
1750亿参数,史上最大AI模型GPT-3上线:不仅会写文章、答题,还懂数学
时隔一年,OpenAI 放出的预训练语言模型 GPT-3 再次让人刮目相看。



据《华盛顿邮报》报道,经过两天的激烈辩论,联合卫理公会同意了一次历史性的分裂:要么创立新教派,要么则在神学和社会意义上走向保守。大部分参加五月份教会年度会议的代表投票赞成加强任命 LGBTQ 神职人员的禁令,并制定新的规则「惩戒」主持同性婚礼的神职人员。但是反对这些措施的人有一个新计划:2020 年他们将形成一个新教派「基督教卫理公会」。
《华盛顿邮报》指出,联合卫理公会是一个自称拥有 1250 万会员的组织,在 20 世纪初期是「美国最大的新教教派」,但是近几十年来它一直在萎缩。这次新的分裂将是该教会历史上的第二次分裂。第一次发生在 1968 年,当时大概只剩下 10% 的成员组成了「福音联合弟兄会」。《华盛顿邮报》指出,目前提出的分裂「对于多年来成员不断流失的联合卫理公会而言,来得正是时候」,这「在 LGBTQ 角色问题上将该教派推向了分裂边缘」。同性婚姻并不是分裂该教会的唯一问题。2016 年,该教派因跨性别神职人员的任命而分裂。北太平洋地区会议投票禁止他们担任神职人员,而南太平洋地区会议投票允许他们担任神职人员。





