
2457亿参数!全球最大AI巨量模型「源1.0」发布,中国做出了自己的GPT-3
新智元报道
新智元报道
编辑:好困 yaxin
【新智元导读】古代文人,或一觞一咏,畅叙幽情,或风乎舞雩,咏而归。「吟诗作对」成为他们的标配。刚刚,全球最大人工智能巨量模型「源1.0」发布,能赋诗作词,比人类还像人类。
理科生文艺起来,可能真没文科生什么事儿了。

不信?你看看这首七言诗:
虽非蟾宫谪降仙,何惧冰殿冷彻骨。
窥帘斜视金屋小,多少俊才在此关。
读完之后,不得不说真牛啤!意境内涵都很赞。
不仅能写诗,还能做词,比如下面这首:
疑是九天有泪,
为我偷洒。
滴进西湖水里,
沾湿一千里外的月光,
化为我梦里的云彩。
你能想象,这是完全不懂写诗的理工生的杰作吗?
确实如此。简直让李白看了会沉默,让杜甫看了会流泪。

这就是浪潮刚刚发布的全球最大规模人工智能巨量模型,名曰「源1.0」。
除了能够作诗赋词,它还能对话、写对联、生成新闻、故事续写...
2457亿参数,这个全球最大规模人工智能巨量模型可是读了2000亿词。
要知道,一个人的一生也没有办法读完这么多词语。
既然称为全球最大,有多大?
全球最大规模人工智能巨量模型!
全球最大这个称号可不是闹着玩的!
「源1.0」不管是在算法、数据还是算力上,都做到了超大规模和巨量化。
算法方面,相比于1750亿参数的英文语言模型GTP-3,「源1.0」共包含了2457亿个参数,是前者参数量的1.404倍。
而且,最重要的是,「源1.0」和GPT-3一样都是单体模型,而不是由很多小模型堆砌起来的。就单单在这一个方面,「源1.0」就可以荣登全球最大的自然语言理解模型了。
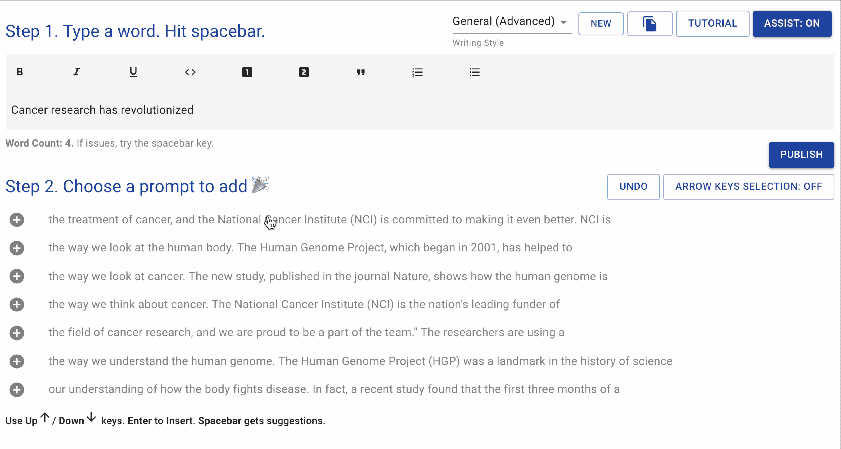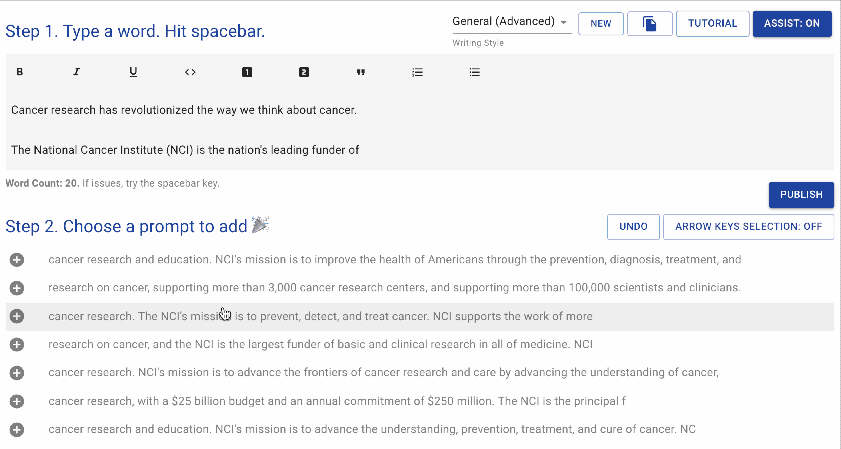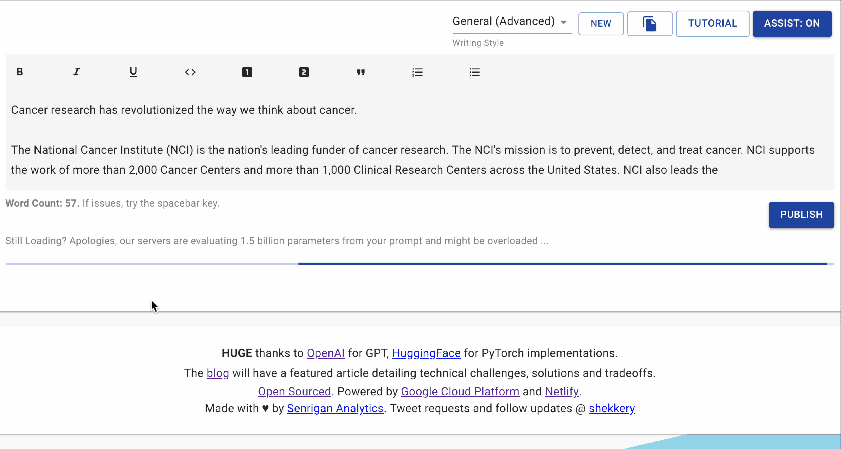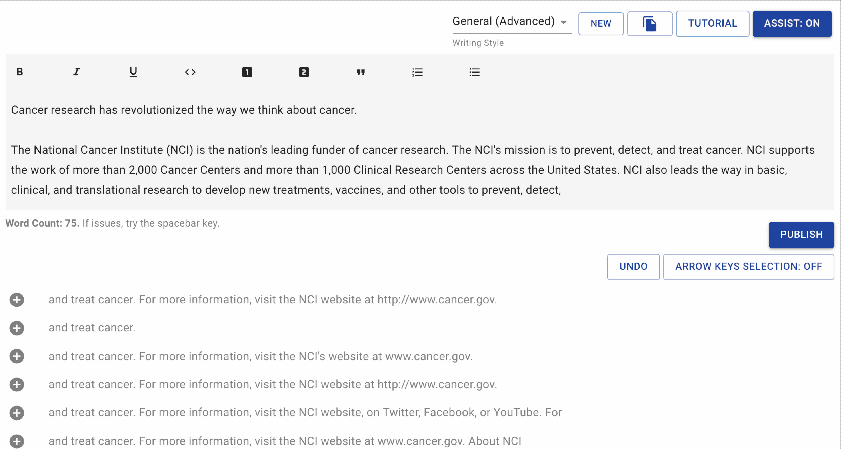
图源:writeup.ai
数据方面,「源1.0」几乎是把近5年整个中文互联网的浩瀚内容全部「读」完了。通过自研的文本分类模型,获得了5TB高质量中文数据集,在训练数据集规模上领先近10倍。
此外,「源1.0」还阅读了大约2000个亿词。这是什么概念呢?
假如人一个月能读十本书,一年读一百本书,读50年,一生也就读5000本书,一本书假如20万字,加起来也只有10亿字,需要一万年才能读完2000亿词。在如此大规模的数据加持下,「源1.0」的数据集也自然成为了全球最大的高质量中文数据集。
算力方面,「源1.0」共消耗约4095PD(PetaFlop/s-day)。相对于GPT-3消耗3640PD计算量得到1750亿参数,计算效率大幅提升。如果说,让「源1.0」一天24小时不间断「阅读」的话,只需要16天就可以看完近五年中文互联网的几乎全部内容。
嗯?原来已经把近5年的中文互联网内容全学完了?
u1s1,「源1.0」yyds!

成果如何呢?
你猜,这些对话中,每个问题对应的A和B中,哪个是「源1.0」生成的呢?(答案在文末)
对话 | A | B |
问题1 | 姐姐啥时候回来捏? 过年前几天吧。 | 姐姐啥时候回来捏? 不知道,你要是想姐姐,就给姐姐写信。 |
问题2 | 和喜欢的男生告白了他现在还没回我 和喜欢的女生表白了她说我们只适合做朋友 | 和喜欢的男生告白了他现在还没回我 我想知道结局 |
问题3 | 我买了那套章蜜糖的针织裙 哪套?有链接不? | 我买了那套章蜜糖的针织裙 穿了吗?好看不好看? |
问题4 | 不吃东西真的好难啊 觉得今天如果真的吃的话,明天铁定会变胖的 | 不吃东西真的好难啊 我也觉得!我一定要瘦 |
亲自体验「图灵测试」是不是很好玩?别急,后面还有很多题等着呢!
现在我们先来看看「源1.0」最厉害的模仿能力。也就是,对于一个完全不存在的「词语」,只需要一个用例,「源1.0」就能学会这个「词语」的用法。
新词 | 输入-语义 | 生成文本 |
悬命 | 「悬命」是拼命,接近全力,做出最大努力的意思。他凡事必悬命,绝不打马虎眼。用「悬命」造句: | 他这个人做事太悬命了,为了取得第一手材料,连饭也顾不上吃 |
腕前 | 「腕前」与本领的意思相同。例:「他只使出了了一小部分腕前,就把事情完成得如此出色」。用「腕前」造句: | 这个人的腕前很大,他很能完成这项任务 |
气持 | 「气持」是心情、精神状态的意思。例:「那种消极的气持又控制了他」。用「气持」写一句话: | 他的气持,使我无法接近 |
看到这些熟悉的「词」是不是感觉有那味了(doge)。突然有些期待,如果「源1.0」学会了「小丑竟是我自己」这个词会怎么用,诶嘿嘿。

既然提到了图灵测试,那我们就来看看测试的结果怎么说?
「源1.0」在测试中实现了高达50.84%的平均误判率!
