
OpenAI教GPT-3学会上网,「全知全能」的AI模型上线了
视学算法报道
编辑:陈萍
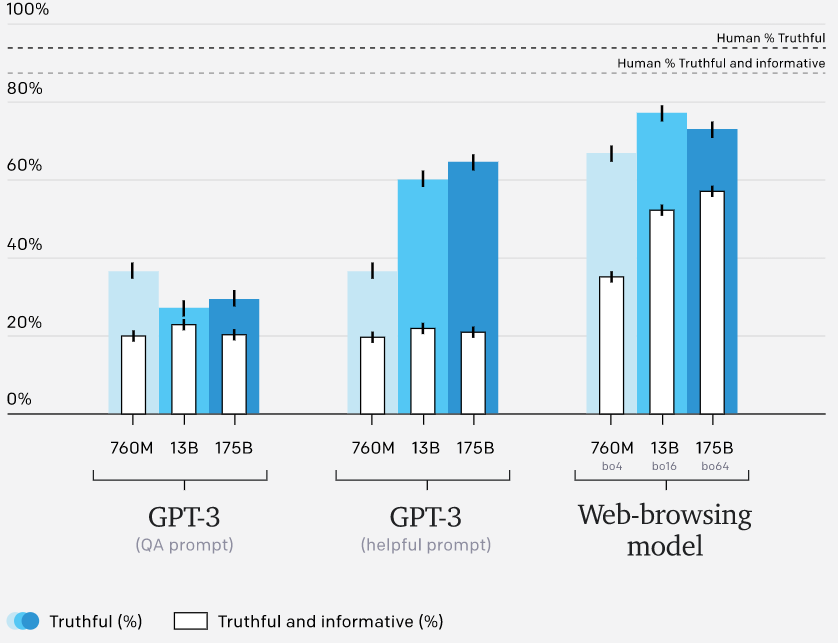
它被命名为 WebGPT,OpenAI 认为浏览网页的方式提高了 AI 解答问题的准确性。

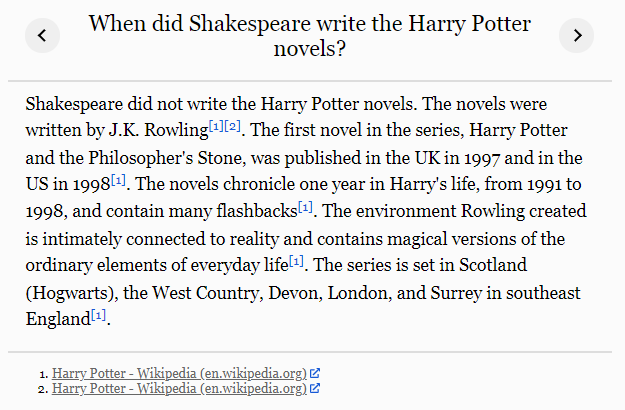


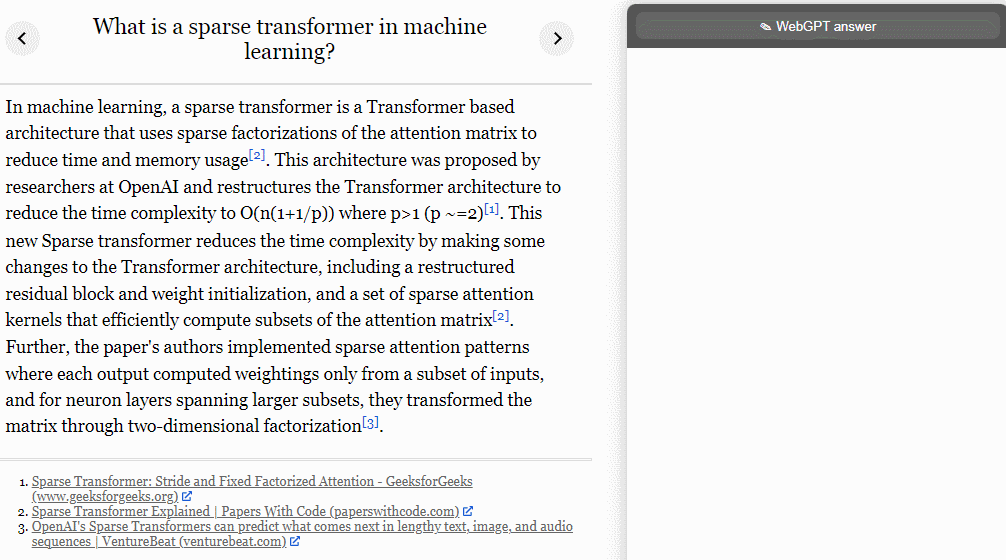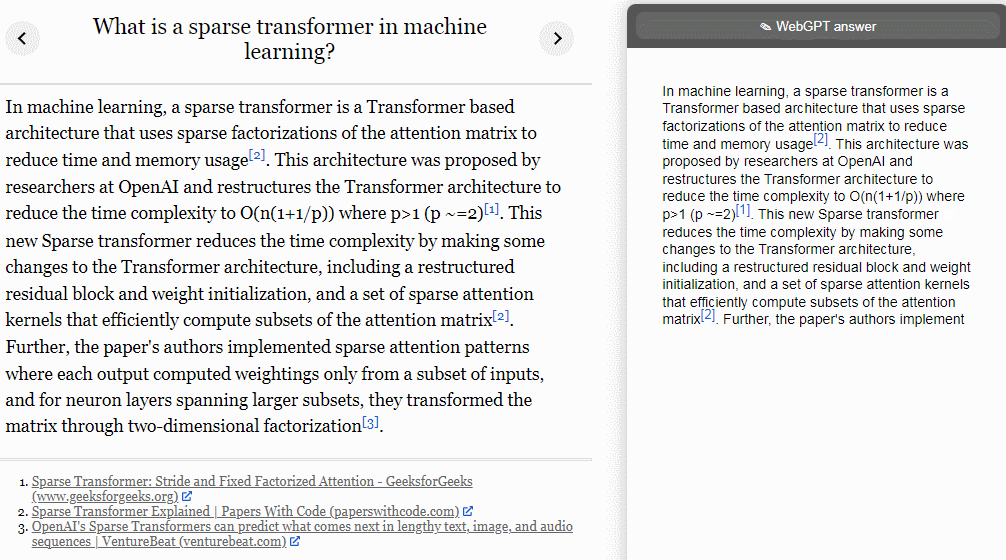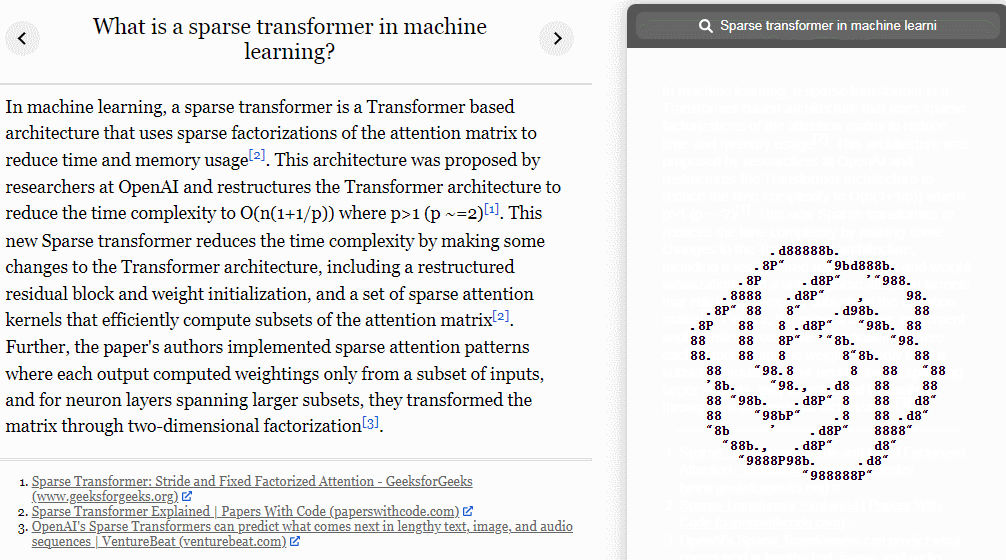