
Meta开源1750亿参数GPT-3,打脸OpenAI?网友点评:GPT-4都要来了
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
转自新智元

OpenAI的GPT-3已发布两年,但还是只听说过,没见过。最近Meta复现了一遍GPT-3,改名OPT,把代码、权重、部署都开源了出来,并且还更环保,碳足迹仅为原版七分之一。
2020年,OpenAI放出了具有1750亿参数的预训练模型GPT-3,横扫文本生成领域,不仅能问答、翻译、写文章,还能做数学计算。
唯一的「美中不足」就是没开源,代码和模型看着眼馋,却到不了嘴边。
并且与微软签订了「独占协议」,公众只能通过付费API与模型进行交互,完整的研究访问授权仍然仅限于少数资源丰富的实验室。

直到Meta AI发布了一篇论文,直接复现了一遍GPT-3,效果不输原版,还全开源了出来,从代码、模型到部署,服务一条龙,从此1750亿参数全量GPT-3触手可得。

论文链接:https://arxiv.org/abs/2205.01068
仓库链接:https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
Meta并且还给模型改了个名字OPT,也就是更open的预训练Transformer语言模型,简直是照着OpenAI的脸打呀。

OPT包含了多个尺寸的模型,对于显卡数量囊中羞涩的研究组来说,可以选择最适合自己的模型大小进行研究。
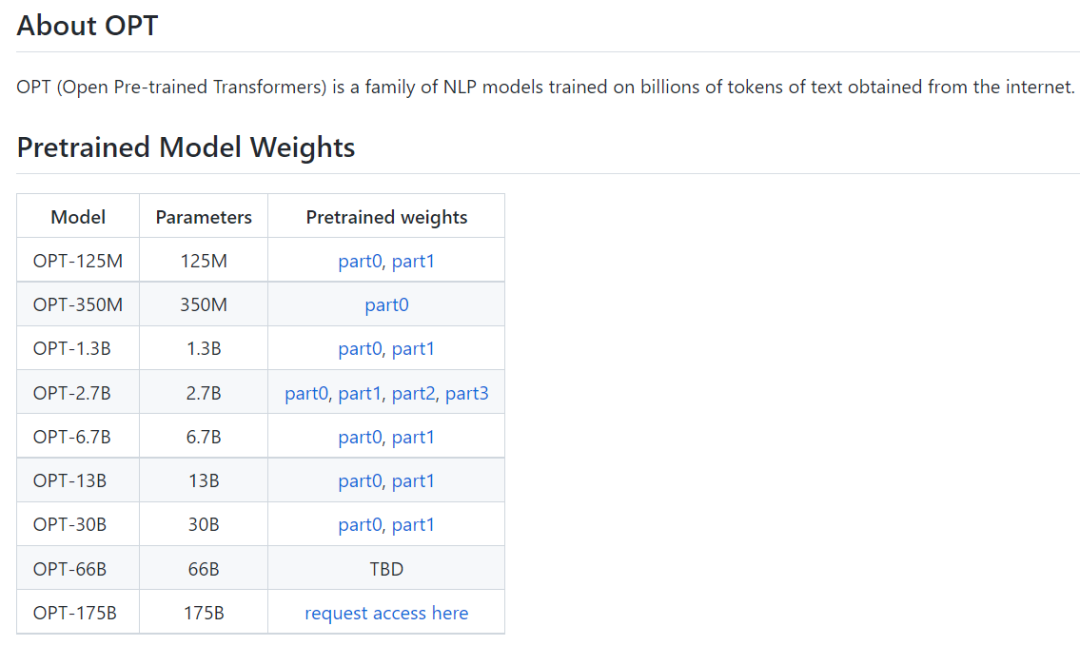
为了防止模型被滥用,Meta AI对于OPT-175B模型加了一个非商业许可,用户需要填写一个申请表,该模型的访问权限将授予学术研究人员;隶属于政府、民间社会和学术界组织的人员;以及世界各地的工业研究实验室。
除了开源外,Meta这次重新训练还很重视「环保」问题。
人工智能的模型训练极其消耗电力,在开发OPT时,Meta表示充分考虑了能源效率,通过全分片数据并行(FSDP)和Nvidia的tensor并行抽象,使得OPT-175B的碳足迹仅为GPT-3的七分之一。

对于开源的原因,MetaAI的董事总经理Joelle Pineau表示,虽然GPT-3现在可以用API访问,但模型的代码和训练参数对于整个研究社区来说显然更重要,OPT-175B的发布也是业界首次开放如此大规模的AI模型,未来将会有更多论文基于可复现的结果发表出来。
不过也有网友指出,想看OpenAI笑话的可以停了,且不说GPT-3已经不是当下最大型的语言模型,OpenAI的GPT-4都快来了。
模型卡片
模型卡片
2018年,计算机科学家Margaret Mitchell提出「模型卡片」概念,通过对模型建立档案,可以让用户了解模型开发的背景及适用条件,提高AI运行的透明度,Meta AI也给OPT建立了一张模型卡片。

论文链接:https://arxiv.org/pdf/1810.03993.pdf
发布日期:2022年5月3日发布OPT-175B
模型版本:1.0.0
模型类型:大型解码Transformer语言模型
不适用的用例:OPT-175B并非发布给生产使用或真实世界部署,OPT-175B和其他大型语言模型一样有多种缺陷,对于商业应用来说还为时过早。
评估数据的选择:除了在公开语言模型标准下评估外,Meta AI还在Hate Speech Detection, CrowS-Pairs, StereoSet等任务上对模型的偏见进行评估。
限制:与其他大型语言模型一样,训练数据的缺乏多样性会对模型的质量产生下游影响,OPT-175B在偏见和安全性方面受到限制。OPT-175B在多样性和幻觉(hallucination)方面也可能存在质量问题。总的来说,OPT-175B对现代大型语言模型的问题并不免疫。通过发放非商业许可证,Meta希望以此提高沟通、透明度,并研究大型语言模型的问题,特别是在不符合商业利益的领域。
数据卡片
数据卡片
训练数据在机器学习中有时比模型更关键,也会从根本上影响模型的行为、产生偏见等,所以记录模型的数据来源、使用方法就显得很重要。2018年,Timnit Gebru在arxiv上提出通过问答形式,为数据集进行建档,最终论文于2021年12月发表。

论文链接:https://arxiv.org/abs/1803.09010
下面为一些相对关键的数据问题。
动机:OPT-175B模型的预训练数据是由五个数据集(RoBERTa用到的三个数据集、Pile的子集以及Pushshift.io Reddit数据集)。创建这个数据库的目的是在广泛的文本语料库上构建预训练语言模型,重点是人工生成的文本。
数据集:
1. BookCorpus,由一万本未发表书籍构成
2. CC-Stories,包含CommonCrawl的一个子集,过滤条件为Winograd模式的story-like风格
3. The Pile包括Pile-CC, OpenWebText2, USPTO, Project Gutenberg, OpenSubtitles, Wikipedia, DM Mathematics, HackerNew
4. Pushshiftio Reddit数据集
5. CCNews V2包含一个更新版本的CommonCrawl News数据集
数据集大小:包括1800亿个Tokens,总计800GB的数据
样例是否包含raw data:是
样例是否包含label:否
数据切分:将200MB的预训练数据划分为验证集
数据收集参与者:数据由机器全自动挖掘、过滤和采样
数据预处理/清洗/标注流程:组件数据经过标准的清理和格式化实践,包括删除重复/非信息性文本,如「Chapter One」或「This ebook by Project Gutenberg」
用爱发电
用爱发电
进入预训练时代以后,AI模型的研发转为基于大公司开源的大规模语言模型。
但能否用上预训练模型,主要取决于大公司是否想做「慈善」,毕竟大模型的训练动辄就是成百上千个GPU,还得搜集海量的训练数据,还得给算法工程师开工资,曾经有人估算,想训练一次5300亿参数量模型的PaLM,光租卡就至少得花900万美元。
而本次OpenAI没有开放GPT-3,而是和微软站队,也是引起了大量从业者的不满,马斯克直言OpenAI跟open越走越远,网友也表示,还不如改名叫ClosedAI算了。
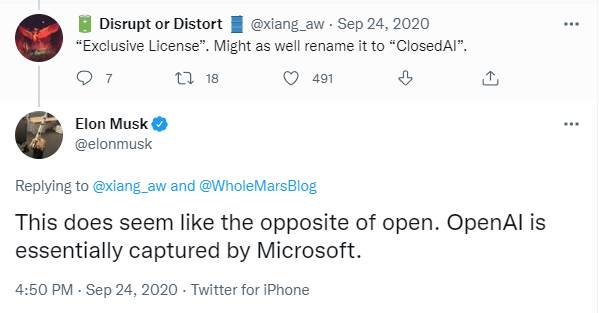
这种受限访问限制了研究人员对大型语言模型的理解和研究,也阻碍了提升鲁棒性、减轻模型偏见、毒性等已知问题的努力。
但如果都免费开源给社区,瞬间就会让大量的竞争对手占领相同的高地,所以开源大模型的行为实属「用爱发电」。
而本次OPT的发布,就属于用爱发电来打破垄断,斯坦福大学基础模型研究中心主任Percy Liang对此评价为:开启了语言模型研究的新机会。

总的来说,开源得越深入,就越能促进深层次问题的研究:
第一层:论文开放,证明一些想法的可行性,提供一些通用的思路;
第二层:API开放,研究人员能够探测、评估模型的能力(如推理)和限制(如偏见)
第三层:模型权重开放,允许研究人员增量改进模型,开发出可解释更好的技术、更有效的微调方法等;训练数据的开放,允许研究人员更好地理解训练数据在模型行为中的作用。
第四层:计算能力开放,允许研究人员尝试新框架,新的训练目标和过程,数据集消融,在不同领域内开发出全新的模型。这些尝试极其消耗计算资源,但也会对模型的理解和提升具有潜在价值。
越高层次的开放,带来的也是更多的风险和不确定性,所以不同的基础模型开发者对于开放策略也有不同的理解。
不过就算Meta把OPT-175B发到手里了,还是得先看看自己有没有16块Nvidia V100显卡。
参考资料:
https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
