DALL-E 2的工作原理原来是这样!
作者 | Ryan O'Connor
编译丨王玥 编辑 | 陈彩娴
来源 | AI科技评论
OpenAI的模型DALL-E 2于本月初发布,刚一亮相,便在图像生成和图像处理领域卷起了新的风暴。
只需要给到寥寥几句文本提示,DALL-E 2就可以按文本指示生成全新图像,甚至能将毫不相关的物体以看似合理的语义方式组合在一起。
比如用户输入提示“一碗汤是另一个次元的入口”后,DALL-E 2便生成了以下的魔幻图片。

“一碗汤是另一个次元的入口” 图源:https://openai.com/dall-e-2/
DALL-E 2不仅能按用户指令生成明明魔幻,却又看着十分合理不明觉厉的图片。作为一款强大的模型,目前我们已知DALL-E 2还可以:
生成特定艺术风格的图像,仿佛出自该种艺术风格的画家之手,十分原汁原味!
保持一张图片显著特征的情况下,生成该图片的多种变体,每一种看起来都十分自然;
修改现有图像而不露一点痕迹,天衣无缝。
感觉有了DALL-E 2,艺术家都可以下岗了。
DALL-E 2目前曝光的功能令人瞠目结舌,不禁激起了众多AI爱好者的讨论,这样一个强大模型,它的工作原理到底是什么?!

"一只在吹喷火喇叭的柯基”——DALL-E 2图片生成流程解析 图源:https://arxiv.org/abs/2204.06125
针对图片生成这一功能来说,DALL-E 2的工作原理剖析出来看似并不复杂:
首先,将文本提示输入文本编码器,该训练过的编码器便将文本提示映射到表示空间。
接下来,称为先验的模型将文本编码映射到相应的图像编码,图像编码捕获文本编码中包含的提示的语义信息。
最后,图像解码模型随机生成一幅从视觉上表现该语义信息的图像。
可是以上步骤说起来简单,分开看来却是每一步都有很大难度,让我们来模拟DALL-E 2的工作流程,看看究竟每一步都是怎么走通的。
我们的第一步是先看看DALL-E 2是怎么学习把文本和视觉图像联系起来的。
第一步 - 把文本和视觉图像联系起来
输入“泰迪熊在时代广场滑滑板”的文字提示后,DALL-E 2生成了下图:

图源:https://www.assemblyai.com/blog/how-dall-e-2-actually-works/
DALL-E 2是怎么知道“泰迪熊”这个文本概念在视觉空间里是什么样子的?
其实DALL-E 2中的文本语义和与其相对的视觉图片之间的联系,是由另一个OpenAI模型CLIP(Contrastive Language-Image Pre-training)学习的。
CLIP接受过数亿张图片及其相关文字的训练,学习到了给定文本片段与图像的关联。
也就是说,CLIP并不是试图预测给定图像的对应文字说明,而是只学习任何给定文本与图像之间的关联。CLIP做的是对比性而非预测性的工作。
整个DALL-E 2模型依赖于CLIP从自然语言学习语义的能力,所以让我们看看如何训练CLIP来理解其内部工作。
CLIP训练
训练CLIP的基本原则非常简单:
首先,所有图像及其相关文字说明都通过各自的编码器,将所有对象映射到m维空间。
然后,计算每个(图像,文本)对的cos值相似度。
训练目标是使N对正确编码的图像/标题对之间的cos值相似度最大化,同时使N2 - N对错误编码的图像/标题对之间的cos值相似度最小化。
训练过程如下图所示:

CLIP训练流程
CLIP对DALL-E 2的意义
CLIP几乎就是DALL-E 2的心脏,因为CLIP才是那个把自然语言片段与视觉概念在语义上进行关联的存在,这对于生成与文本对应的图像来说至关重要。
第二步 - 从视觉语义生成图像
训练结束后,CLIP模型被冻结,DALL-E 2进入下一个任务——学习怎么把CLIP刚刚学习到的图像编码映射反转。CLIP学习了一个表示空间,在这个表示空间当中很容易确定文本编码和视觉编码的相关性, 我们需要学会利用表示空间来完成反转图像编码映射这个任务。
而OpenAI使用了它之前的另一个模型GLIDE的修改版本来执行图像生成。GLIDE模型学习反转图像编码过程,以便随机解码CLIP图像嵌入。
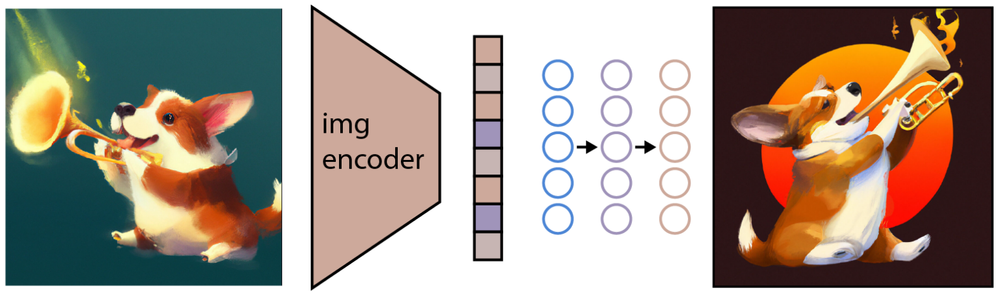
“一只吹喷火喇叭的柯基”一图经过CLIP的图片编码器,GLIDE利用这种编码生成保持原图像显著特征的新图像。 图源:https://arxiv.org/abs/2204.06125
如上图所示,需要注意的是,我们的目标不是构建一个自编码器并在给定的嵌入条件下精确地重建图像,而是在给定的嵌入条件下生成一个保持原始图像显著特征的图像。为了进行图像生成,GLIDE使用了扩散模型(Diffusion Model)。
何为扩散模型?
扩散模型是一项受热力学启发的发明,近年来越来越受到学界欢迎。扩散模型学习通过逆转一个逐渐噪声过程来生成数据。如下图所示,噪声处理过程被视为一个参数化的马尔可夫链,它逐渐向图像添加噪声使其被破坏,最终(渐近地)导致纯高斯噪声。扩散模型学习沿着这条链向后走去,在一系列步骤中逐渐去除噪声,以逆转这一过程。

扩散模型示意图 图源:https://arxiv.org/pdf/2006.11239.pdf
如果训练后将扩散模型“切成两半”,则可以通过随机采样高斯噪声来生成图像,然后对其去噪,生成逼真的图像。大家可能会意识到这种技术很容易令人联想到用自编码器生成数据,实际上扩散模型和自编码器确实是相关的。
GLIDE的训练
虽然GLIDE不是第一个扩散模型,但其重要贡献在于对模型进行了修改,使其能够生成有文本条件的图像。
GLIDE扩展了扩散模型的核心概念,通过增加额外的文本信息来增强训练过程,最终生成文本条件图像。让我们来看看GLIDE的训练流程:

下面是一些使用GLIDE生成的图像示例。作者指出,就照片真实感和文本相似度两方面而言,GLIDE的表现优于DALL-E(1)。

由GLIDE生成的图像示例 图源https://arxiv.org/pdf/2112.10741.pdf
DALL-E 2使用了一种改进的GLIDE模型,这种模型以两种方式使用投影的CLIP文本嵌入。第一种方法是将它们添加到GLIDE现有的时间步嵌入中,第二种方法是创建四个额外的上下文标记,这些标记连接到GLIDE文本编码器的输出序列。
GLIDE对于DALL-E 2的意义
GLIDE对于DALL-E 2亦很重要,因为GLIDE能够将自己按照文本生成逼真图像的功能移植到DALL-E 2上去,而无需在表示空间中设置图像编码。因此,DALL-E 2使用的修改版本GLIDE学习的是根据CLIP图像编码生成语义一致的图像。
第三步 - 从文本语义到相应的视觉语义的映射
到了这步,我们如何将文字提示中的文本条件信息注入到图像生成过程中?
回想一下,除了图像编码器,CLIP还学习了文本编码器。DALL-E 2使用了另一种模型,作者称之为先验模型,以便从图像标题的文本编码映射到对应图像的图像编码。DALL-E 2的作者用自回归模型和扩散模型进行了实验,但最终发现它们的性能相差无几。考虑到扩散模型的计算效率更高,因此选择扩散模型作为 DALL-E 2的先验。
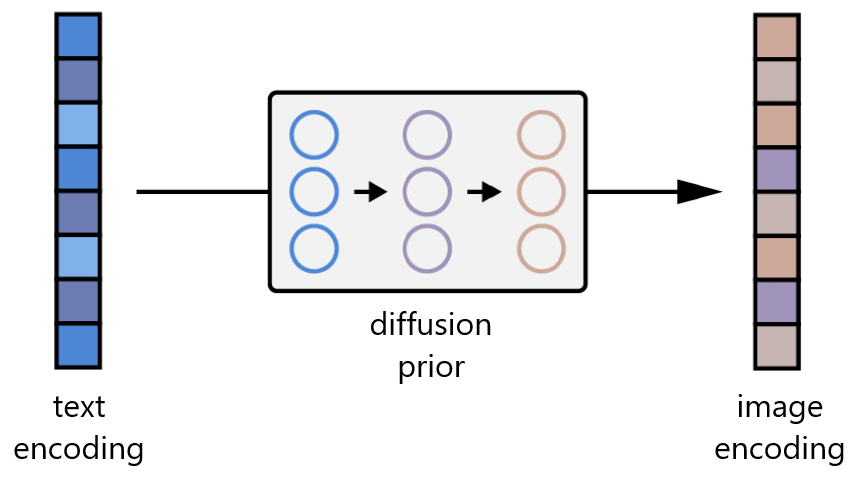
从文本编码到相应图像编码的先验映射 修改自图源:https://arxiv.org/abs/2204.06125
先验训练
DALL-E 2中扩散先验的运行顺序是:
标记化的文本;
这些标记的CLIP文本编码;
扩散时间步的编码;
噪声图像通过CLIP图像编码器;
Transformer输出的最终编码用于预测无噪声CLIP图像编码。
第四步 - 万事俱备
现在,我们已经拥有了DALL-E 2的所有“零件”,万事俱备,只需要将它们组合在一起就可以获得我们想要的结果——生成与文本指示相对应的图像:
首先,CLIP文本编码器将图像描述映射到表示空间;
然后扩散先验从CLIP文本编码映射到相应的CLIP图像编码;
最后,修改版的GLIDE生成模型通过反向扩散从表示空间映射到图像空间,生成众多可能图像中的一个。
DALL-E 2图像生成流程的高级概述 修改自图源:https://arxiv.org/abs/2204.06125
以上就是DALL-E 2的工作原理啦~
希望大家能注意到DALL-E 2开发的3个关键要点:
DALL-E 2体现了扩散模型在深度学习中的能力,DALL-E 2中的先验子模型和图像生成子模型都是基于扩散模型的。虽然扩散模型只是在过去几年才流行起来,但其已经证明了自己的价值,我们可以期待在未来的各种研究中看到更多的扩散模型~
第二点是我们应看到使用自然语言作为一种手段来训练最先进的深度学习模型的必要性与强大力量。DALL-E 2的强劲功能究其根本还是来自于互联网上提供的绝对海量的自然语言&图像数据对。使用这些数据不仅消除了人工标记数据集这一费力的过程所带来的发展瓶颈;这些数据的嘈杂、未经整理的性质也更加反映出深度学习模型必须对真实世界的数据具有鲁棒性。
最后,DALL-E 2重申了Transformer作为基于网络规模数据集训练的模型中的最高地位,因为Transformer的并行性令人印象十分深刻。
——The End——

分享
收藏
点赞
在看