
3D点云初探:基于全卷积神经网络实现3D物体识别
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
在当今的计算机视觉系统中,2D图像识别技术已经相对成熟,但3D物体识别依然是一个关键但未被充分利用的领域。本文将基于百度的飞浆围绕3D点云的物体识别展开叙述。
一、从2D图像识别到3D物体识别
二维图像是由一个个像素点组成的,这些像素点可以用数字来进行表示,例如MINIST数据集里的一张图像,可以用一个28×28的二维矩阵来表示:

将图像作为一个二维矩阵输入到神经网络中,可以得到一个输出结果,这个结果便是对该图像的识别结果:

对于一个3D点云物体来说,其每个点都包含了x、y和z轴的坐标信息,对应的坐标信息其实也可以表示成二维矩阵:
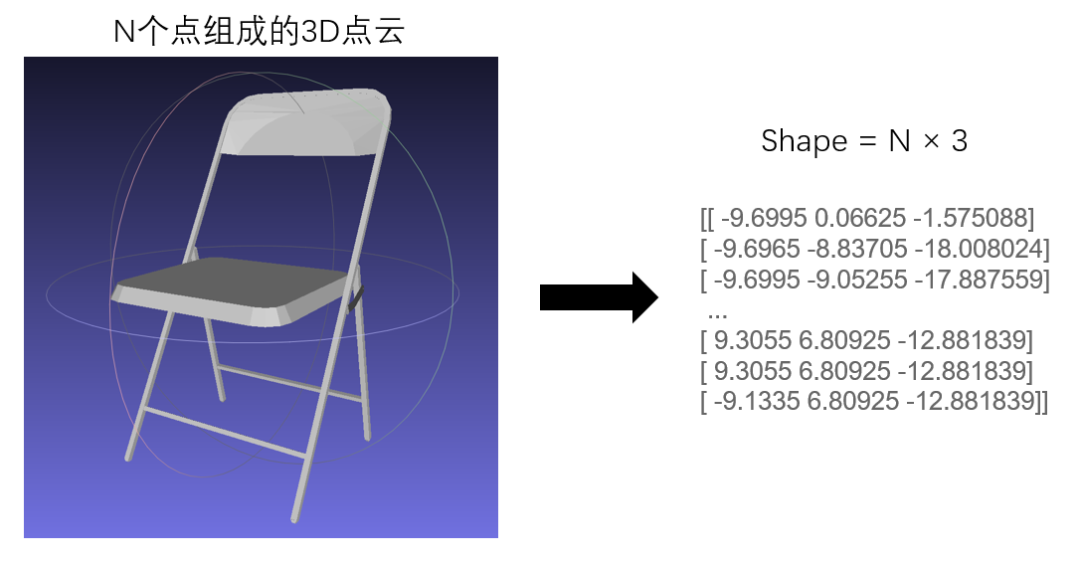
既然都是二维矩阵,那么3D物体的识别便可以借鉴2D图像识别的思想来实现。
二、ModelNet10:3D CAD数据集
该数据集包含浴缸、床、椅子、桌子等10类CAD家具模型。
1.存储格式
图像文件的后缀一般是.jpg或.png;对于三维物体文件来说,通常使用.off文件进行保存,off是object file format的缩写,即物体文件格式的简称。其文件格式如下:
OFF面片数 边数# 以下是顶点坐标x y zx y z...# 以下是每个面的顶点的索引和颜色顶点1的索引 顶点2的索引 … 顶点n的索引 RGB颜色表示...
比如常见的立方体格式为:
OFF8 6 121.0 0.0 1.41420.0 1.0 1.4142-1.0 0.0 1.41420.0 -1.0 1.41421.0 0.0 0.00.0 1.0 0.0-1.0 0.0 0.00.0 -1.0 0.04 0 1 2 3 255 0 0 #red4 7 4 0 3 0 255 0 #green4 4 5 1 0 0 0 255 #blue4 5 6 2 1 0 255 04 3 2 6 7 0 0 2554 6 5 4 7 255 0 0
该文件的第一行8 6 12 代表有8个顶点,6个面和12条边;后面8行代表8个顶点的坐标;最后6行是6个面的上的顶点的索引和颜色。
2.读取方法
.off文件在Python中不需要额外解析,只需要正常打开逐行读取分析信息即可。
# 解压数据集!unzip -oq /home/aistudio/data/data108288/ModelNet10.zip
import numpy as npfilename="ModelNet10/chair/train/chair_0001.off"f = open(filename, 'r')f.readline() # 第一行为OFF,跳过num_views, num_groups, num_edges = map(int, f.readline().split())print("该文件有{}个顶点,{}个面和{}条边".format(num_views, num_groups, num_edges))view_data = [] # 保存所有顶点的坐标信息for view_id in range(num_views):view_data.append(list(map(float, f.readline().split())))views = np.array(view_data)print("所有顶点的坐标信息:\n{}".format(views))f.close()
该文件有2382个顶点,2234个面和0条边
所有顶点的坐标信息:
[[ -9.6995 0.06625 -1.575088]
[ -9.6965 -8.83705 -18.008024]
[ -9.6995 -9.05255 -17.887559]
...
[ 9.3055 6.80925 -12.881839]
[ 9.3055 6.80925 -12.881839][ -9.1335 6.80925 -12.881839]]
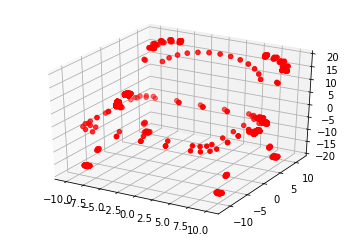
3.点云可视化
为了直观地检查3D点云物体,可以通过可视化的方法进行验证。
可视化工具
MeshLab:https://www.meshlab.net/#download
MeshLab是一个用于处理和编辑三维点云的开源工具,通过它可以很方便地对.off文件进行可视化。
plt可视化
为了更方便地可视化3D点云文件,可以使用plt进行可视化。
import numpy as npfrom mpl_toolkits import mplot3d%matplotlib inlineimport matplotlib.pyplot as pltimport numpy as np# 单独保存每个点的三维坐标zdata = []xdata = []ydata = []for point in views:xdata.append(point[0])ydata.append(point[1])zdata.append(point[2])xdata = np.array(xdata)ydata = np.array(ydata)zdata = np.array(zdata)# 3D点云可视化ax = plt.axes(projection='3d')ax.scatter3D(xdata, ydata, zdata, c='r')plt.show()

