
QQ浏览器视频相似度算法

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
视频Embedding采用稠密向量能够很好的表达出视频的语义,在推荐场景下对视频去重、相似召回、排序和多样性打散等场景都有重要的作用。
本任务从视频推荐角度出发,提供真实业务的百万量级标签数据(脱敏),以及万量级视频相似度数据(人工标注),用于训练embedding模型,最终根据embedding计算视频之间的余弦相似度,采用Spearman’s rank correlation与人工标注相似度计算相关性,并最终排名。


模型简介
多模态模型结构与参数量和 Bert-large 一致,
layer=24, hidden_size=1024, num_attention_heads=16。
其输入为[CLS] Video_frame [SEP] Video_title [SEP]。
frame_feature 通过 fc 降维为 1024 维,与 text 的 emb 拼接。
Input_emb -> TransformerEncoder * 24 -> Pooling -> Fc -> Video_emb
全部代码,数据集获取方式:
关注微信公众号 datanlp 然后回复 视频 即可获取。
预训练
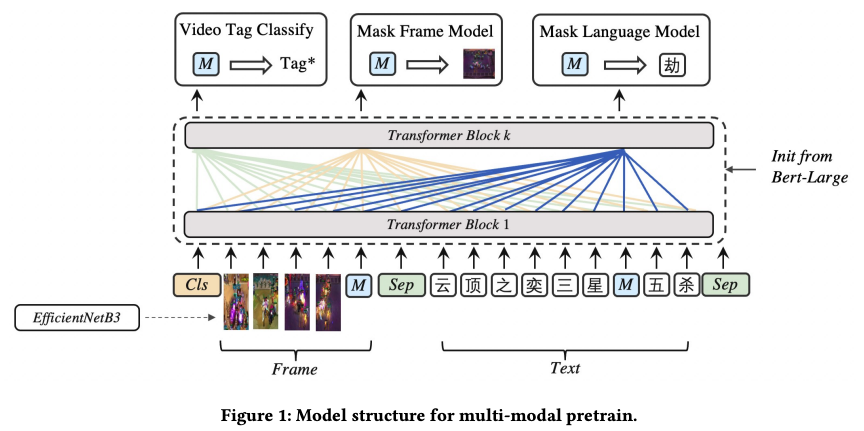
预训练采用了 Tag classify, Mask language model, Mask frame model 三个任务
(1) Video tag classify 任务
tag 为人工标注的视频标签,pointwise 和 pairwise 数据集合中提供。
和官方提供的 baseline 一致,我们采用了出现频率前1w 的tag 做多标签分类任务。
Bert 最后一层的 [CLS] -> fc 得到 tag 的预测标签,与真实标签计算 BCE loss
(2) Mask language model 任务
与常见的自然语言处理 mlm 预训练方法相同,对 text 随机 15% 进行 mask,预测 mask 词。
多模态场景下,结合视频的信息预测 mask 词,可以有效融合多模态信息。
(3) Mask frame model 任务
对 frame 的随机 15% 进行 mask,mask 采用了全 0 的向量填充。
考虑到 frame 为连续的向量,难以类似于 mlm 做分类任务。
借鉴了对比学习思路,希望 mask 的预测帧在整个 batch 内的所有帧范围内与被 mask 的帧尽可能相似。
采用了 Nce loss,最大化 mask 帧和预测帧的互信息
(4) 多任务联合训练
预训练任务的 loss 采用了上述三个任务 loss 的加权和,
L = L(tag) * 1250 / 3 + L(mlm) / 3.75 + L(mfm) / 9
tag 梯度量级比较小,因此乘以了较大的权重。
注:各任务合适的权重对下游 finetune 的效果影响比较大。
(5) 预训练 Setting
