
完整教程:使用YOLO V5训练自动驾驶目标检测网络
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
来源:自动驾驶全栈工程师知乎专栏
https://www.zhihu.com/people/william.hyin/columns
前言:YOLO V5 网络结构分析及迁移学习应用
本文会详细介绍YOLO V5的网络结构及组成模块,并使用YOLO V5s在BDD100K自动驾驶数据集上进行迁移学习,搭建属于自己的自动驾驶交通物体对象识别网络。
YOLO 是一种快速紧凑的开源对象检测模型,与其它网络相比,同等尺寸下性能更强,并且具有很不错的稳定性,是第一个可以预测对象的类别和边界框的端对端神经网络。YOLO 家族一直有着旺盛的生命力,从YOLO V1一直到”V5“,如今已经延续五代,凭借着不断的创新和完善,一直被计算机视觉工程师作为对象检测的首选框架之一。
Ultralytics于5月27日发布了YOLOv5 的第一个正式版本,其性能与YOLO V4不相伯仲,是现今最先进的对象检测技术之一,并在推理速度上是目前最强。
我在前一篇文章《一文读懂YOLO V5 与 YOLO V4》中介绍了YOLO V5和YOLO V4的原理、相似点及区别。
在本文章中,我会详细介绍YOLO V5的网络结构及组成模块,并使用YOLO V5s对BDD100K自动驾驶数据集进行迁移学习,使得训练出的模型能够识别包括交通灯颜色在内的所有交通对象。
本文分成两块:模型结构及迁移学习。
Model architecture
Overview Focus BottleneckCSP SPP PANET Transfer learning
Data prepration Setup enviorment Configuration Modify model architecture Transfer learning theory Inference
Model architecture
YOLO网络由三个主要组件组成:
1)Backbone:在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
2)Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
3)Head:对图像特征进行预测,生成边界框和并预测类别。
本文主要采用YOLO V5 1.0结构,7月23日作者更新了2.0版本代码,对于模型定义做了些改变,我会后续进行更新。
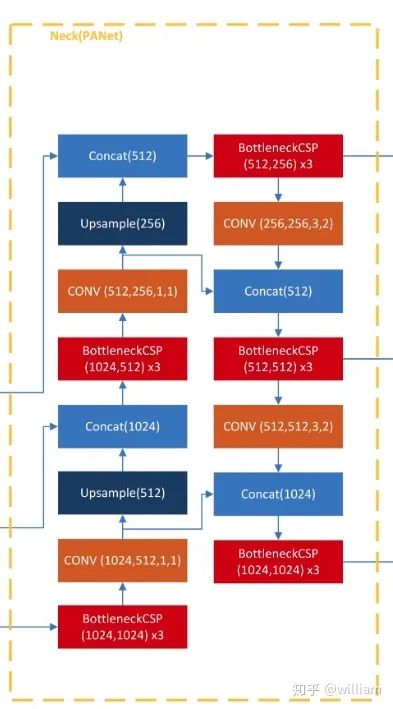
YOLO V5 1.0中用到的重要的模块包括Focus,BottleneckCSP,SPP,PANET。模型的上采样Upsample是采用nearst两倍上采样插值。值得注意的是YOLO V5 1.0最初为COCO数据集训练的Pretrained_model 使用的是FPN作为Neck,在6月22日后,Ultralytics已经更新模型的Neck为PANET。网上很多的YOLO V5网络结构介绍都是基于FPN-NECK,本文的模型训练是基于PANET-NECK,下文中只介绍PANET-NECK。
对于YOLO V5,无论是V5s,V5m,V5l还是V5x其Backbone,Neck和Head一致。唯一的区别在与模型的深度和宽度设置,只需要修改这两个参数就可以调整模型的网络结构。V5l 的参数是默认参数。
depth multiple是用来控制模型的深度,例如V5s的深度是0.33,而V5l的深度是1,也就是说V5l的Bottleneck个数是V5s的3倍。 width_multiple是用来控制卷积核的个数,V5s的宽度是0.5,而V5l的宽度是1,表示V5s的卷积核数量是默认设置的一半,当然你也可以设置到1.25倍,即V5x。例如下面YOLO V5的yaml文件中的backbone的第一层是 [[-1, 1, Focus, [64, 3]],而V5s的宽度是0.5,因此这一层实际上是[[-1, 1, Focus, [32, 3]]。from列参数:-1 代表是从上一层获得的输入,-2表示从上两层获得的输入(head同理)。 number列参数:1表示只有一个,3表示有三个相同的模块。
下图为YOLO V5 1.0的网络结构图(默认对应YOLO V5l),引用自Laughing-q。
下图中存在三种括号,其中 In_channel:输入通道,out_channel:输出通道,Kernel_size:卷积核大小,Stride:步长,x N代表此模块的叠加次数,方框外数字:depth x weight x height,默认输入为宽高为640x640的三通道图像。
