
手把手用YOLO做目标检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自 | 新机器视觉
作为目前机器学习领域最火热的研究方向之一,计算机视觉相关的技术一直备受关注。其中,目标检测是计算机视觉领域常见的问题之一,如何平衡检测的质量和算法的速度很重要。对于这个问题,计算机视觉工程师、VirtusLab 创始人 Piotr Skalski 发表了自己的心得,分享了关于他最喜欢的计算机视觉算法 YOLO 的实践资料。以下便是他的全文。【注:文章动图较多,请耐心等待加载。】
前言
YOLO 是我最喜欢的计算机视觉算法之一,在很长一段时间里,我计划着专为它写一篇博文。然而,我不希望它成为另一篇详细解释 YOLO 背后工作原理的文章,网上有很多文章都很好地涵盖了它理论方面的知识。除此之外,如果你想加深对这个架构的理解,直接从源代码获取信息并阅读源文件(https://arxiv.org/abs/1506.02640)也是一个好主意。

基于 YouTube-8M 数据集的篮球场球员移动检测
这一次,我将向你展示如何快速地、以相对较低的代价和不那么强大的机器创建目标检测模型,这个模型能够检测任何你选择的对象。如果你需要在工作中快速测试你的想法,或者只是有一小段时间建立在家构建你的项目,这是一个很好的方法。去年,我有机会进行了几个这样的实验,本文中出现的所有可视化结果都是出自这些项目。
注意:这一次,我们将主要使用开源库和工具,因此我们网站上的编码量将是最小的。但是,为了鼓励你使用 YOLO 并为你的项目提供一个起点,我还提供了脚本,允许你下载我的预训练模型以及所有配置文件和测试数据集。像往常一样,你会在我的 GitHub 上找到所有的内容:https://github.com/SkalskiP/ILearnDeepLearning.py/tree/master/02_data_science_toolkit/02_yolo_object_detection
YOLO
所有不知道 YOLO 是什么的人不要担心,也不要去任何地方找资料!我现在简要地解释一下我说的是什么。
YOLO 是一种实时目标检测算法,它是第一个平衡所提供检测的质量和速度的算法。通常,这类最强大的模型,都是建立在卷积神经网络的基础上,这次也不例外。所谓「目标检测模型」,我们的意思是,我们不仅可以用它来找出给定照片中存在的对象,还可以用它来指示它们的位置和数量。除其他外,这种模型在机器人和汽车工业中都有应用,因此检测速度至关重要。自2015年以来,该算法已经进行了三次迭代,还有为 TinyYOLO 等移动设备设计的变体。移动版本的精度有限,但计算要求也较低,运行速度更快。
数据集
和深度学习一样,创建模型的第一步是准备一个数据集。有监督的学习是查看标记的示例并在数据中发现不明显的模式。我必须承认创建一个数据集是一个相当乏味的任务,因此我准备了一个脚本,允许你下载我的象棋数据集,并查看 YOLO 如何在这个例子中工作。
但那些想要建立自己的数据集的人面临着挑战。为了实现这个目标,我们需要收集一组图像并创建匹配的标签文件。图片应该包含我们想识别的对象,并且,数据集中所有对象的类的分布应该类似。如你所见,在我的第一个项目——篮球探测器中,我使用了游戏视频中的框架。

篮球数据集的图像样本
标签文件应该与图像具有相同的名称,但显然具有不同的扩展名,并且应该位于并行目录中。最佳数据结构如下所示。除了 images 和 labels 目录之外,我们还必须准备 class_names.txt 文件,该文件定义我们计划检测的对象类的名称。这个文件的每一行代表一个类,应该包含一个或多个没有空格的单词。
project└──dataset├── class_names.txt├── images│ ├── image_1.png│ ├── image_2.png│ └── image_3.png│ ...└── labels├── image_1.txt├── image_2.txt└── image_3.txt...
标记
不幸的是,YOLO 需要一个特定的标签格式,这是大多数免费标签工具不支持的。为了消除从 VOC XML、VGG JSON 或其他广泛使用的格式解析标签的需要,我们将利用 makesense.ai(https://www.makesense.ai/ ),这里是我在 GitHub 上开发的一个免费开源项目(https://github.com/SkalskiP/make-sense )。编辑器不仅支持直接导出到 YOLO 格式,而且直观,不需要安装,可以在浏览器中工作。此外,它还支持多种功能,旨在加快你的标签工作。可以使用 MakeSense 查看人工智能支持的标记过程。
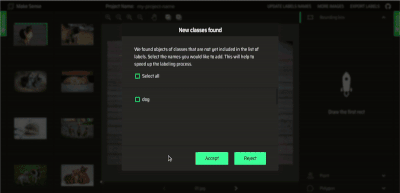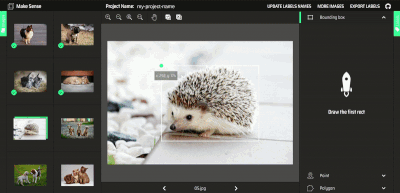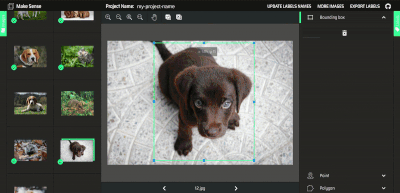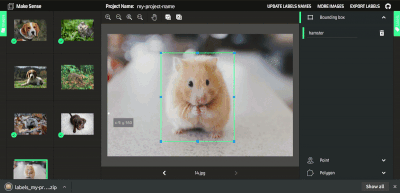
AI 支持使用 makesense.ai 进行标记
工作完成后,我们可以下载一个 .zip 文件,其中包含 .txt 文件。每一个这样的文件都对应于一个标记的图像,并描述照片中可见的对象。如果我们打开其中一个文件,我们会发现,每一行都是 class_idx x_center y_center width height 式。其中 class_idx 表示 class_names.txt 文件中指定标签的索引(从 0 开始计数)。其余参数描述围绕单个对象的边界框,它们可以取 0 到 1 之间的值。幸运的是,大多数时候我们不需要考虑这些细节,因为编辑器会为我们处理所有的事情。YOLO 格式的标签示例如下所示。
4 0.360558 0.439186 0.068327 0.2507417 0.697519 0.701205 0.078643 0.2282433 0.198589 0.683692 0.076613 0.263441
环境设置
YOLO 最初是在一个叫做 Darknet 的深度学习的小框架中写的。从那时起,许多其它实现已经创建,其中大多数使用两个非常流行的 Python 平台:Keras 和 PyTorch。在所有可用的解决方案中,有一个是我特别喜欢的(https://github.com/ultralytics/yolov3 )。它提供了一个用于训练和检测的高级 API,但也具有很多有用的特性。在使用它时,我们的所有工作归结为准备一个数据集和创建几个配置文件,然后其余的工作就交给库了。
project├── dataset└── yolov3
环境设置也非常简单——可以归结为运行几个命令,你可以在下面找到这些命令(假设你的计算机上已经安装了 Python 和 Git)。最好从项目目录中执行命令,以实现上面所示的结构。值得一提的是,环境也可以通过 Docker 创建(这对 Windows 用户特别有用)。你可以在这里(https://github.com/ultralytics/yolov3/wiki/Docker-Quickstart )找到更多关于这个主题的说明。
# Clone frameworkgit clone https://github.com/ultralytics/yolov3.git# Enter framework catalogue [Linux/MacOS]cd ./yolov3# Setup Python environmentpip install -U -r requirements.txt
配置
如前一段所述,我们现在需要做的就是创建几个配置文件。它们定义了训练集和测试集的位置、对象类的名称,并提供了所用神经网络的架构指南。

国际象棋数据集标注参考图片
首先,我们需要将数据集分割成训练集和测试集。我们使用两个 .txt 文件来完成这项工作,它们中的每一个都包含指向数据集中特定图像的路径。为了加快工作速度,我准备了一个 Python 脚本,它将自动为我们创建这些文件。你只需指示数据集的位置并定义训练集和测试集之间的分割百分比。train.txt/test.txt 文件的片段如下所示。
./dataset/images/image_1.png./dataset/images/image_2.png./dataset/images/image_3.png...
.data 是我们需要提供的最终文件。让我们用下一个项目的例子来讨论它的内容——象棋检测器。在本例中,我有 12 个惟一的对象类想要识别。接下来,我们给出定义哪些照片属于训练集,哪些照片属于测试集的文件的位置,最后给出前面讨论的带有标签名称的文件的位置。为了使一切正常工作,chess.data、chess_train.txt、chess_test.txt 和 chess.names 文件应移动到 project/yolov3/data 目录。
classes=12train=./data/chess_train.txtvalid=./data/chess_test.txtnames=./data/chess.names
训练
现在我们准备开始训练。如前所述,我们使用的库有一个高级 API,因此终端中的一个命令和几个参数就足以启动这个过程。然而,在下面还有几件大大增加我们取得最终成功的几率的事情。
python3 train.py--data ./data/project.data--cfg ./cfg/project.cfg--weights ./weights/yolov3.pt
首先,我们可以应用迁移学习,我们不必从头开始训练。我们可以使用在不同数据集上训练的模型的权重,从而缩短我们自己的网络的学习时间。我们的模型可以使用基本的形状知识,并专注于将这些信息链接到我们想要识别的新类型的对象。其次,库执行数据增强,因此它根据我们提供的照片生成新的示例。因此,即使我们只有一个很小的数据集——几百张图片,我们也可以训练我们的模型。我们使用的库还为我们提供了一个由于增强而创建的图像示例。下面你可以看到在我的篮球探测器的训练过程中创建的示例。

训练集数据增强的可视化
检测
最后,快乐的时刻来了!我们致力于创建模型的工作得到了回报,现在可以用它来找到我们在任何照片中想要寻找的对象。同样地,这是一个非常简单的任务,我们可以用终端中的一个简单命令来完成。执行之后,我们将在输出目录中找到预测的结果。值得一提的是,我们还可以对自己拍摄的视频进行实时预测,这在项目演示中尤其有用。
python3 detect.py--data ./data/project.data--cfg ./cfg/project.cfg--weights ./weights/best.py--source ./data/sample

基于 TinyYOLO 的象棋检测
结论
如果你完成了上面的所有内容,那么恭喜你!非常感谢你花时间阅读这篇文章。我希望我能证明训练你自己的定制 YOLO 模型并不困难,我的建议将对你未来的实验有所帮助。
 End
End
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~