Contamination:给定数据集中异常值的比例,可以设置为“auto”或浮点值 (0, 0.02 , 0.005)。
导入重要库并定义模型
from sklearn.neighbors import LocalOutlierFactor
d2 = df.values #converting the df into numpy array
lof = LocalOutlierFactor(n_neighbors=20, contamination='auto')
good = lof.fit_predict(d2) == 1
plt.figure(figsize=(10,5))
plt.scatter(d2[good, 1], d2[good, 0], s=2, label="Inliers", color="#4CAF50")
plt.scatter(d2[~good, 1], d2[~good, 0], s=8, label="Outliers", color="#F44336")
plt.title('Outlier Detection using Local Outlier Factor', fontsize=20)
plt.legend (fontsize=15, title_fontsize=15)
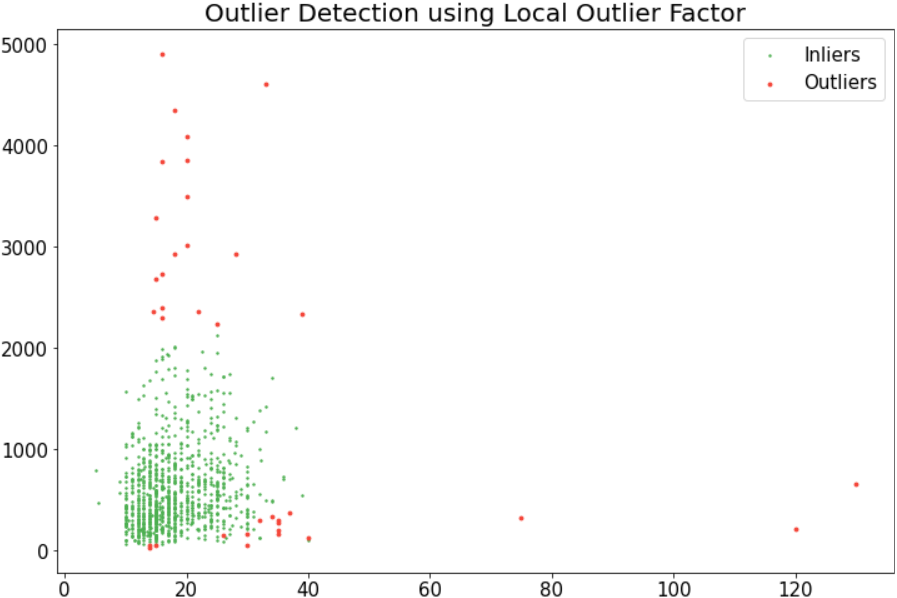
在我们的例子中,我将污染设置为“auto”(参见上图)以查看结果,发现 LOF 的性能不佳,因为我的数据传播(密度)没有太大偏差。此外,我尝试了 0.005、0.01、0.02、0.05 和 0.09 的不同污染值,但性能并不是那么好。
用于噪声应用的基于密度的空间聚类 (DBSCAN)
当我们的数据集足够大并且具有多个数字特征(多变量)时,使用 IQR、Zscore 或 LOF 处理异常值变得很困难。在这里,SK-Learn 库 DBSCAN 可以帮助我们处理多变量数据集的异常值。
DBSCAN 考虑两个主要参数(如下所述)与最近的数据点形成一个集群,并根据高密度或低密度区域检测 Inliers 或 outliers。
(1) Epsilon(我们可以根据k-距离图计算的数据点的半径)
(2) Min_samples(Epsilon(半径)中要考虑的数据点数量,取决于领域知识或专家建议)
然而,在我们的例子中,我们没有超过 5 个特征,我们只是从中选择了两个重要的数字特征来应用我们的学习并对其进行可视化。由于目前技术和人脑在完全可视化多维数据方面的限制,我们正在将 DBSCAN 应用于我们的数据集。
导入库并拟合模型。为了消除数据集中的噪声,我们使用 Min-Max Scaler 对数据进行了归一化。
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
df[['Scrape Sale Qty.','Rate in Rs./Kg.']] = mms.fit_transform(df[['Scrape Sale Qty.','Rate in Rs./Kg.']])
df.head()
from sklearn.neighbors import NearestNeighbors
neigh = NearestNeighbors(n_neighbors=2)
nbrs = neigh.fit(df[['Scrape Sale Qty.', 'Rate in Rs./Kg.']])
distances, indices = nbrs.kneighbors(df[['Rate in Rs./Kg.', 'Rate in Rs./Kg.']])
# Plotting K-distance Graph
distances = np.sort(distances, axis=0)
distances = distances[:,1]
plt.figure(figsize=(8,5))
plt.plot(distances)
plt.title('K-distance Graph',fontsize=20)
plt.xlabel('Data Points sorted by distance',fontsize=14)
plt.ylabel('Epsilon',fontsize=14)
plt.show()
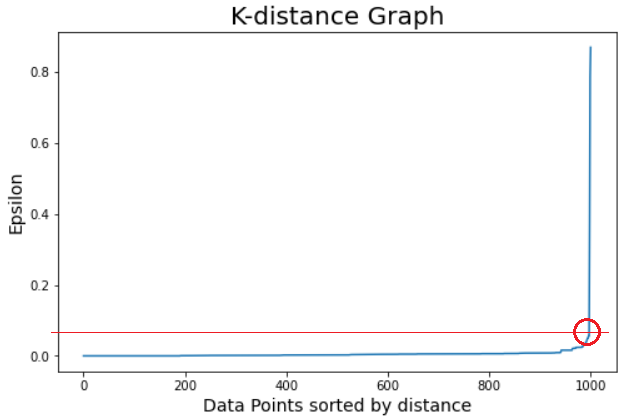
上图显示最大 Epsilon 值接近 0.08,对于样本量(我们希望在每个数据点的 epsilon 值内的点数),我们现在选择 10。
model = DBSCAN(eps = 0.08, min_samples = 10).fit(data)
colors = model.labels_
plt.figure(figsize=(10,7))
plt.scatter(df['Rate in Rs./Kg.'], df['Scrape Sale Qty.'], c = colors)
plt.title('Outliers Detection using DBSCAN',fontsize=20)
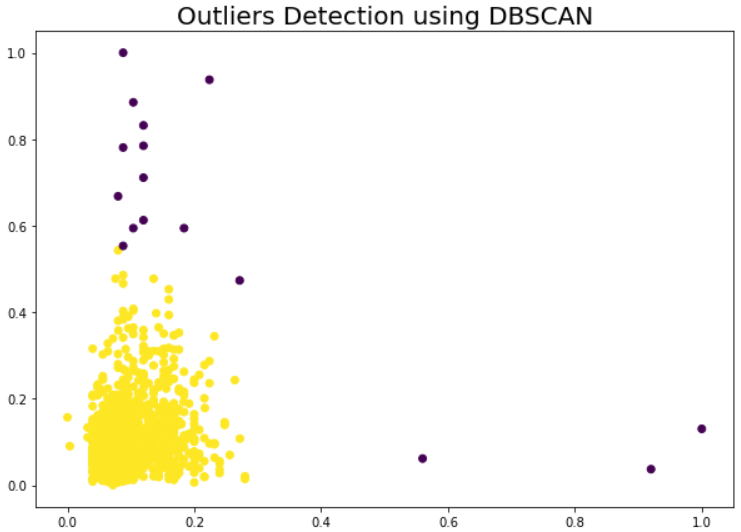
DBSCAN 技术使用基于密度的空间聚类有效地检测了显着的异常值,如下图所示。
结论
在这里,我们经历了从数据集中检测异常值的四种方法,在真实世界数据集上找到了它们的实现,并观察了不同的结果。然而,这些方法的应用还取决于数据集的大小、分布和上下文(单变量、双变量或多变量)。所有这些技术都有一定的优点和缺点。
IQR是最简单和最能用数学解释的技术。单变量和双变量数据可以很好地识别异常值,因为它将中值视为离散值的度量来检测极值,但在处理大量数字特征时仅限于多变量数据集。
在我们的案例中,我们通过定义一个检测和处理异常值的函数来应用它,并将 76 个丢弃的数据点检测为异常值。
Zscore 衡量原始数据与标准差单位中的平均值的距离,并且比其在正态分布数据集中的应用具有优势,但是当数据集不对称(左偏或右偏)时,Zscore 技术可能会导致错误的结果.
我们将其应用于我们的数据集,该数据集似乎略微偏斜,并检测到 21 个数据点作为潜在的异常值。
LOF(局部Ourliter Factor)在数据分布(密度)在整个空间中分布不均匀时具有优势,因为它根据与其他全局方法难以识别的邻近密集区域的接近程度来识别异常值。
然而,可解释性是一个问题,因为很难说在什么阈值下数据点可以被视为异常值。
DBSCAN 不需要定义多个集群,并且能够检测数据分布任意分布且线性不可分的异常。在处理不同密度的数据传播时,它有其自身的局限性。在我们的案例中,它检测到 16 个数据点作为潜在的异常值。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码