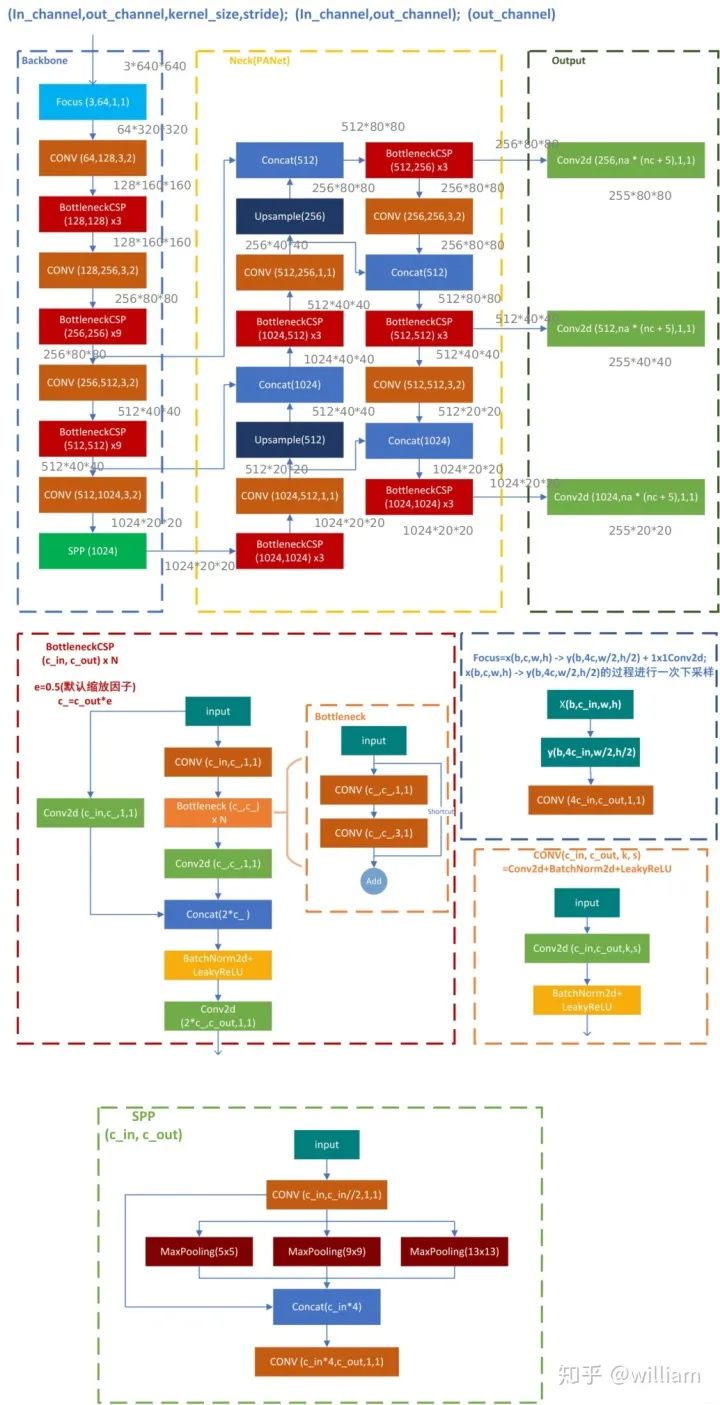
下文我将详细讲述Focus,BottleneckCSP,SPP,PANET这几个重要模块,由于本项目使用YOLO V5s网络结构训练模型,因此下文中的网络图及实例都基于YOLO V5s,并且输入图像为3x640x640。YOLO V5默认depth_multiple=0.33, width_multiple=0.50。即BottleneckCSP中Bottleneck的数量为默认的1/3,而所有卷积操作的卷积核个数均为默认的1/2。
Focus
下图为YOLO V5s的Focus 隔行采样拼接结构。
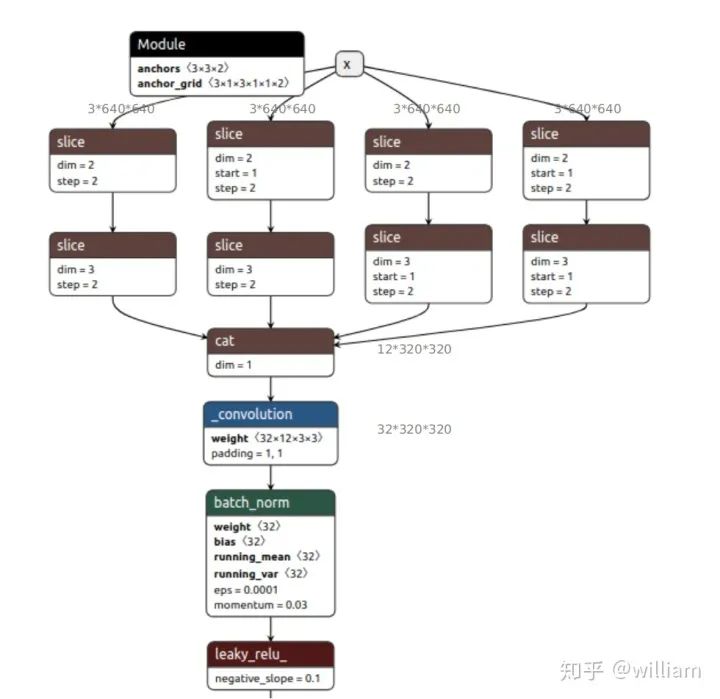
YOLO V5默认3x640x640的输入,复制四份,然后通过切片操作将这个四个图片切成了四个3x320x320的切片,接下来使用concat从深度上连接这四个切片,输出为12x320x320,之后再通过卷积核数为32的卷积层,生成32x320x320的输出,最后经过batch_borm 和leaky_relu将结果输入到下一个卷积层。
Focus的代码分析如下:
class Focus(nn.Module):# Focus wh information into c-spacedef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper(Focus, self).__init__()self.conv = Conv(c1 * 4, c2, k, s, p, g, act)def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))

我们拿上图举例,Focus是步长为2的隔行采样。
上图第一张图为原图,第二张图为Focus的特征图,第三张图为4x4的tensor代码测试。
核心为这段代码self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)) 。x[..., ::2, ::2]是黄色部分,x[..., 1::2, ::2],是红色部分,以此类推。对于x[..., ::2, ::2]其中第一个参数“..."代表深度,也就是说三个通道都要切,第二个和第三个代表不论是宽和高都是每隔一个采样。对于x[..., 1::2, ::2],1::2代表从列位置1开始,也就是每序号奇数列采样。蓝色,绿色的生成方式以此类推。最后用cat连接这些隔行采样图,生成通道数为12的特征图。
BottlenneckCSP
下图为YOLO V5s的第一个BottlenneckCSP结构。
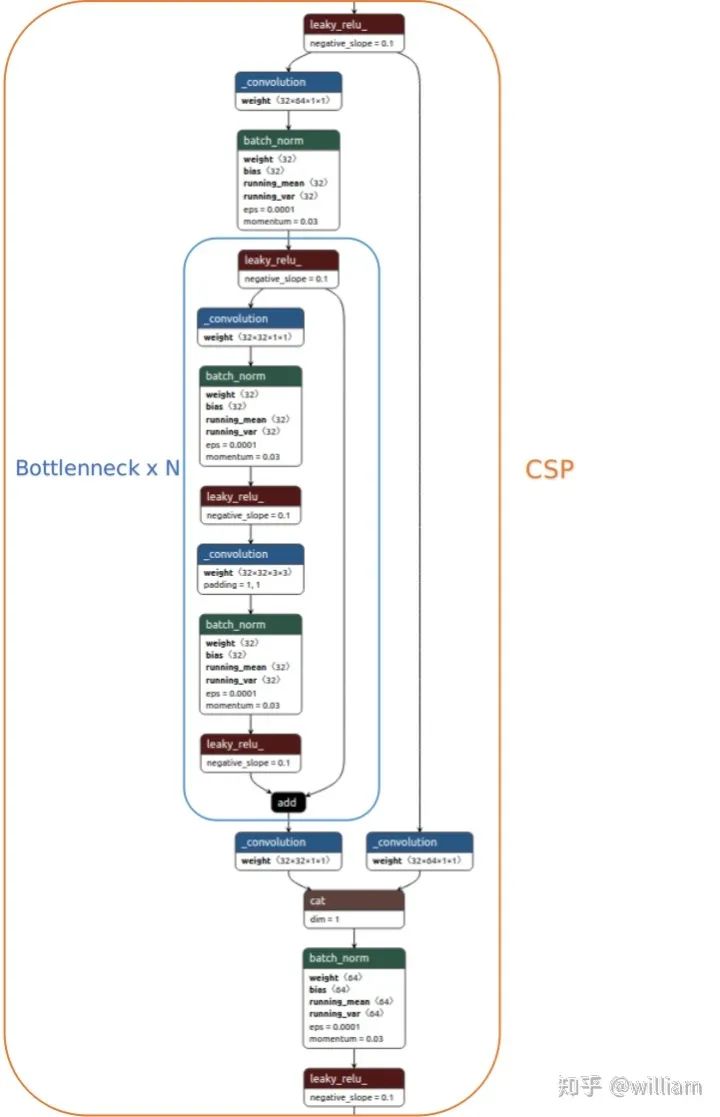
BottlenneckCSP分为两部分,Bottlenneck以及CSP。
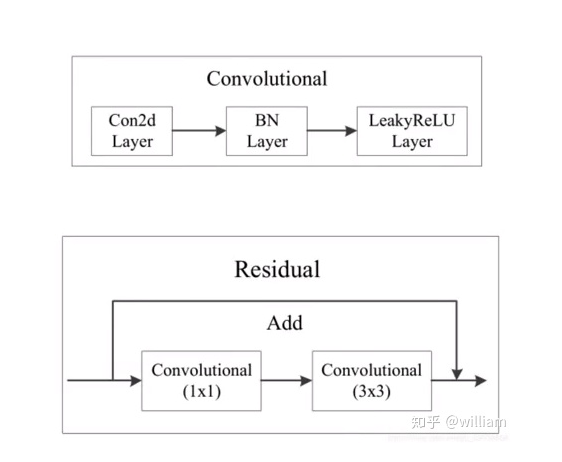
Bottlenneck
Bottlenneck其实就是经典的残差结构,先是1x1的卷积层(conv+batch_norm+leaky relu),然后再是3x3的卷积层,最后通过残差结构与初始输入相加。
值得注意的是YOLO V5通过depth multiple控制模型的深度,例如V5s的深度是0.33,而V5l的深度是1,也就是说V5x的BottlenneckCSP中Bottleneck个数是V5s的3倍,模型中第一个BottlenneckCSP默认Bottleneck个数x3,对于V5s只有上图中的一个Bottleneck。
作者的代码如下,值得注意的是e就是width_multiple,表示当前操作卷积核个数占默认个数的比例:
class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper(Bottleneck, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class BottleneckCSP(nn.Module):# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworksdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(BottleneckCSP, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)self.cv4 = Conv(2 * c_, c2, 1, 1)self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)self.act = nn.LeakyReLU(0.1, inplace=True)self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):y1 = self.cv3(self.m(self.cv1(x)))y2 = self.cv2(x)return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