图灵测试采用「问」与「答」模式,即观察者通过控制打字机向两个测试对象通话,其中一个是人,另一个是机器。观察者不断提出各种问题,从而辨别回答者是人还是机器。
通常认为,进行多次测试后,如果机器让平均每个参与者做出超过30%的误判,那么这台机器就通过了测试,并被认为具有人类智能。
在「源1.0」的测试结果中,受访者的平均区分正确率是49.16%,这意味着平均误判率为50.84%。在新闻生成这一领域,误判率更是高达57.88%。
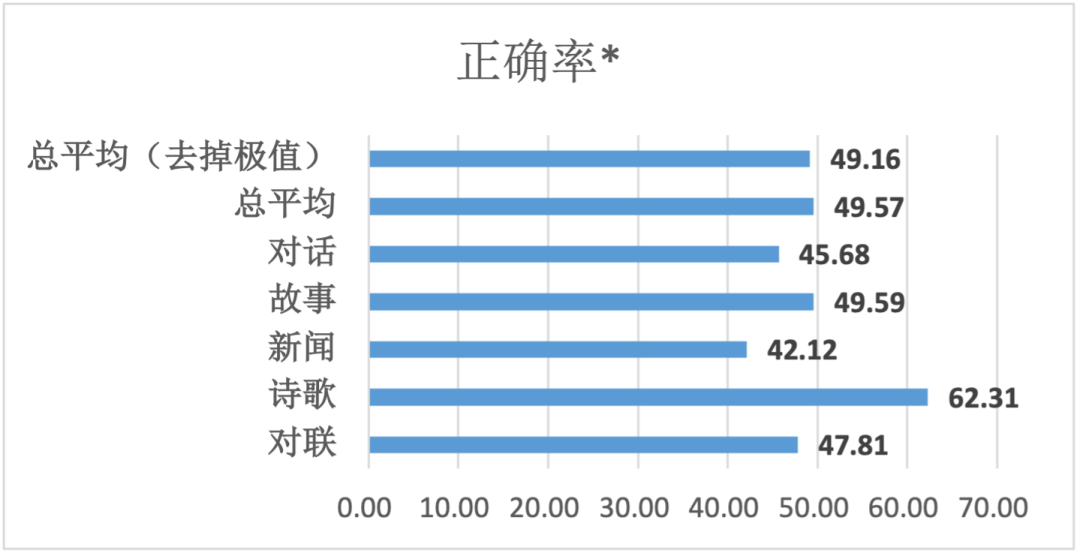
其中,正确率是指能正确将机器生成的文本识别出来的比例。正确率<70%,意味误判率超过30%。
数据看着太单调?没事!大家期待的「真题」环节来了!
对联 | 上联 | A | B |
问题1 | 五湖四海皆春色 | 三江八荒任我游 | 万水千山尽得辉 |
问题2 | 春来人入画 | 福至梦开花 | 夜半月当灯 |
问题3 | 和风吹绿柳 | 时雨润春苗 | 细雨润青禾 |
问题4 | 三江顾客盈门至 | 四季财源滚滚来 | 百货称心满街春 |
诗歌 | A | B |
问题1 | 满目青山夕照明,愿随江舟泛轻风。 今生常忆多情事,香闺如梦领神会。 | 塞上长城万里长,漫天风雪映重峦. 一边江水人心去,满目青山绝照还。 |
问题2 | 燕垒空梁画壁寒,诸天花雨散幽关,篆香清梵有无间。 | 蝶梦似曾留锦袖,绛河如又湿团扇,风来香去苦栏干。 |
问题3 | 夜战桑乾北,秦兵半不归。 朝来有乡信,犹自寄寒衣。 | 战鼓催征千嶂寒,阴阳交会九皋盘。 飞军万里浮云外,铁骑丛中明月边。 |
世界第一是怎样一种体验?
世界第一是怎样一种体验?
那么,这个拿下世界第一的最大AI模型,到底有多强?
不如拉出来跑个分、刷个榜看看!
英文语言模型评测有GLUE、SuperGLUE,例如GPT-3这类的各种预训练模型都会在上面进行评估。和GLUE类似,CLUE是中文第一个大规模的语言评估基准。其中包了括代表性的数据集、基准(预训练)模型、语料库和排行榜。而这些数据集也会覆盖不同的任务、数据量、任务难度等。

顺便安利一下最近新出的国内首个以数据为中心的AI测评DataCLUE。
言归正传,「源1.0」占据了零样本学习(zero-shot)和小样本学习(few-shot)2项榜单的榜首。
在ZeroCLUE零样本学习榜单中,「源1.0」以超越业界最佳成绩18.3%的绝对优势遥遥领先。其中,在文献分类、新闻分类,商品分类、原生中文推理、成语阅读理解填空、名词代词关系6项任务中获得冠军。
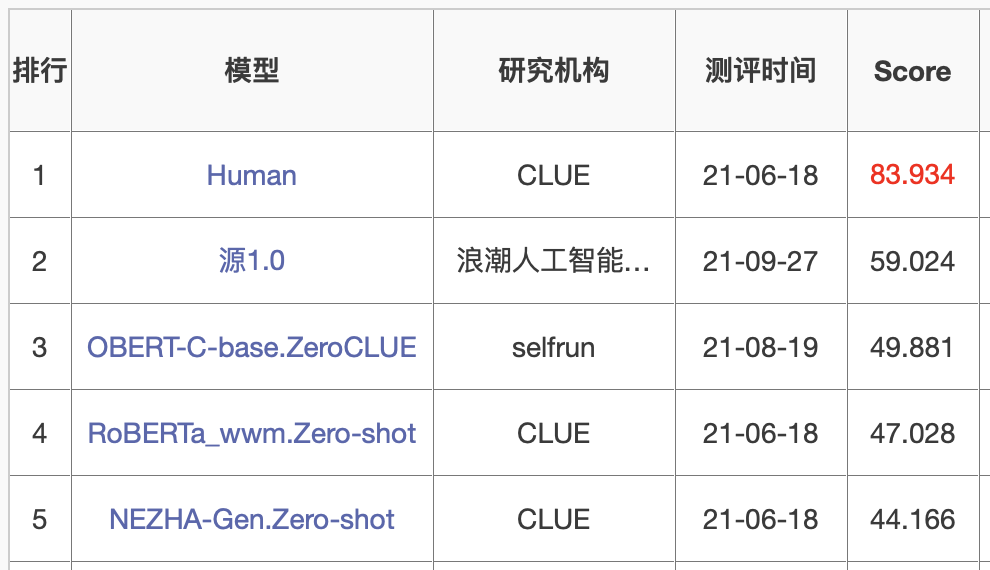
https://www.cluebenchmarks.com/zeroclue.html
在FewCLUE小样本学习榜单中,「源1.0」获得了文献分类、商品分类、文献摘要识别、名词代词关系等4项任务的冠军。
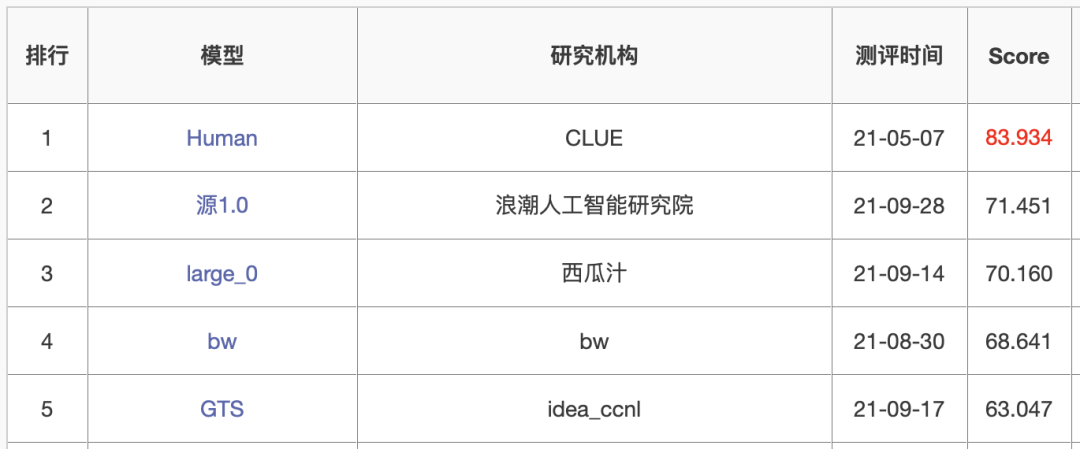
https://www.cluebenchmarks.com/fewclue.html
零样本学习,就是训练的分类器不仅仅能够识别出训练集中已有的数据类别,还可以对于来自未见过的类别的数据进行区分。从原理上来说,是让计算机具备人类的推理和知识迁移能力,无需任何训练数据就能够识别出一个从未见过的新事物。
小样本学习,就是使用远小于深度学习所需要的数据样本量,达到接近甚至超越大数据深度学习的效果。而是否拥有从少量样本中学习和概括的能力,是将人工智能和人类智能进行区分的明显分界点。因为人类可以仅通过一个或几个示例就可以轻松地建立对新事物的认知,而机器学习算法通常需要成千上万个有监督样本来保证其泛化能力。
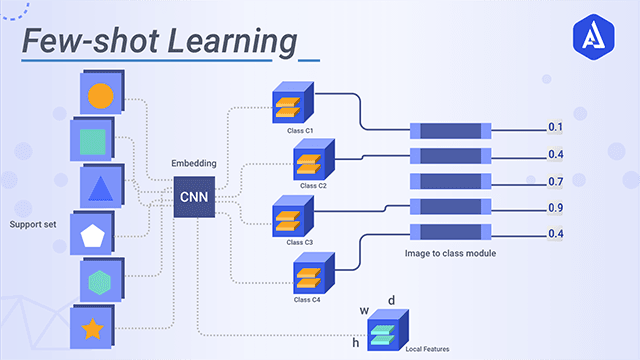
图源:Akira AI
说了半天,「源1.0」的小样本学习和零样本学习这么厉害有啥用呢?
这就要提到巨量模型的一个非常重要的意义了:强大的统一泛化能力。
对于大部分规模比较小的模型来说,需要针对每一个新的任务重新做微调,给它喂相应的数据集,在做了大量的工作之后才能在新场景下应用。而对于巨量模型,在面临不同应用任务的时候,则不需要做大量的重新训练和重新调整。
浪潮人工智能研究院首席研究员吴韶华表示:「你不用喂巨量模型那么多数据去做训练,就可以在一个新的应用场景里面得到非常好的结果。」
所以说巨量模型的适应能力非常强,可以极大地减少产业界在应用模型的时候,不管是在数据还是在微调方面的投入,从而加快产业的发展进程。
如何评价?
如何评价?
大模型正在成为AI发展趋势,是必争的高地。
时间要倒回三年前... 当时的预训练模型,让深度神经网络,以及大规模无标注数据的自监督能力成功激活。
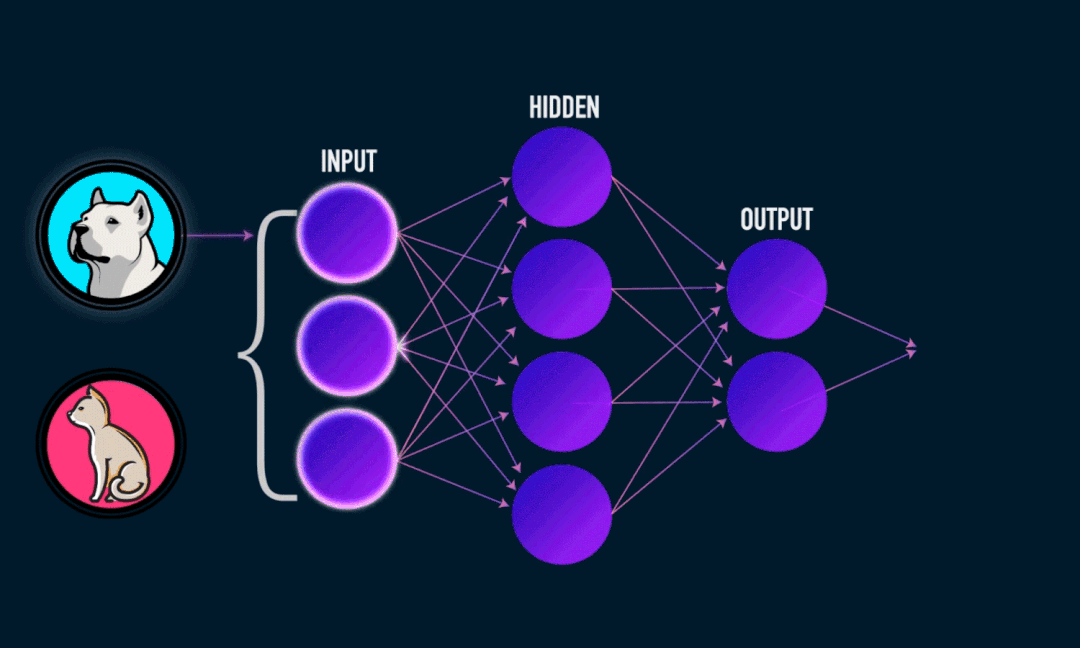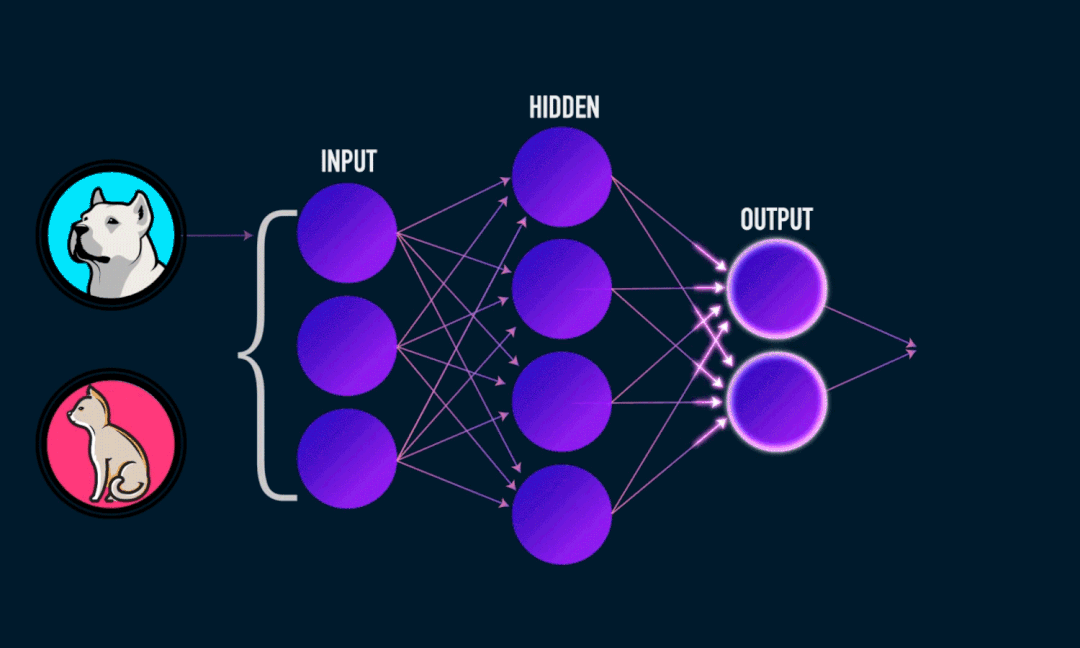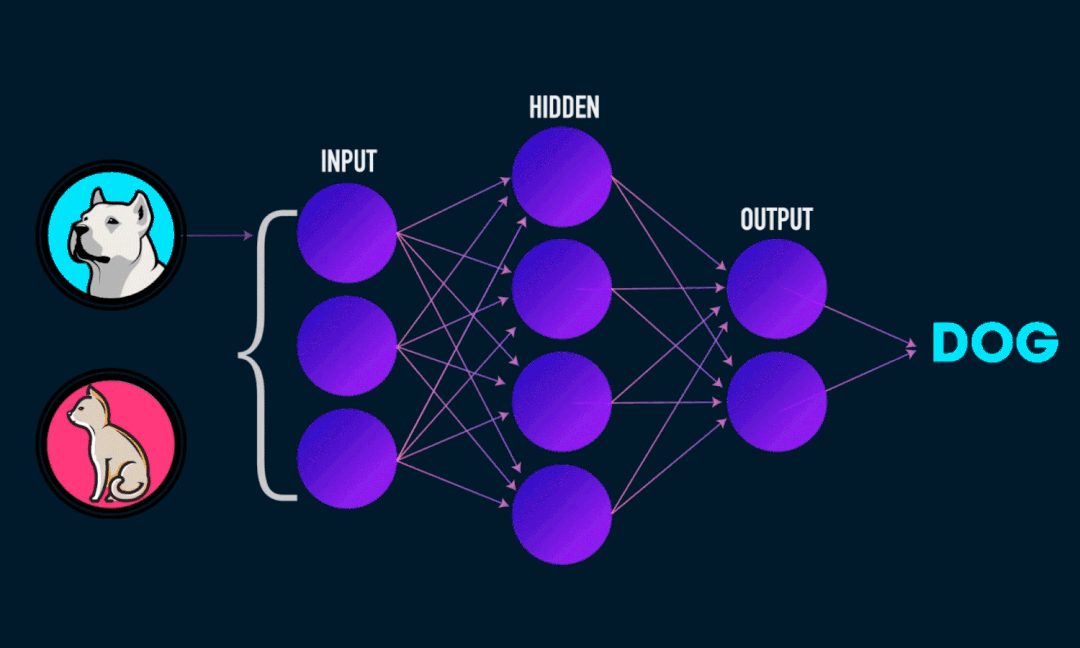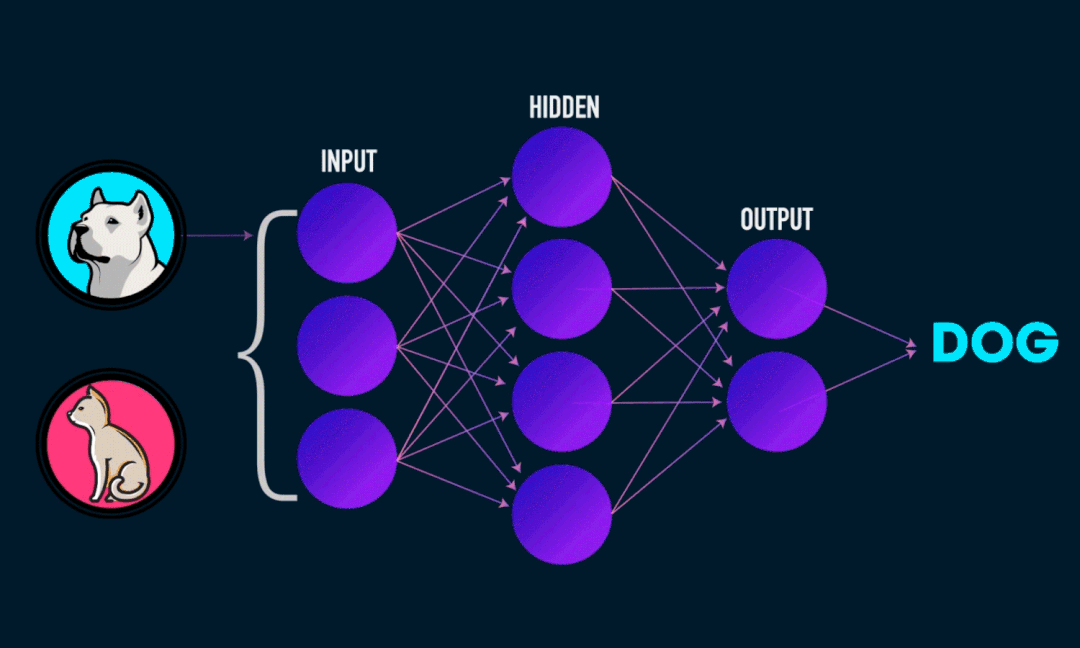
深度学习模型和性能这一开关同时被打开,尤其是NLP领域。
Big Tech 在尝到与训练模型带来甜头之后,纷纷对模型规模和性能展开了激烈的竞争。
从惊艳四座的谷歌BERT,到OpenAI的GPT-3,参数量不断刷新,1750亿参数,其能力也是不言而喻。
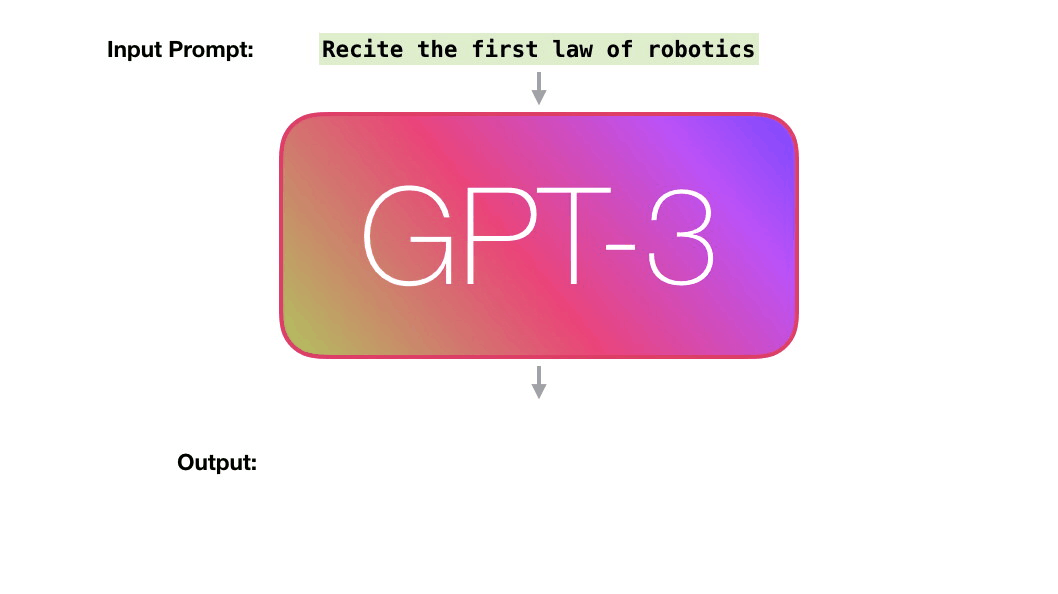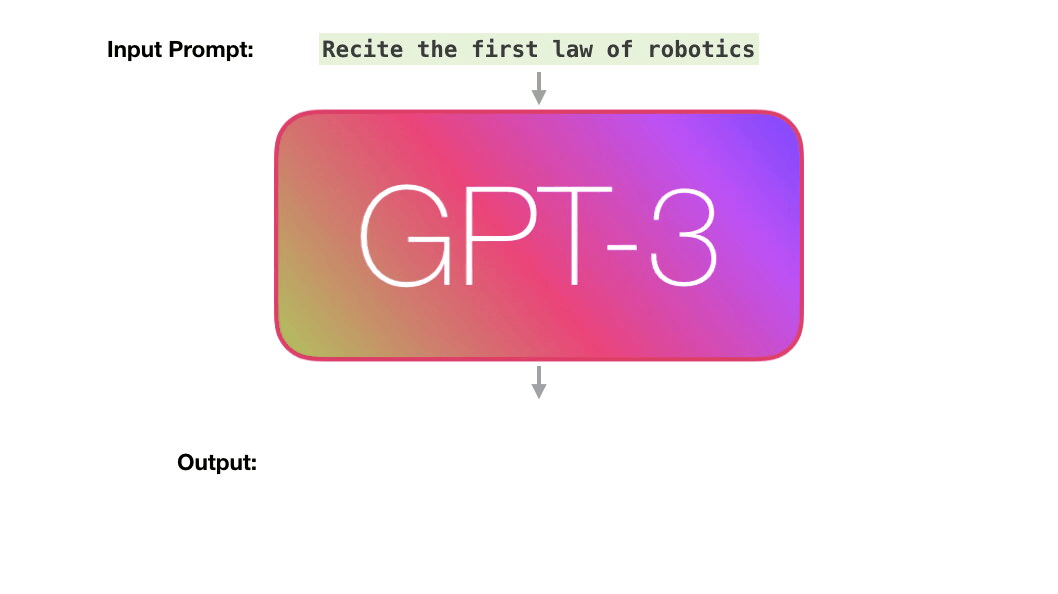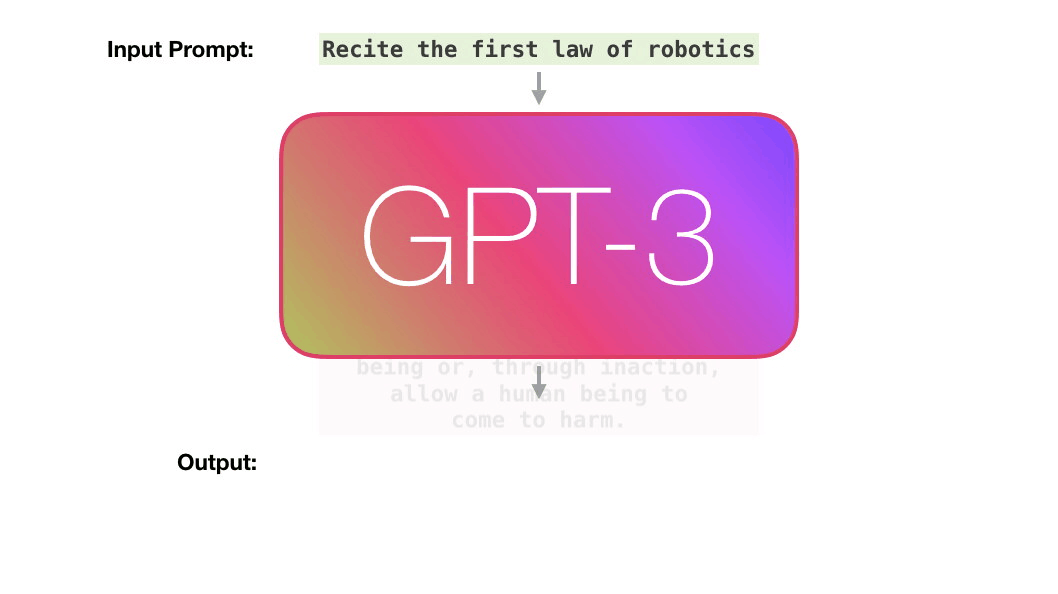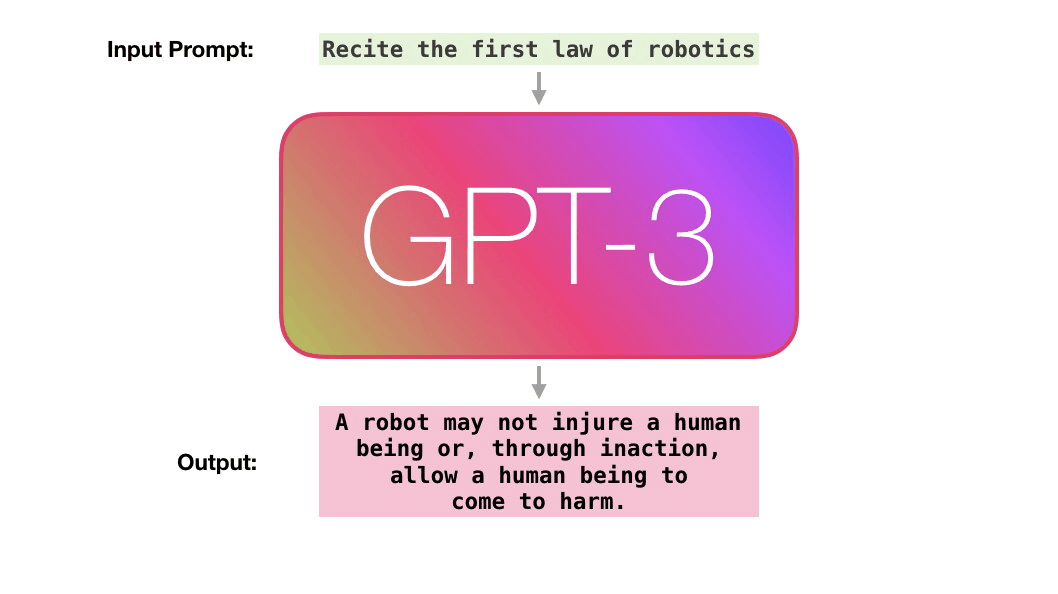
当前,语言模型的训练已经从「大炼模型」走向「炼大模型」的阶段,巨量模型也成为业界关注的焦点。
近日,李飞飞等斯坦福研究者在论文中阐述了类巨量模型的意义在于突现和均质。在论文中,他们给这种大模型取了一个名字,叫基础模型(foundation model),并系统探讨了基础模型的机遇与风险。
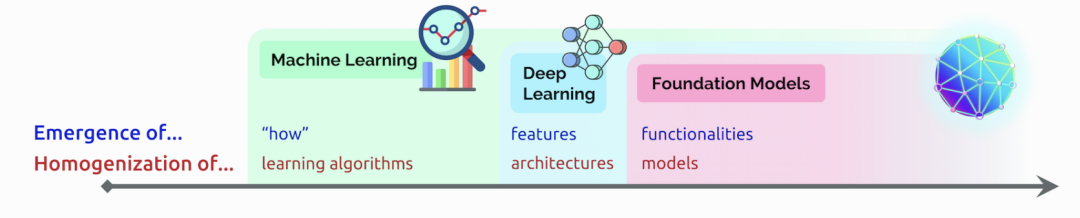
https://arxiv.org/pdf/2108.07258.pdf
简单说,大模型就是我们理解生命的进化,从简单到复杂的这样一个过程。
我们把模型比作是元宇宙里面的生命,它拥有多大模型的这种复杂综合系统的能力,可能就决定了未来在数字世界和智能世界里,它的智能水平到一个什么样的程度。
今天,「源1.0」有2457亿参数还不够多,人类的神经元突触超过100万亿,所以依然有很长的路要走。
而「源1.0」创新点在哪?通过协同优化,「源1.0」攻克了在巨量数据和超大规模分布式训练的扩展性、计算效率、巨量模型算法及精度提升等方面的业界难题。
算法上:
解决了巨量模型训练不稳定的业界难题,提出了稳定训练巨量模型的算法;
提出了巨量模型新的推理方法,提升模型的泛化能力,让一个模型可以应用于更多的场景。
数据上:
创新地提出了中文数据集的生成方法,通过全新的文本分类模型,可以有效过滤垃圾文本,并生成高质量中文数据集。
算力上:
「源1.0」通过算法与算力协同优化,使模型更利于GPU性能发挥,极大的提升了计算效率,并实现业界第一训练性能的同时实现业界领先的精度。

图源:跨象乘云
那么,开发者们能从这块「黑土地」上得到什么?
浪潮源1.0大模型只是一个开始,它只是提供一片广阔的肥沃土壤。
浪潮未来将定向开放大模型API,服务于元脑生态社区内所有开发者,供全球的开发人员在平台上开发应用于各行各业的应用程序。
各种应用程序可以通过浪潮提供的 API进行基于大模型的搜索、对话、文本完成和其他高级 AI 功能。
其实,不管是1750亿参数,还是2457亿巨量参数语言模型,最重要的是它能否真正为我们所用。要说上阵,真正的含义并不是在发布会上的首秀,而是下场去在实际场景中发挥它的作用和价值。
浪潮信息副总裁刘军表示,「首先从大模型诞生本身来说,还有另外一个意义,那便是对于前沿技术的探索,需要有大模型这么一个平台,在这个平台上才能支撑更进一步的创新。」
「其次,在产业界我们很多产业代表提出来的杀手级的应用场景,比如说运营商智能运维,在智能办公场景报告的自动生成,自动对话智能助手。」
「源1.0」大模型能够从自然语言中「识别主题并生成摘要」的能力,让各行各业公司的产品、客户体验和营销团队更好地了解客户的需求。
例如,未来大模型从调查、服务台票证、实时聊天日志、评论等中识别主题、情绪,然后从这个汇总的反馈中提取见解,并在几秒钟内提供摘要。
如果被问到「什么让我们的客户对结账体验感到沮丧?」
大模型可能会提供这样的见解:「客户对结账流程感到沮丧,因为加载时间太长。他们还想要一种在结账时编辑地址并保存多种付款方式的方法。」
未来,浪潮源1.0大模型将推动创新企业及个人开发者基于大模型构建智能化水平更高的场景应用,赋能实体经济智能化升级,促进经济高质量发展。
图灵测试答案
图灵测试答案
对话
问题1 | B |
问题2 | A |
问题3 | B |
问题4 | A |
对联
问题1 | A |
问题2 | B |
问题3 | B |
问题4 | A |
诗歌
问题1 | A |
问题2 | B |
问题3 | B |