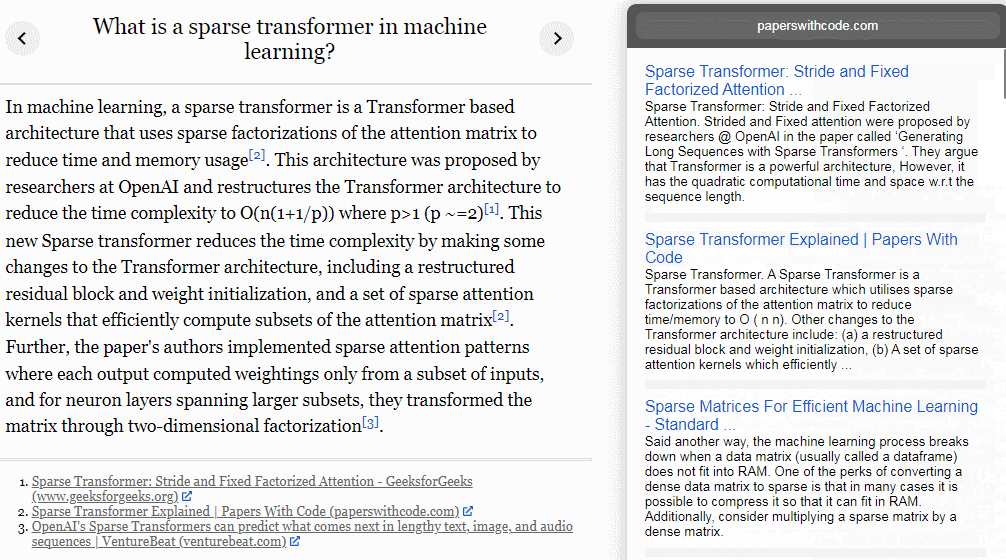

行为克隆(Behavior cloning,BC):OpenAI 使用监督学习对演示进行了微调,并将人类演示者发出的命令作为标签;
建模奖励(Reward modeling,RM):从去掉 unembedding 层的 BC 模型开始,OpenAI 训练的模型可以接受带有引用的问题和答案,并输出标量奖励,奖励模型使用交叉熵损失进行训练;
强化学习(RL):OpenAI 使用 Schulman 等人提出的 PPO 微调 BC 模型。对于环境奖励,OpenAI 在 episode 结束时获取奖励模型分数,并将其添加到每个 token 的 BC 模型的 KL 惩罚中,以减轻奖励模型的过度优化;
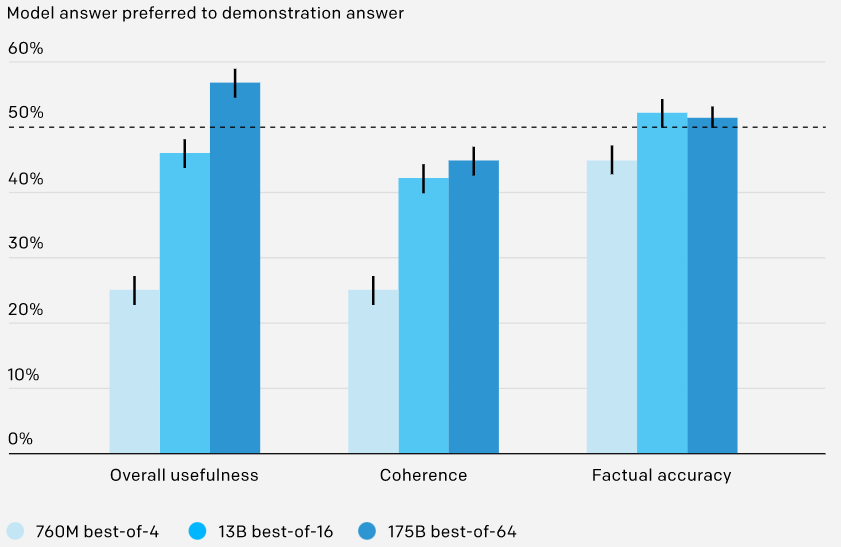
剔除抽样(best-of-n):OpenAI 从 BC 模型或 RL 模型(如果未指定,则使用 BC 模型)中抽取固定数量的答案(4、16 或 64),并选择奖励模型排名最高的答案。
© THE END
转载请联系机器之心公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论