CSP
下图为YOLO V5s的CSP结构,也就是说将原输入分成两个分支,分别进行卷积操作使得通道数减半,然后分支一进行Bottlenneck x N操作,随后concat分支一和分支二,从而使得BottlenneckCSP的输入与输出是一样的大小,目的是为了让模型学习到更多的特征。
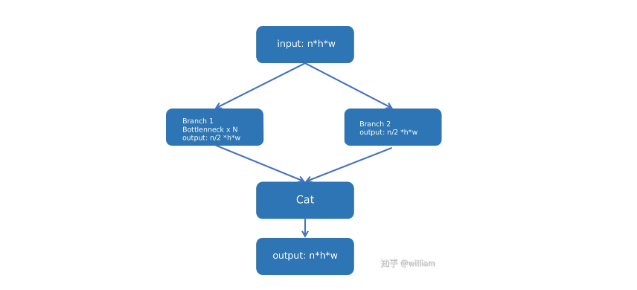
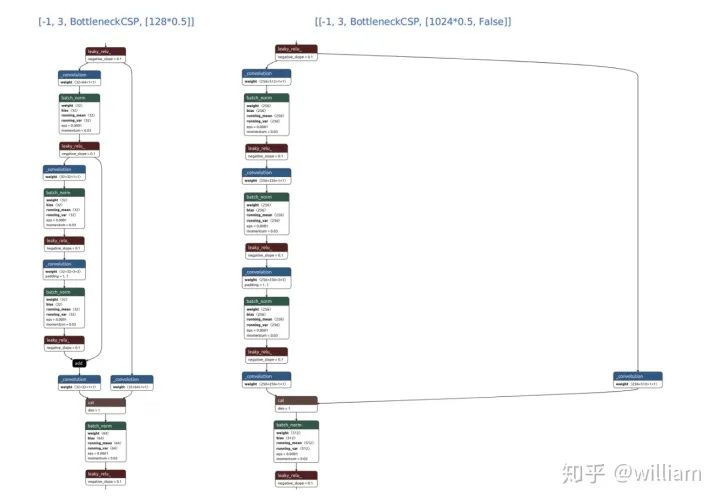
很多人都对yaml文件中[[-1, 3, BottleneckCSP, [1024, False]]False的作用不太理解,其实这就是关闭了shortcut的选项。
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5)
下图是YOLO V5s 中BottlenneckCSP有无False选项的结构对比:
SPP
下图为YOLO V5s的SPP结构。
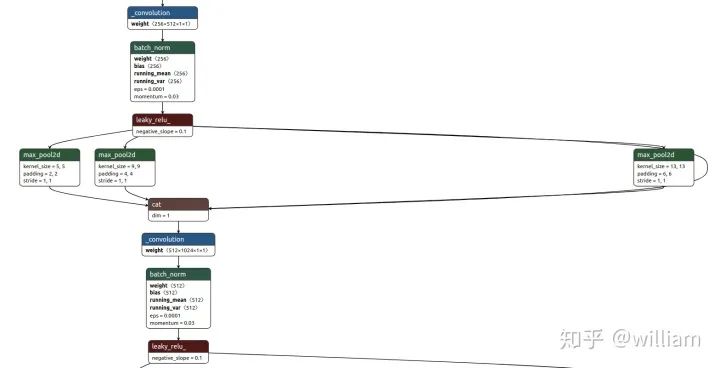
SPP的输入是512x20x20,经过1x1的卷积层后输出256x20x20,然后经过并列的三个Maxpool进行下采样,将结果与其初始特征相加,输出1024x20x20,最后用512的卷积核将其恢复到512x20x20。
作者代码如下,重点是Maxpool操作:
class SPP(nn.Module):# Spatial pyramid pooling layer used in YOLOv3-SPPdef __init__(self, c1, c2, k=(5, 9, 13)):super(SPP, self).__init__()c_ = c1 // 2 # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])def forward(self, x):x = self.cv1(x)return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
PANET
YOLO V5 1.0最初一版模型使用FPN作为NECK,后续在6月22号已经全面更新为PANET。PANET基于 Mask R-CNN 和 FPN 框架,加强了信息传播,具有准确保留空间信息的能力,这有助于对像素进行适当的定位以形成掩模。
下图中pi 代表 CSP 主干网络中的一个特征层
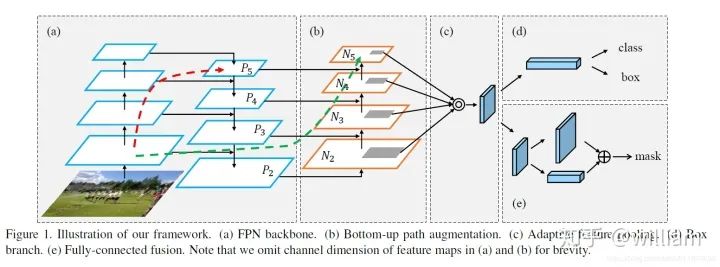
该网络的特征提取器采用了一种新的增强自下向上路径的 FPN 结构,改善了低层特征的传播(a部分)。第三条通路的每个阶段都将前一阶段的特征映射作为输入,并用3x3卷积层处理它们。输出通过横向连接被添加到自上而下通路的同一阶段特征图中,这些特征图为下一阶段提供信息(b部分)。横向连接,有助于缩短路径,被称为shortcut连接。同时使用自适应特征池化(Adaptive feature pooling)恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免被任意分配(c部分)。对于 Mask-RCNN(e部分),FCN可以保留空间信息并减少网络中的参数数量,但是由于参数是为所有空间位置共享的,因此该网路实际上并未学习如何使用像素位置进行预测。而FC对位置敏感,可以适应不同的空间位置。因此PANet使用来自**Fully Convolutional Network (FCN)和Fully-connected layers(FC)**的信息提供更准确的掩码预测。
YOLO V5借鉴了YOLO V4的修改版PANET结构。
PANET通常使用自适应特征池将相邻层加在一起,以进行掩模预测。但是,当在YOLOv4中使用PANET时,此方法略麻烦,因此,YOLO V4的作者没有使用自适应特征池添加相邻层,而是对其进行Concat操作,从而提高了预测的准确性。
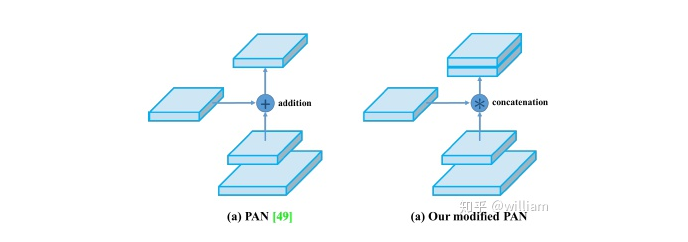
YOLO V5同样采用了级联操作。详情可以参看模型大图及Netron网络图中对应的Concat操作。
Transfer learning
