
【NLP】AAAI21最佳论文Runners Up!Transformer的归因探索!
Self-Attention Attribution: Interpreting Information Interactions Inside Transformer(AAAI21)

在之前大家对于Transformer的理解都是,Transformer的成功得益于强大Multi-head自注意机制,从输入中学习token之间的依赖关系以及编码上下文信息。我们都很难解释输入特性如何相互作用以实现预测的。Attention计算得到的分数也并不能完美的解释这些交互作用,本文提出一种自我注意归因方法来解释Transformer内部的信息交互。我们以Bert为例进行研究。首先,我们利用自我注意归因来识别重要的注意头,其它注意头会随着边际效果的下降而被剪掉。此外,我们提取了每个层中最显著的依赖关系,构造了一个属性树,揭示了Transformer内部的层次交互。最后,我们证明了归因结果可以作为对抗模式来实现对BERT的非目标攻击。
那么该方案是怎么做的呢?


1.背景知识
给定输入, 我们将word的embedding打包成一个矩阵, 叠加的层Transformer通过
的方式计算得到最终的输出。
这其中最为核心的就是Multi-head的self-attention,self-attention的第个head为:
其中,表示有多关注,此处我们假设为attention heads的个数,最终multi-head attention可以通过下面的形式得到:
其中,,表示链接的意思。
2.Self-Attention Attribution
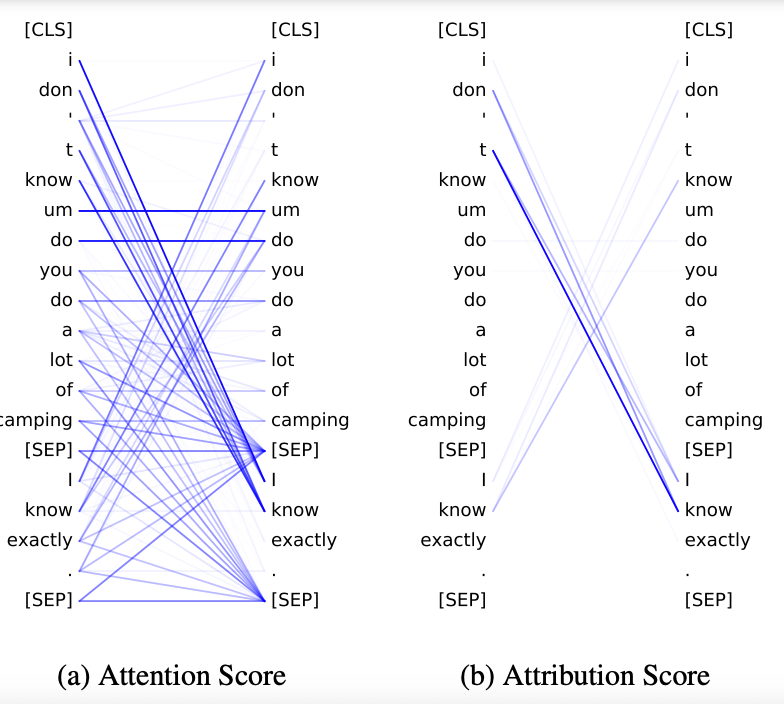
上图左侧是微调后的BERT中一个头部的注意力分数。我们观察到:
注意力得分矩阵是相当密集的,虽然只有一个12个head。这很难让我们去理解单词在Transformer中是如何相互作用的。 此外,即使注意力分数很大,也不意味着这对词对决策建模很重要; 相比之下,我们的目标是将模型决策归因于自我注意关系,如果交互作用对最终预测的贡献更大,那么自我注意关系往往会给出更高的分数。
给定输入,表示Transformer模型,它将attention权重矩阵作为模型输入,此处,我们操纵内部注意得分,并观察相应的模型动态 来检验单词交互的贡献。由于属性总是针对一个给定的输入,为了简单起见,我们此处省略它。
我们计算第个attention head的时候,我们先得到我们的归因得分矩阵。