初始化:bert 初始化权重来自于在中文语料预训练过的开源模型 https://huggingface.co/hfl/chinese-roberta-wwm-ext-large
数据集:预训练使用了 pointwise 和 pairwise 集合,部分融合模型中加上了 test 集合(只有 mlm 和 mfm 任务)
超参:batch_size=128, epoch=40, learning_rate=5e-5, scheduler=warmup_with_cos_decay, warum_ratio=0.06
注:预训练更多的 epoch 对效果提升比较大,从10 epoch 提升至 20 epoch 对下游任务 finetune 效果提升显著。
Finetune
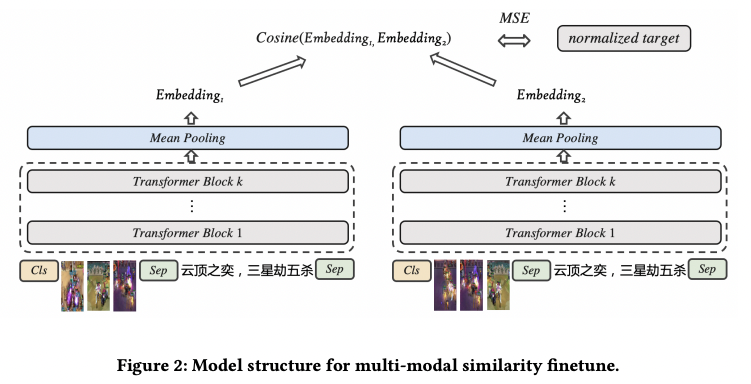
(1) 下游任务
视频 pair 分别通过 model 得到 256维 embedding,两个 embedding 的 cos 相似度与人工标注标签计算 mse
(2) Finetune header
实验中发现相似度任务中,使用 mean_pooling 或者 attention_pooling 聚合最后一层 emb 接 fc 层降维效果较好。
(3) Label normalize
评估指标为 spearman,考查预测值和实际值 rank 之间的相关性,因此对人工标注 label 做了 rank 归一化。
即 target = scipy.stats.rankdata(target, 'average')
(4) Finetune Setting
数据集:训练集使用了 pairwise 中 (id1%5!=0) | (id2%5 !=0) 的部分约 6.5w,验证集使用了(id1%5==0) & (id2%5==0) 的部分约 2.5k
超参:batch_size=32, epoch=10, learning_rate=1e-5, scheduler=warmup_with_cos_decay, warum_ratio=0.06
Ensemble
(1) 融合的方法
采用了 weighted concat -> svd 降维 方法进行融合,发现这种方法降维效果折损较小。concat_vec = [np.sqrt(w1) * emb1, np.sqrt(w2) * emb2, np.sqrt(w3) * emb3 ...]svd_vec = SVD(concat_vec, 256)
(2) 融合的模型
最终的提交融合了六个模型。模型都使用了 bert-large 这种结构,均为迭代过程中产出的模型,各模型之间只有微小的 diff,各个模型加权权重均为 1/6。
下面表格中列出了各模型的diff部分,验证集mse,验证集spearman
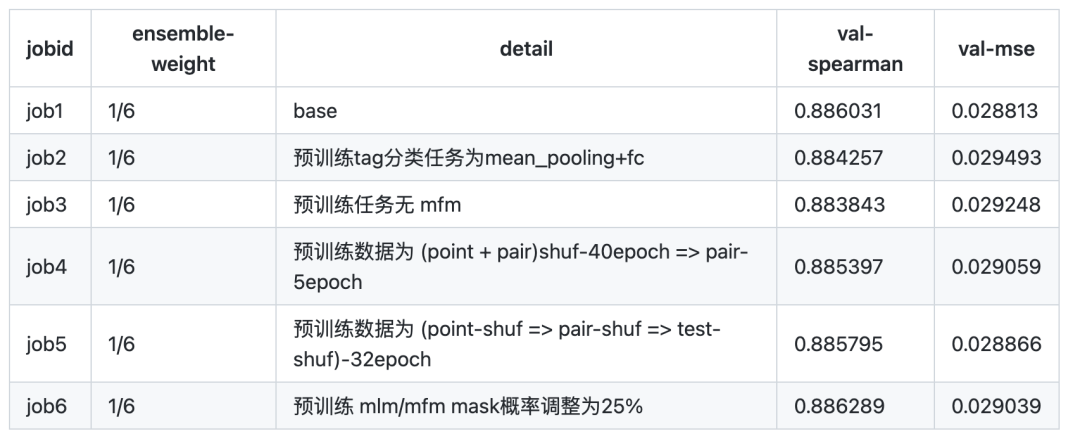
(3) 单模型的效果与融合的效果
单模的测试集成绩约在 0.836
融合两个模型在 0.845
融合三个模型在 0.849
融合五个模型在 0.852
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx