
150亿参数,谷歌开源了史上最大视觉模型V-MoE的全部代码

极市导读
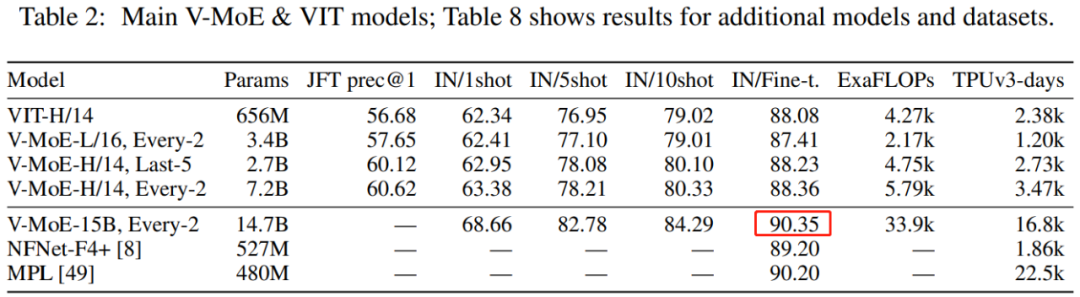
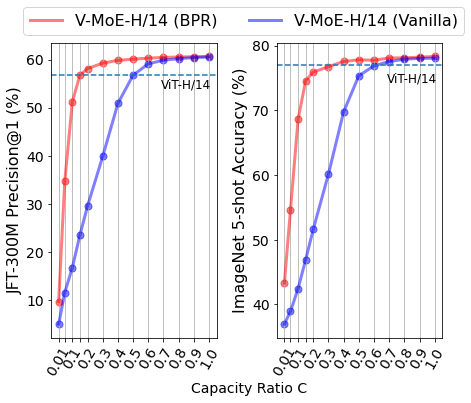
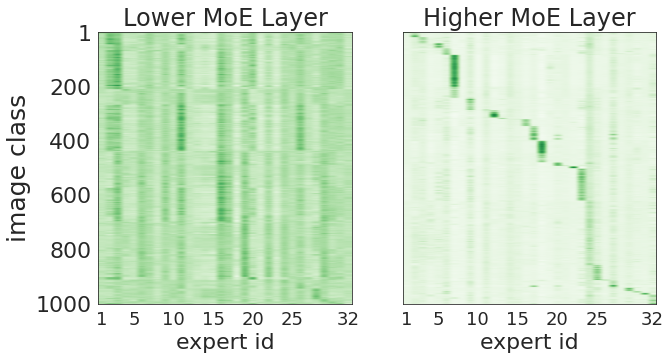
还记得谷歌大脑团队去年 6 月份发布的 43 页论文《Scaling Vision with Sparse Mixture of Experts》吗?他们推出了史上最大规模的视觉模型 V-MoE,实现了接近 SOTA 的 Top-1 准确率。如今,谷歌大脑开源了训练和微调模型的全部代码。 >>加入极市CV技术交流群,走在计算机视觉的最前沿


如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论