其中表示element-wise的乘法,表示第个attention权重矩阵,计算模型关于的梯度,所以的第个元素就是关于第个attention head的token 和token 交互计算的。
表示在一个层中,所有token都不相互关注。当从0变为1时,
如果注意联系对模型预测有较大影响,其梯度也会越加显著,因此积分值也会较大。
直观地说, 不仅考虑了attention分数,而且还考虑了模型预测对注意关系的敏感性。
attribution分数可以通过积分的Riemman近似来计算得到,具体地说,我们在从零注意矩阵到原始注意权重A的直线路径上以足够小的间隔出现的点处求梯度的和。
其中为近似的步数,后续实验中,我们将其设置为20。
我们再看一下下面这张图:
我们发现:
更大的注意分数并不意味着对最终预测的贡献更大。SEP标记与其它标记之间的注意得分相对较大,但获得的归因得分较少。 对contradiction类的预测,最主要的是第一节中的“don't”与第二节中的“I know”之间的联系,这种联系更容易解释。
1.效果分析
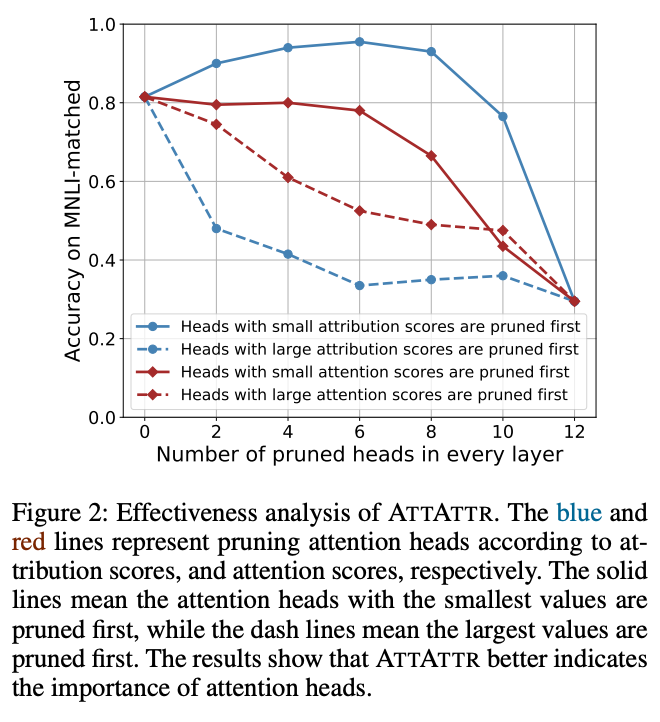
我们发现:
归因得分修剪头部会对模型效果可以产生更显著的影响。 在每一层中只修剪Top2的两个归因分数的头部会导致模型精度的极大降低。相比之下,保留它们有助于模型达到近97%的准确率。即使每层只保留两个heads,模型仍然可以有很强的性能。 和attention分数相比,使用attention分数裁剪heads的影响不是非常明显,这也充分证明了我们方法的有效性。
2.Head Attention的裁剪
1.Head Importance
1.1 Our method
其中表示从held-out几何中采样得到的样本。表示第个attention head的最大attribution值。
1.2. Tylor expansion
其中是关于样本的损失函数,是第个head对应的attention分数。
2.实验对比
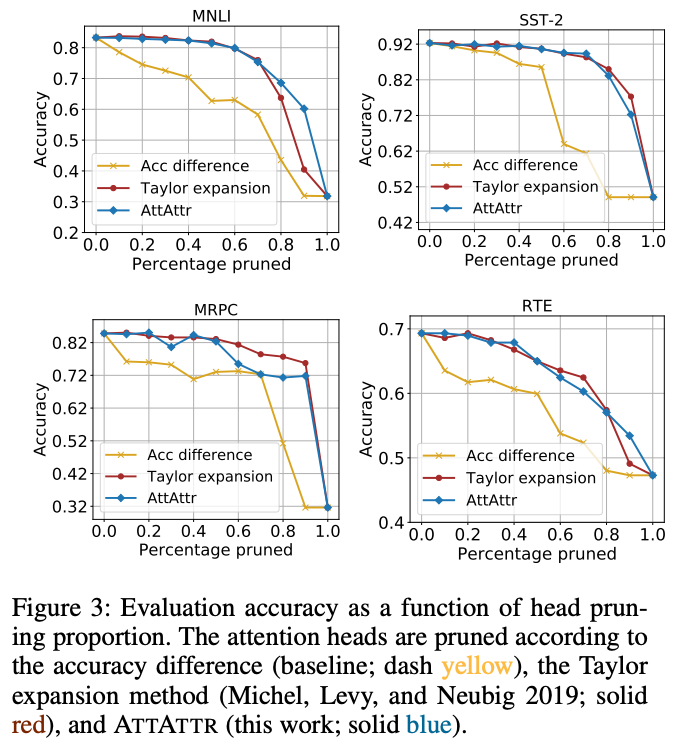
使用我们的方法进行裁剪的效果是最好的。
本文提出了自我注意归因(ATTATTR),它解释了Transformer内部的信息交互,使自我注意机制更易于解释。文章进行了定量分析,证明了ATTATTR的有效性。此外,利用本文提出的方法来识别最重要的注意head,从而提出了一种新的头部剪枝算法。然后利用属性得分得到交互树,从而可视化变压器的信息流。本文的方法非常有参考价值。
往期精彩回顾
本站qq群851320808,加入微信群请扫码: