
ECCV2020 F3-Net 商汤Deepfake检测模型
前言
这篇论文是商汤团队在ECCV2020的一个工作:Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues,通过引入两种提取频域特征的方法FAD (Frequency-Aware Decomposition) 和LFS (Local Frequency Statistics) ,并设计了一个 MixBlock 来融合双路网络的特征,从而在频域内实现对Deepfake的检测
介绍
随着Deepfake技术不断迭代,检测合成人脸的挑战也越来越多。虽然已有的基于RGB色彩空间的检测技术准确率不错,但是实际中,这些视频随着流媒体传播,视频通常会被多次压缩,而在较低质量的视频中,要想进行检测就比较困难,这也一定程度上启发我们去挖掘频域内的信息。
那么问题来了,我们如何才能把频域信息引入到CNN中?传统的FFT和DCT不满足平移不变性和局部一致性,因此直接放在CNN可能是不可行的。
我们提出了两种频率特征,从一个角度来看,我们可以根据分离的频率分量重组回原来的图片,因此第一种频率特征也就可以被设计出来,我们可以对分离的频率分量经过一定处理,再重组回图片,最终的结果也适合输入进CNN当中。这个角度本质上是在RGB空间上描述了频率信息,而不是直接给CNN输入频率信息。这也启发了我们的第二种频率特征,在每个局部空间(patch)内,统计频率信息,并计算其平均频率响应。这些统计量可以重组成多通道特征图,通道数目取决于频带数目
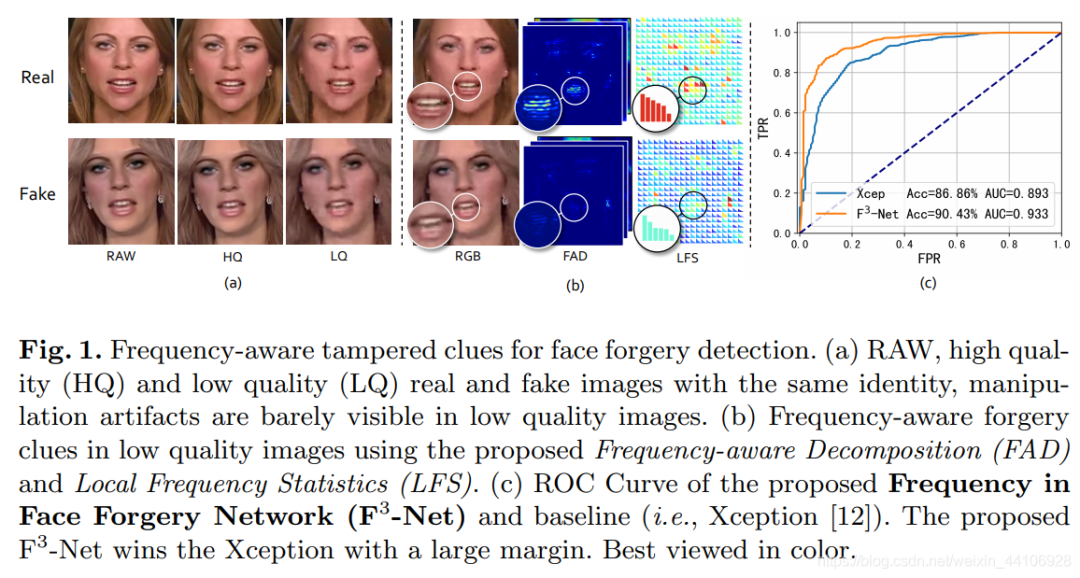
如上图,在低质量(Low Quality)图片中,两种图片都很真实,但是在局部的频率统计量(LFS)中,呈现出明显的差异,这也就很自然能被检测出来。
基于上述两种特征,我们设计了 Frequency in Face Forgery Network(),第一个频率特征为FAD(Frequency-aware Image Decomposition),第二个频率特征为LFS(Local Frequency Statistics)。因为这两个特征是相辅相成的,我们还设计了一种融合模块MixBlock来融合其在双路网络中的特征。整体流程如下图所示
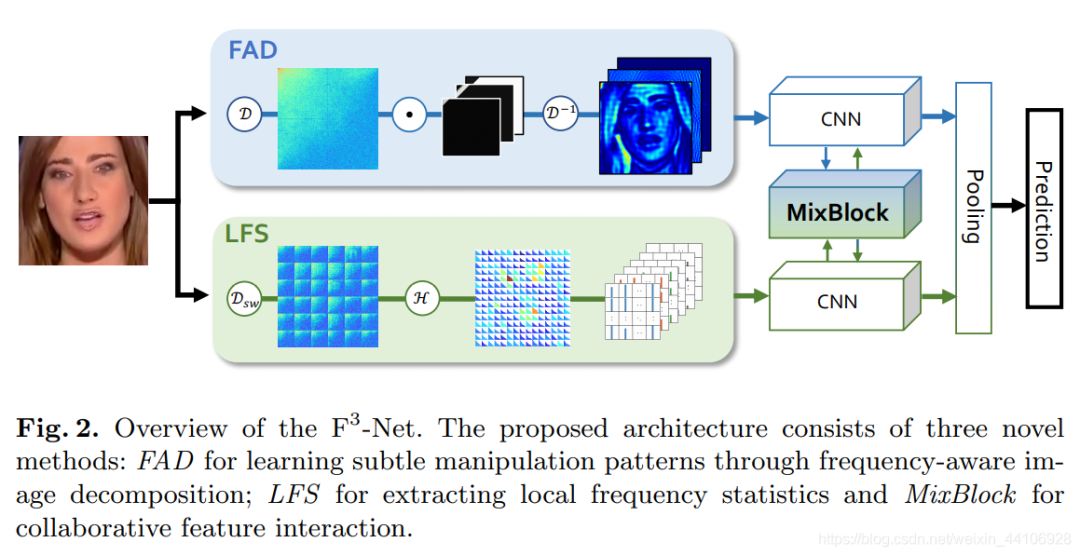
FAD
以往的工作采用的是人工设计频域滤波器,但这无法完全覆盖所有的图像模式,并且固定的滤波器很难自适应的捕捉到图像中伪造的模式。因此我们提出了自适应的滤波方法,具体做法如下:
设计N个二分类滤波器(也就是所谓的掩码mask),将图像的频率分为低,中,高三个频带。 为了让其具备自适应能力,我们额外设计三个可学习的滤波器。然后分别将这两种滤波器结合在一起,公式如下
其中 为 归一化,目的是限制其值在 (-1, 1) 之间
我们将这两个滤波器应用在DCT变换后 最后做反DCT,将图像重组回来
总的公式如下
其中D代表DCT变换,代表反DCT变换
FAD的流程如下
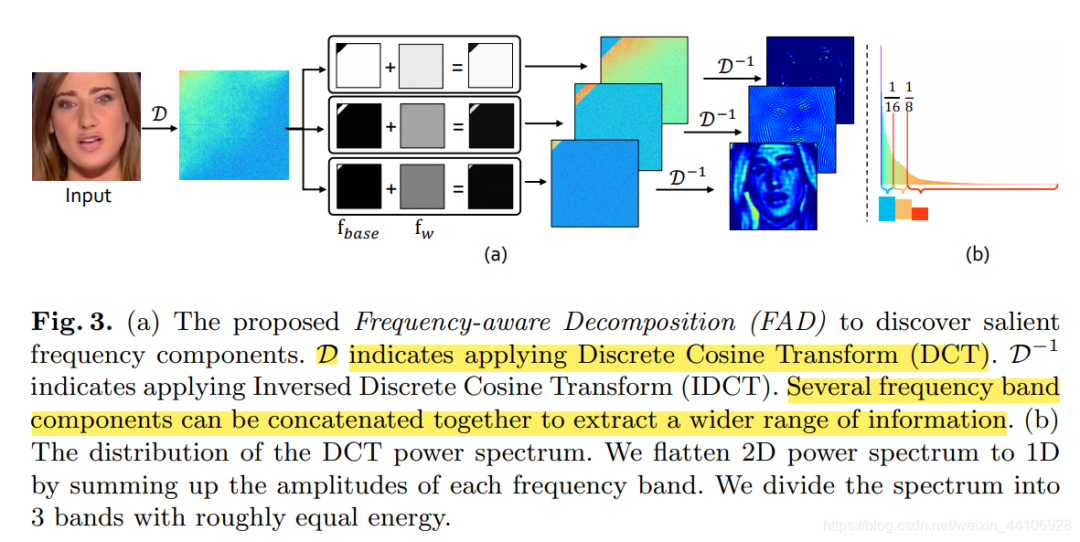
其中b图是将2维频谱展开成1维的形式,我们可以看到第一个滤波器取的是整个频段的1/16,而第二个滤波器取得是1/16~1/8,第三个滤波器则取得是剩下的7/8。
LFS
前面的FAD尽管提取到了频域特征,但它最后是通过反DCT变换,转化到RGB空间上,输入进CNN。这些信息并不是直接的频域信息,因此我们提出了局部频域特征local frequency statistics(LFS),它能满足RGB图片的平移不变性以及局部一致性。

具体流程如下
对输入的图片采用滑窗DCT(Silde Window DCT),从而提取局部的频率响应。 计算一系列可学习频带的频率响应均值3.将频率统计信息重新组合为与输入图像共享相同布局的多通道空间映射
其中log10是为了调整数值级别,D是滑窗DCT变换。
跟FAD一样,我们这里也设计了二分类滤波器和可学习滤波器,操作流程跟FAD完全一样,这里就不展开了。
对于每个滑窗w中的局部统计信息q**,经过上述变换被转换为 的向量**
在我们的实验中,我们将每个滑窗大小设置为10x10,步长为2,频带数目为6。一张299 x 299 x 3的图片输入进来将被转换为 149 x 149 x 6。
MixBlock
虽然这两种频率特征不同,但具有一致性,都是从DCT变换,并经过滤波器进行不同频率分离。因此我们设计了一种MixBlock来在双路网络中融合两者的特征。

FAD和LFS共同输入进卷积里,得到一个AttentionMap FAD和LFS分别与AttentionMap相乘得到和 与相加,与相加,完成特征融合。
论文里双路网络都采用的是Xception网络,该网络一共有12个Block,我们将融合模块分别放置在第7个和第12个XceptionBlock里,对中,高层特征进行融合操作
实验

这张对比图很好的表现了F3-Net在低质量图片中的表现,可见在频域内做检测确实有更好的抗压缩性能。
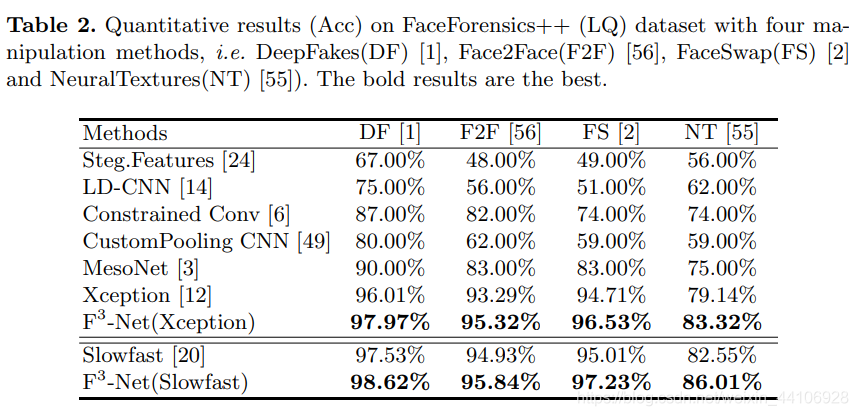
在不同数据集上表现也比较稳定,没有因数据集的分布产生较大波动

最后作者也设计了一系列消融实验,来表明各个模块的有效性。
总结
这篇工作还是挺有意思的,不同于以往传统频域特征,它选择将传统和深度学习进行结合,为可学习的滤波器设定一定约束,从而根据不同图像自适应分离出频率信息。Deepfake的一大难点就是对低质量,多次压缩图片的检测,因为在RGB图片上是很难发现的。最终的实验也表明该方法的有效性,坐等商汤开源代码
为了感谢读者朋友们的长期支持,我们今天将送出3本由北京大学出版社提供的《深度学习笔记》书籍,对本书感兴趣的可以在上方的留言区留言,我们将抽取其中三位读者送出一本正版书籍。

欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。