在自定义数据集上训练YOLO V5,包括以下几个步骤:
Data Prepration
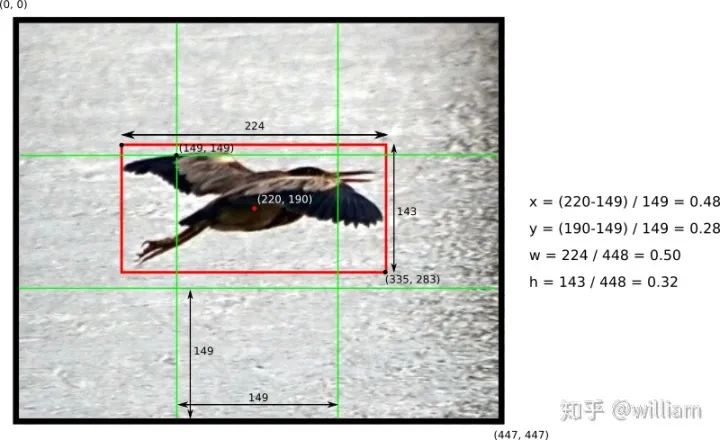
在准备数据集方面,最重要的是明白YOLO家族独特的标签数据集格式。
每个图片文件.jpg,都有同一命名的标签文件.txt。
标签文件中每个对象独占一行,格式为
其中:
例如: = / = / 注意:
如下图所示:
接下来我们要清楚YOLO V5的训练文件结构是什么。
YOLO V5的标签文件夹和图像文件夹应位于同一目录下。
其次自定义数据集应该分成Train,Valid, Test三个部分,比例可以按照7:2:1分配。由于BDD100k数据集已经为我们分好了Train,Valid, Test三部分,因此我们不需要自己分割数据集。
下图为YOLO V5的训练文件结构:

让我们来看看BDD100K数据集的概览。
BDD100K是最大的开放式驾驶视频数据集之一,其中包含10万个视频和10个任务,目的是方便评估自动驾驶图像识别算法的的进展。每个高分辨率视频一共40秒。该数据集包括超过1000个小时的驾驶数据,总共超过1亿帧。这些视频带有GPU / IMU数据以获取轨迹信息。该数据集具有地理,环境和天气多样性,从而能让模型能够识别多种场景,具备更多的泛化能力。这些丰富的户外场景和复杂的车辆运动使感知任务更具挑战性。该数据集上的任务包括图像标记,车道检测,可驾驶区域分割,道路对象检测,语义分割,实例分割,多对象检测跟踪,多对象分割跟踪,领域自适应和模仿学习。我们可以在BDD100K数据网站上下载数据。

Bdd100k的标签是由Scalabel生成的JSON格式。
- labels [ ]:- id: int32- category: string (classification)- manualShape: boolean (whether the shape of the label is created or modified manually)- manualAttributes: boolean (whether the attribute of the label is created or modified manually)- score: float (the confidence or some other ways of measuring the quality of the label.)- attributes:- occluded: boolean- truncated: boolean- trafficLightColor: "red|green|yellow|none"- areaType: "direct | alternative" (for driving area)- laneDirection: "parallel|vertical" (for lanes)- laneStyle: "solid | dashed" (for lanes)- laneTypes: (for lanes)- box2d:- x1: float- y1: float- x2: float- y2: float
道路对象类别包括以下几类:
["bike","bus","car","motor","person","rider","traffic light","traffic sign","train","truck"]
我们实际关注的只有- labels [ ]栏目下的内容。
现在我们可以开始转换Bdd100k的标签为YOLO 格式了。
Berkerley 提供了Bdd100k数据集的标签查看及标签格式转化工具。由于没有直接从bdd100k转换成YOLO的工具,因此我们首先得使用将bdd100k的标签转换为coco格式,然后再将coco格式转换为yolo格式。
bdd to coco
我的目的是识别包括不同颜色交通灯在内的所有交通对象,因此我们需要对原版的bdd2coco.py进行一些修改,以获取交通灯颜色并产生新的类别。
这是修改完的核心代码:
for label in i['labels']:annotation = dict()category=label['category']if (category == "traffic light"):color = label['attributes']['trafficLightColor']category = "tl_" + colorif category in id_dict.keys():empty_image = Falseannotation["iscrowd"] = 0annotation["image_id"] = image['id']x1 = label['box2d']['x1']y1 = label['box2d']['y1']x2 = label['box2d']['x2']y2 = label['box2d']['y2']annotation['bbox'] = [x1, y1, x2-x1, y2-y1]annotation['area'] = float((x2 - x1) * (y2 - y1))annotation['category_id'] = id_dict[category]annotation['ignore'] = 0annotation['id'] = label['id']annotation['segmentation'] = [[x1, y1, x1, y2, x2, y2, x2, y1]]annotations.append(annotation)
在完成bdd100k格式到yolo格式的转换后,会获得bdd100k_labels_images_det_coco_train.json和bdd100k_labels_images_det_coco_val.json两个文件。
Coco to yolo
在完成先前的转换之后,我们需要将训练集和验证集的coco格式标签转换为yolo格式。注意需要分别指定训练集和验证集图片位置,对应的coco标签文件位置,及生成yolo标签的目标位置。
config_train ={"datasets": "COCO","img_path": "bdd100k_images/bdd100k/images/100k/train","label": "labels/bdd100k_labels_images_det_coco_train.json","img_type": ".jpg","manipast_path": "./","output_path": "labels/trains/","cls_list": "bdd100k.names",}config_valid ={"datasets": "COCO","img_path": "bdd100k_images/bdd100k/images/100k/val","label": "labels/bdd100k_labels_images_det_coco_val.json","img_type": ".jpg","manipast_path": "./","output_path": "labels/valids/","cls_list": "bdd100k.names",}
除此之外,我们还得将所有的类别写入bdd100k.names文件。
personridercarbustruckbikemotortl_greentl_redtl_yellowtl_nonetraffic signtraintl_green
运行Bdd_preprocessing中的完整代码可以完成Bdd100k格式标签到YOLO标签格式的转换。
Bdd2coco以及coco2yolo的详细说明可以参看bdd100k代码库和convert2Yolo代码库。
Setup environment
运行YOLO V5的第一步是克隆YOLO V5的官方代码库。
YOLO V5 需要的Pytorch版本>=1.5, Python版本3.7, CUDA版本10.2。
Ultralytics提供了requirement.txt文件来方便新环境配置。
通过在shell中运行pip install \-r requirement.txt 命令,可以自动安装所有依赖项。
numpy==1.17scipy==1.4.1cudatoolkit==10.2.89opencv-pythontorch==1.5torchvision==0.6.0matplotlibpycocotoolstqdmpillowtensorboardpyyaml
Configuration
YOLO V5的默认YAML文件coco.yaml 中是coco数据集所有的类对象名称和类数量(80)。由于我们的目的是基于bdd100k数据集来训练检测少量特定交通物体的模型,我们不需要训练检测80类网络的模型,所有我们得重新创建一个uc_data.yaml文件来描述bdd100k数据集的数据特性。由于我们模型的输出不是coco数据集的80个类,而是13类,因此我们得修改此处的输出类别数量为13。
# here you need to specify the files train, test and validation txttrain: bdd100k/images/trainval: bdd100k/images/validtest: bdd100k/images/testnc: 13names: ['person','rider','car','bus','truck','bike','motor','tl_green','tl_red','tl_yellow','tl_none','t_sign','train']
之后我们会用到上述YAML文件来训练模型。
Modify Model arichtecture
YOLO V5通过models文件家中的cfg文件*.yaml来调整训练模型的结构。
由于我们模型的输出不是coco数据集的80个类,而是13类,因此我们需要修改模型的对象预测层输出类别数量为13。
# parametersnc: 13 # number of classes
我们可以直接修改YAML文件下各个组件的细节(如数字),来重新定义自己的模型架构。
# YOLO V5s# parametersnc: 13 # number of classesdepth_multiple: 0.33 # model depth multiplewidth_multiple: 0.50 # layer channel multiple# anchorsanchors:- [116,90, 156,198, 373,326] # P5/32- [30,61, 62,45, 59,119] # P4/16- [10,13, 16,30, 33,23] # P3/8# YOLOv5 backbonebackbone:# [from, number, module, args][[-1, 1, Focus, [64, 3]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, BottleneckCSP, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 9, BottleneckCSP, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, BottleneckCSP, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 1, SPP, [1024, [5, 9, 13]]],]# YOLOv5 headhead:[[-1, 3, BottleneckCSP, [1024, False]], # 9[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, BottleneckCSP, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, BottleneckCSP, [256, False]],[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 18 (P3/8-small)[-2, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, BottleneckCSP, [512, False]],[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 22 (P4/16-medium)[-2, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, BottleneckCSP, [1024, False]],[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1]], # 26 (P5/32-large)[[], 1, Detect, [nc, anchors]], # Detect(P5, P4, P3)]
为了更清楚的了解YOLO V5的模型结构,我们使用netron来实现模型可视化,值得注意的是,如果想获得清晰的网络图,需要将pt文件转化为torchscipt格式。

以下链接为YOLO V5s的网络图:
https://1drv.ms/u/s!An7G4eYRvZzthI5GRP8r_xv7r0Mzbg?e=03aAqB
Transfer learning theory
现在让我们来了解下本文的重点迁移学习。
什么是迁移学习?迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
再来看看我们面临的问题,我们已经有了YOLO V5模型框架,有了针对COCO数据集预训练的权重文件*.pt,Bdd100k的训练数据很庞大,而我们需要额外提取红绿灯的颜色作为新的类别,那怎么样才能把YOLO V5已经学习的模型参数通过某种方式分享给新模型从而加快并优化模型的学习效率?
下图为针对不同场景的迁移学习指南。

如果训练集小,训练数据与预训练数据相似,那么我们可以冻住卷积层,直接训练全连接层。 如果训练集小,训练数据与预训练数据不相似,那么必须从头训练卷积层及全连接层。 如果训练集大,训练数据与预训练数据相似,那么我们可以使用预训练的权重参数初始化网络,然后从头开始训练。 如果训练集大,训练数据与预训练数据不相似,那么我们可以使用预训练的权重参数初始化网络,然后从头开始训练或者完全不使用预训练权重,重新开始从头训练。 值得注意的是,对于大数据集,不推荐冻住卷积层,直接训练全连接层的方式,这可能会对性能造成很大影响。
我们的情况,符合上述第三种,通常只需要使用预训练的权重初始化网络,然后直接从头开始训练,从而更快的使模型有效收敛。但是由于之前没有人公开过对于Bdd100k数据集使用YOLO V5预训练权重和不使用其训练权重的对比,甚至你也可以说COCO数据集80类,而Bdd100k数据集13类,两者大部分类是不相似的。我并不能百分百确定哪个方案更适合本项目。于是我分别使用YOLO V5s预训练权重和不使用其训练权重来训练基于Bdd100k数据集的对象识别网络,并对比它们的效果。
Ultralytics一共提供了四个版本的YOLO V5模型。
下图是它们的比较:
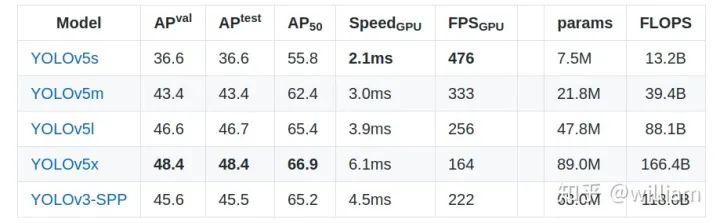
Intel Xeon W-2145 ,64 GB RAM,NVIDIA RTX 2080Ti,batch_size 32, Use RAM cache的情况下训练300 epochs 需要66小时,YOLO V5x是它的三倍。还是等我有时间再训练下YOLO V5x吧~Traininig
在我们完成所有的准备工作之后,我们可以开始训练了!
准备文件:
YOLO v5代码库 预处理后的bdd100k数据集:将JSON标签转换为YOLO格式,并按照YOLO V5的训练文件结构要求布置 custom_yolov5s.yaml:修改后的模型文件 uc_data.yaml: 包含训练,验证集的位置,类别数目及名称
训练配置:
Intel Xeon W-2145 ,64 GB RAM,NVIDIA RTX 2080Ti。
训练参数(基于bdd100k数据集进行分析):
— img: 输入图像的大小,建议使用640,因为对于交通场景,输入图片尺寸过小时,会导致部分对象宽高小于3像素,可能会影响训练精度 — batch-size: 批次大小,对于2080Ti-11GB 或者P100-16GB,输入img-size 640,batch-size 32为上限 — epochs: 训练迭代数,作者建议训练300个epochs起 — data: 创建的 YAML 文件uc_data.yaml — cfg: 模型文件Custom_yolov5s.yaml,需要自己至少修改类别数量及类别种类 — weights: 对于本项目不使用预训练权重,如果需要预训练权重,可以访问此地址 — cache-images: 将预处理后的训练数据全部存储在RAM中,能够加快训练速度 — hyp: 这个参数是自定义的hyp.yaml地址,对于小尺寸数据,可以更改hyp中optimizer为Adam,并修改配套参数为作者预设的Adam参数 — rect:输入这个参数,会关闭Mosaic数据增强 — resume:从上次训练的结束last.pt继续训练 — nosave:输入这个参数将存储最后的checkpoint,可以加快整体训练速度,但是建议关闭这个参数,这样能保留best.pt — notest:只测试最后一个epoch,能加快整体训练速度 — noautoanchor:关闭自适应自适应锚定框,YOLO V5会自动分析当前锚定框的 Best Possible Recall (BPR) ,对于img-size 640,最佳BPR为0.9900,随着img-size降低,BPR也随之变差 — multi-scale:输入图像多尺度训练,在训练过程中,输入图像会自动resize至 img-size +/- 50%,能一定程度上防止模型过拟合,但是对于GPU显存要求很高,对于640的img-size至少使用16GB显存,才能保证运行不出错 — single-cls:模型的输出为单一类别,比如我只需要识别Trunk — device: 选择使用CUDA或者CPU
YOLO V5的作者建议至少训练300个回合,每次训练完成后所有的结果及权重会储存在runs文件夹下。
训练过程:
Train from pre-weight(橘黄色)
!python train.py --img 640 --batch 32 --epochs 300 --data './models/uc_data.yaml' --cfg ./models/custom_yolov5s.yaml --weights "./weights/yolov5s.pt" --name yolov5s_bdd_prew --cacheTrain from scatch(蓝色)
!python train.py --img 640 --batch 32 --epochs 300 --data './models/uc_data.yaml' --cfg ./models/custom_yolov5s.yaml --weights "" --name yolov5s_bdd --cache训练结果:
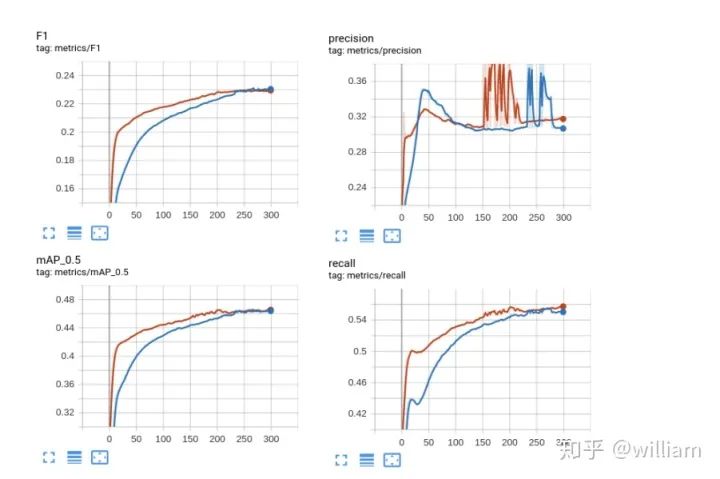
Metrics
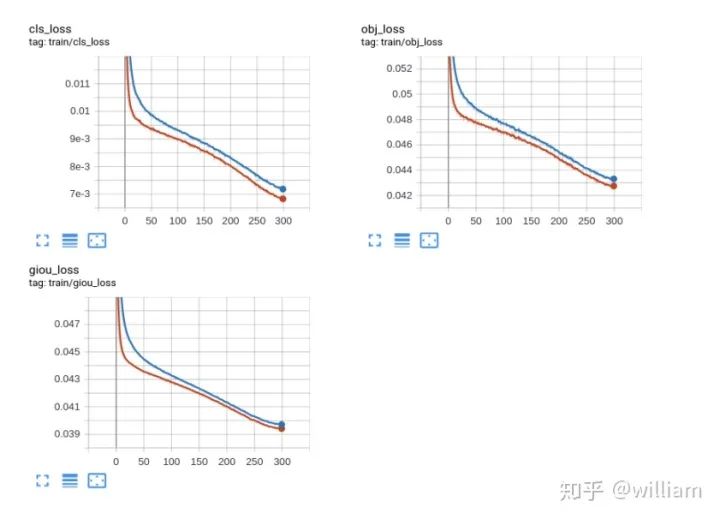
Train loss
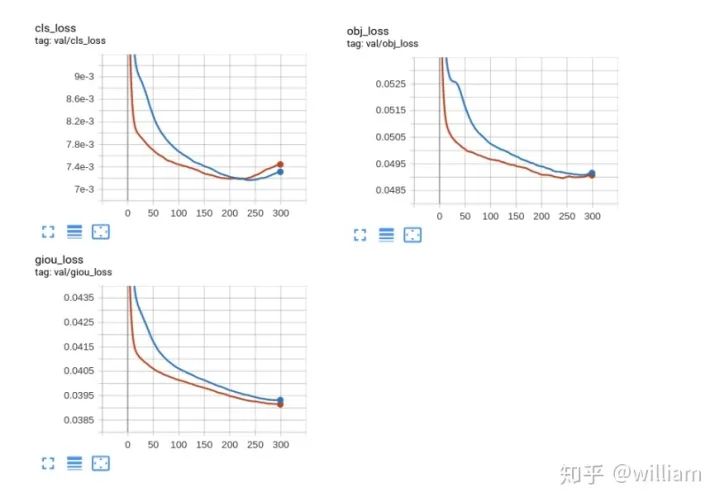
Valid loss
结果分析:
Train from pre-weight和Train from scatch的最高mAP_0.5均能达到46.5%。 Train from pre-weight比Train from scatch能更快收敛,但是在250epochs左右两者已经达到一致。 Train from pre-weight和Train from scatch的模型大小均为14.8M,值得注意的是YOLO V5在训练结束后会自动给模型剪枝,训练过程中的last.pt有58.6M,作者考虑的非常周到。 总的来说Train from pre-weight比Train from scatch能更快收敛,能一定程度上减少训练时间开销,对于和COCO数据集相近的数据集,可以采用Train from pre-weight,如果时间充裕,Train from scatch更为妥当。
现在我们已经完成了模型训练了,让我们在一些图像上测试它的性能吧。
检测参数:
— weights: 训练权重的路径 — source:推理目标的路径,可以是图片,视频,网络摄像头等 — source:推理结果的输出路径 — img-size:推理图片的大小 — conf-thres:对象置信阈值,默认0.4 — iou-thres:NMS的IOU阈值,可以根据实际对象的重叠度调节,默认0.5 — device: 选择使用CUDA或者CPU — view-img:显示所有推理结果 — save-txt:将每一帧的推理结果及边界框的位置,存入*.txt文件 — classes:类别过滤,意思是只推理目标类别 — agnostic-nms:使用agnostic-nms NMS
!python detect.py --weights runs/exp0_yolov5s_bdd_prew/weights/best_yolov5s_bdd_prew.pt --source bdd100k/images/test --save-txt

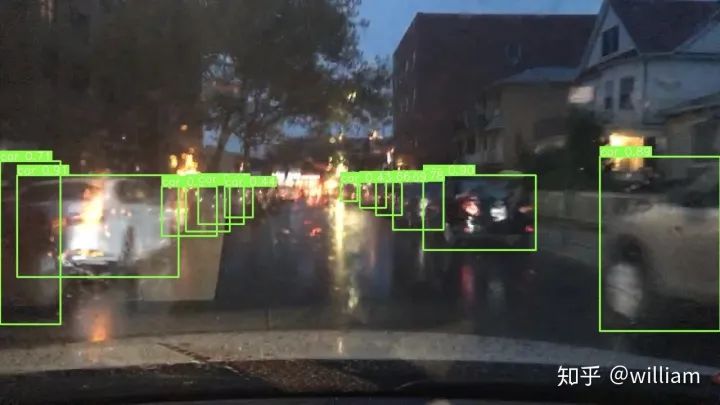

为了测试YOLO V5s的实时视频处理性能,我测试了一个4K 道路场景录制视频,推理速度高达7ms/帧。
点击下方链接可以直接访问bilibili上的视频:
https://www.bilibili.com/video/BV1sz4y1Q7wi/
Summary
至此我们已经了解了YOLO V5的网络结构,并且基于Bdd100k数据集训练了属于自己的自动驾驶对象检测模型。YOLO V5是个非常棒的开源对象检测网络,代码库的更新速度非常快,不管它现阶段配不配的上V5的名称,它都是一个快速而且强大的对象检测器。YOLO V5值得你去尝试!