给出新单词「Gigamuru」(表示一种日本乐器)。 GPT-3 给出的句子是:叔叔送了我一把 Gigamuru,我喜欢在家弹奏它。

给出新单词「screeg」(挥剑,击剑)。 GPT-3 造出的句子是:我们玩了几分钟击剑,然后出门吃冰淇淋。



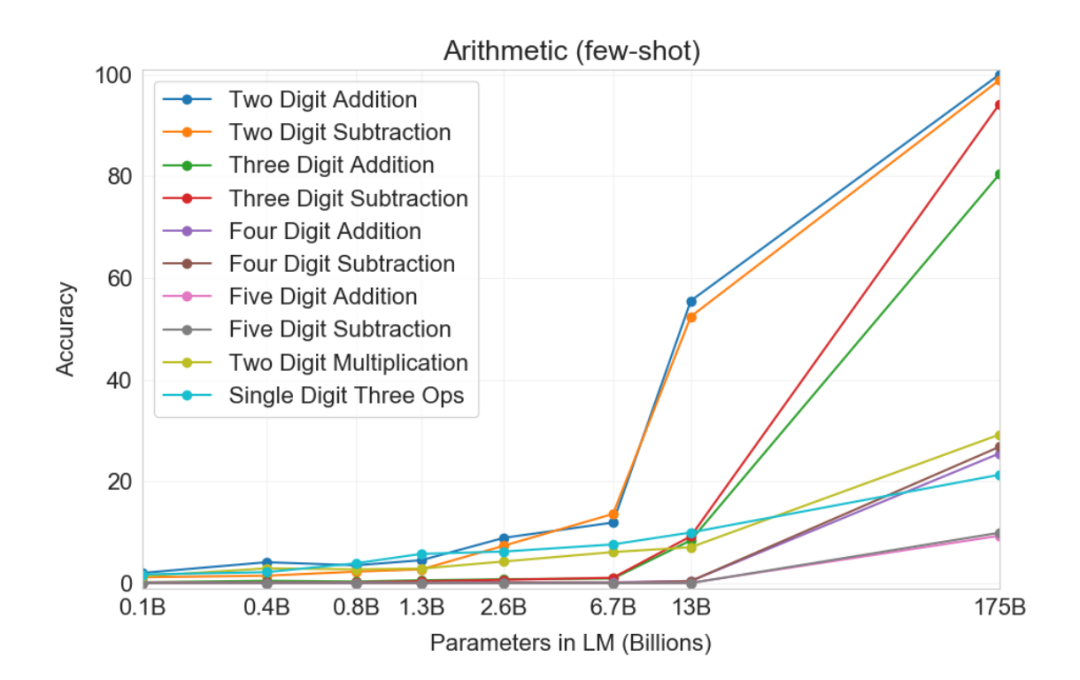
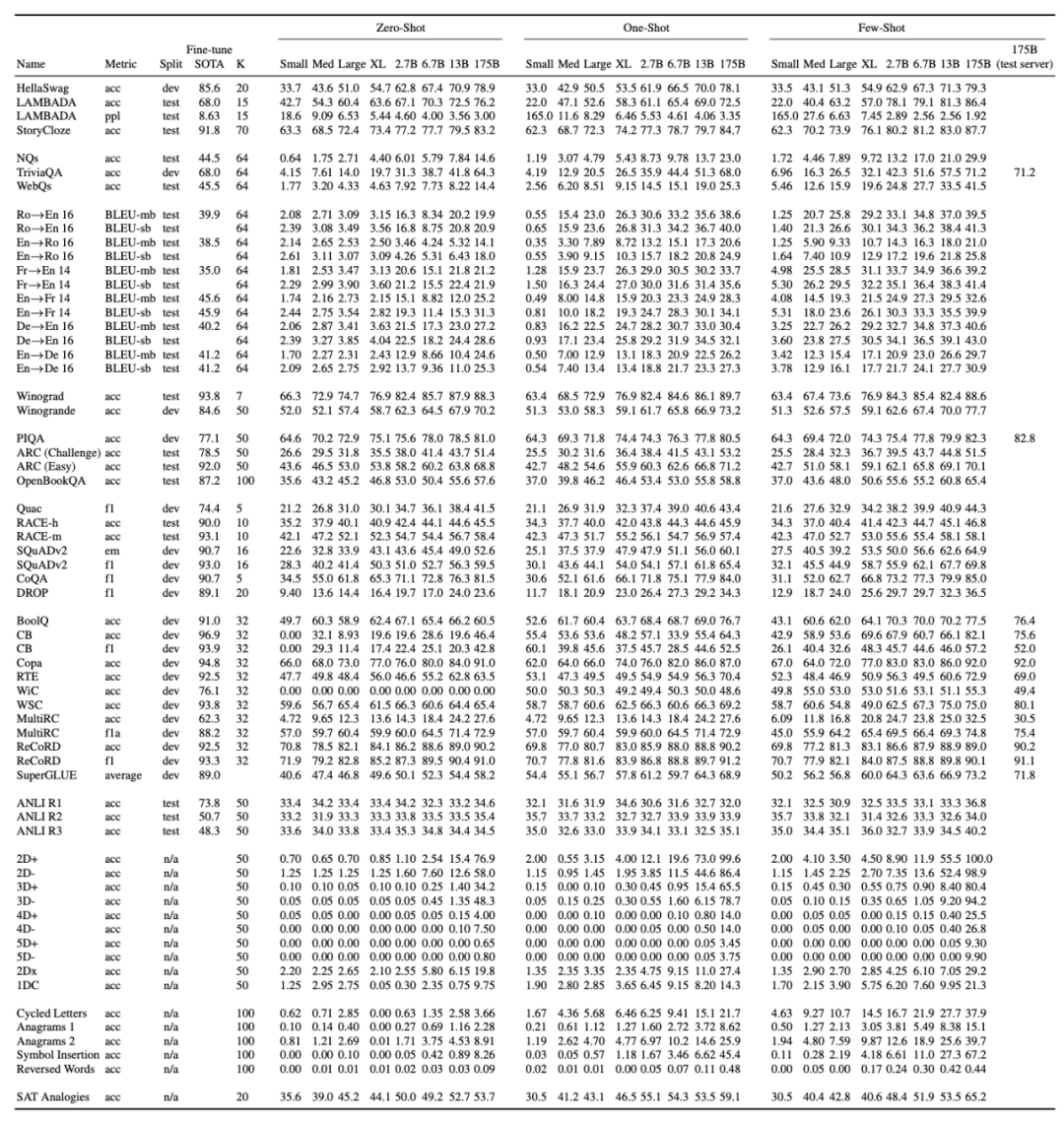
Fine-Tuning (FT):微调是近几年来最为常用的方法,涉及在期望任务的特定数据集上更新经过预训练模型的权重;
Few-Shot (FS):在该研究中指与 GPT-2 类似的,在推理阶段为模型提供少量任务演示,但不允许更新网络权重的情形;
One-Shot (1S):单样本与小样本类似,不同的是除了对任务的自然语言描述外,仅允许提供一个任务演示;
Zero-Shot (0S):零次样本除了不允许有任何演示外与单样本类似,仅为模型提供用于描述任务的自然语言指示。



来源:机器之心
本文版权归原作者所有,如有问题请联系我删除。

评论