
这个预训练不简单!BLIP:统一视觉-语言理解和生成任务
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
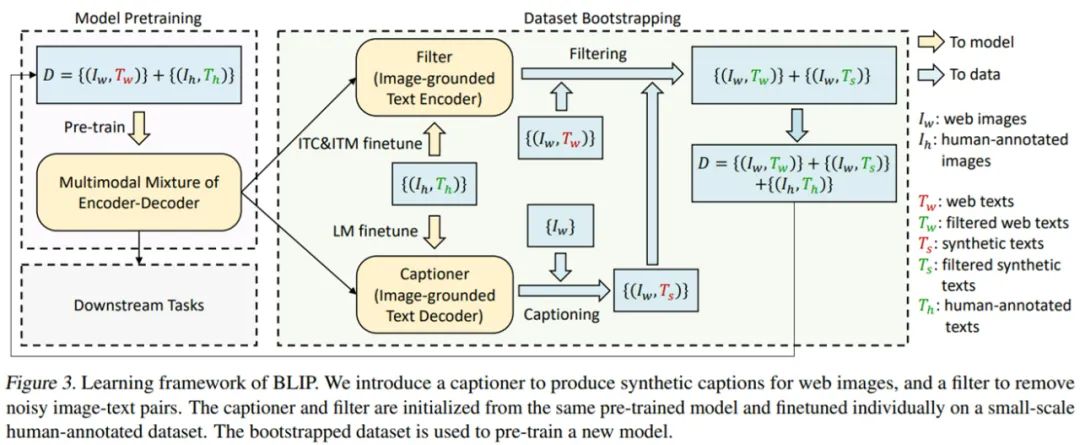
这个 BLIP 模型可以「看图说话」,提取图像的主要内容,不仅如此,它还能回答你提出的关于图像的问题。

论文地址:https://arxiv.org/pdf/2201.12086.pdf
代码地址:https://github.com/salesforce/BLIP
试玩地址:https://huggingface.co/spaces/akhaliq/BLIP
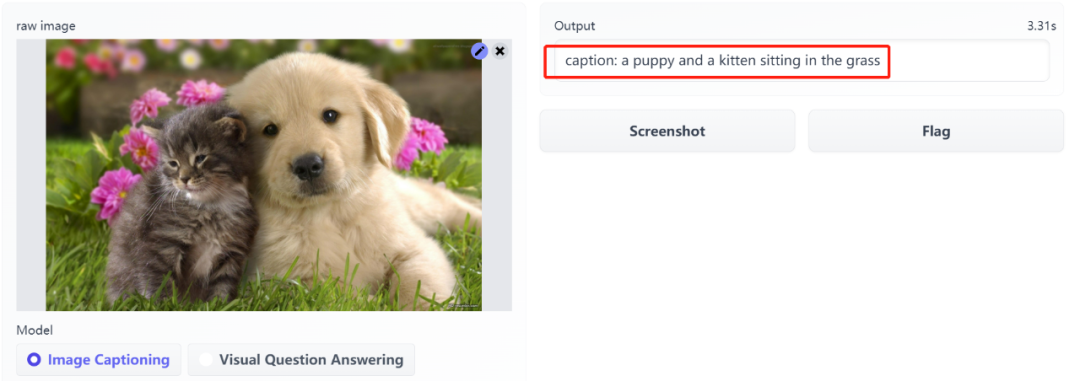
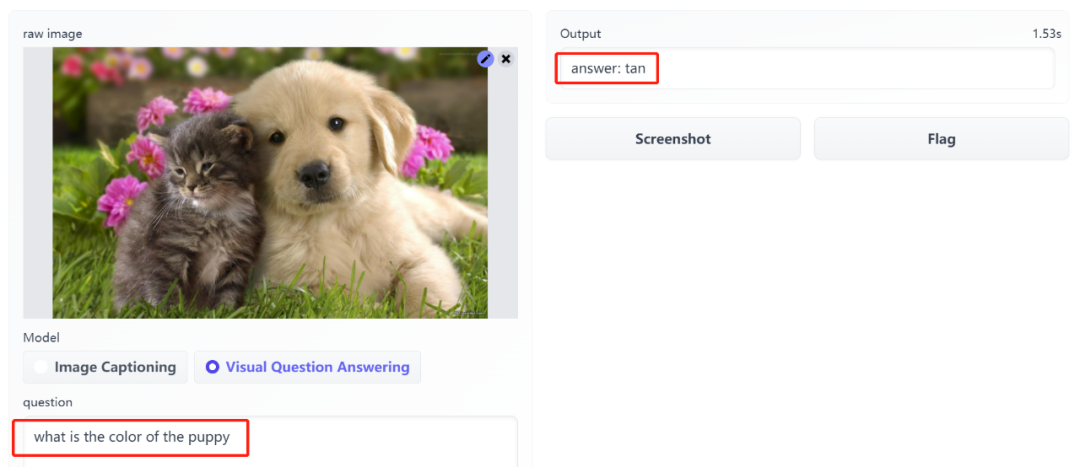
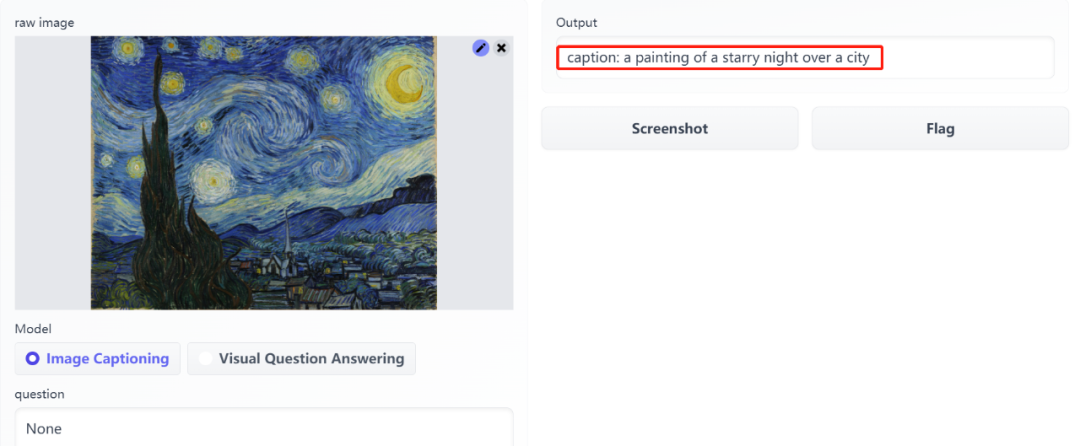
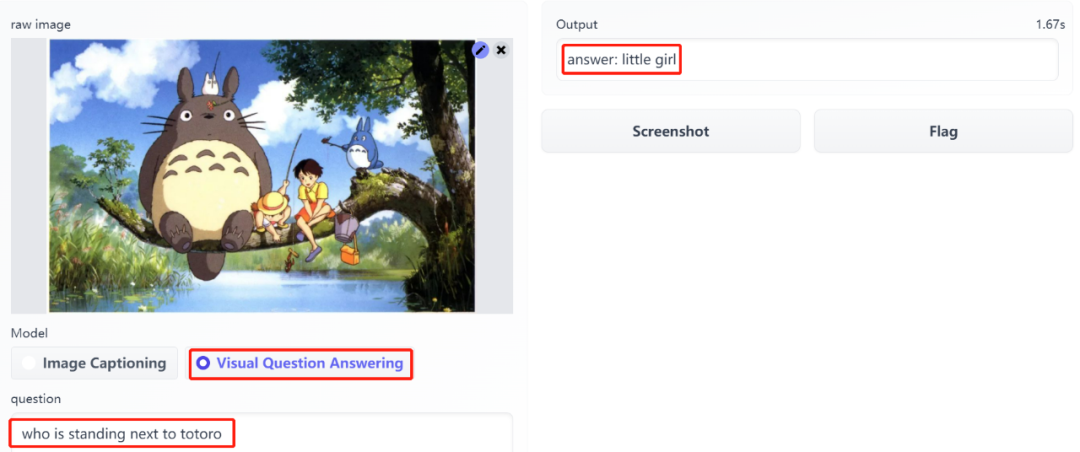
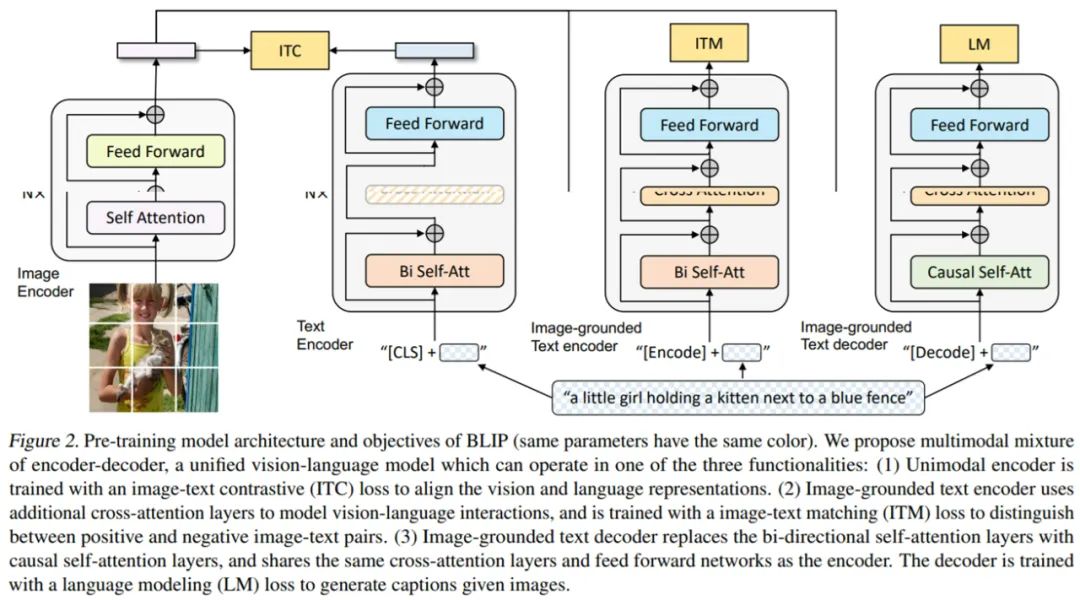

单峰编码器
基于图像的文本编码器
基于图像的文本解码器
图像文本对比损失(image-text contrastive loss, ITC),激活单峰编码器,旨在通过鼓励正图像文本对(而非负对)具有相似的表征来对齐视觉与文本 transformer 的特征空间;
图像文本匹配损失(image-text matching loss, ITM),激活基于图像的文本编码器,旨在学习捕获视觉与语言之间细粒度对齐的图像文本多模态表征;
语言建模损失(language modeling loss, LM),激活基于图像的文本解码器,旨在给定一张图像时生成文本描述。




评论