4.数据集定义
可以使用飞桨提供的paddle.io.Dataset基类,来快速实现自定义数据集。
import ostrainList = open("trainList.txt", "w") # 训练集testList = open("testList.txt", "w") # 测试集for root, dirs, files in os.walk("ModelNet10"):for file in files:if file.endswith(".off"):if "train" in root:trainList.writelines(os.path.join(root, file) + "\n")elif "test" in root:testList.writelines(os.path.join(root, file) + "\n")trainList.close()testList.close()
这里说明一下数据处理的思路。在做手写数字识别时,可以把二维矩阵每一行首尾相接,变成一维矩阵;同理,三维物体也可以把三个轴的坐标分别拿出来,变成一维矩阵。
import osimport numpy as npimport paddlefrom paddle.io import Datasetcategory = {'bathtub': 0,'bed': 1,'chair': 2,'desk': 3,'dresser': 4,'monitor': 5,'night_stand': 6,'sofa': 7,'table': 8,'toilet': 9}def ThreeDFolder(DataList):filenameList = open(DataList, "r")AllData = []for filename in filenameList:f = open(filename.split('\n')[0], 'r')f.readline() # 第一行为OFF,跳过num_views, num_groups, num_edges = map(int, f.readline().split())view_data = [] # 保存所有顶点的坐标信息for view_id in range(num_views):view_data.append(list(map(float, f.readline().split())))# 单独保存每个点的三维坐标zdata = []xdata = []ydata = []for point in view_data:xdata.append(point[0])ydata.append(point[1])zdata.append(point[2])xdata = np.array(xdata)ydata = np.array(ydata)zdata = np.array(zdata)data = np.array([xdata, ydata, zdata])label = np.array(category[filename.split('/')[1]])AllData.append([data, label])f.close()return AllDataclass ModelNetDataset(Dataset):"""步骤一:继承paddle.io.Dataset类"""def __init__(self, mode="Train"):"""步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集"""super(ModelNetDataset, self).__init__()train_dir = '/home/aistudio/trainList.txt'test_dir = '/home/aistudio/testList.txt'self.mode = modetrain_data_folder = ThreeDFolder(DataList = train_dir)test_data_folder = ThreeDFolder(DataList = test_dir)if self.mode == "Train":self.data = train_data_folderelif self.mode == "Test":self.data = test_data_folderdef __getitem__(self, index):"""步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)"""data = np.array(self.data[index][0]).astype('float32')label = np.array([self.data[index][1]]).astype('int64')return data, labeldef __len__(self):"""步骤四:实现__len__方法,返回数据集总数目"""return len(self.data)train_dataset = ModelNetDataset(mode="Train")test_dataset = ModelNetDataset(mode="Test")
查看第一条数据,这是一个用3×N矩阵((3表示x、y和z轴;N表示N个坐标点))表示的3D物体:
print(train_dataset[0])(array([[ 35.3296 , 30.6052 , 35.3296 , ..., 3.9075 , 4.1437 ,
4.1437 ],
[-89.62712, -89.62712, -89.62712, ..., 93.29006, 93.61506,
93.61506],
[ 16.1253 , 14.3143 , 14.3143 , ..., 14.4374 , 18.3374 ,14.4374 ]], dtype=float32), array([0]))
三、模型组网与训练
在模型组网时,整体思路如下所示:
1.全卷积神经网络
全卷积神经网络,字面意思,就是只有卷积层的网络,因为没有线性变换层,因此可以接受任意大小的输入。
3D点云文件中,不同物体,其坐标点的个数是不同的,因此全卷积神经网络在处理这类问题时有很大的优势。
import paddleimport paddle.nn.functional as Fclass Block1024(paddle.nn.Layer):def __init__(self):super(Block1024, self).__init__()self.pool = paddle.nn.AdaptiveAvgPool1D(output_size=1024)def forward(self, inputs):x = F.sigmoid(inputs)x = self.pool(x)return xclass Block512(paddle.nn.Layer):def __init__(self):super(Block512, self).__init__()self.pool = paddle.nn.AdaptiveAvgPool1D(output_size=512)def forward(self, inputs):x = F.sigmoid(inputs)x = self.pool(x)return xclass Block256(paddle.nn.Layer):def __init__(self):super(Block256, self).__init__()self.pool = paddle.nn.AdaptiveAvgPool1D(output_size=256)def forward(self, inputs):x = F.sigmoid(inputs)x = self.pool(x)return xclass Block128(paddle.nn.Layer):def __init__(self):super(Block128, self).__init__()self.pool = paddle.nn.AdaptiveMaxPool1D(output_size=10)def forward(self, inputs):x = F.sigmoid(inputs)x = self.pool(x)return xclass BlockOut(paddle.nn.Layer):def __init__(self):super(BlockOut, self).__init__()self.conv = paddle.nn.Conv1D(in_channels=10, out_channels=1, kernel_size=3)self.pool = paddle.nn.AdaptiveAvgPool1D(output_size=10)def forward(self, inputs):x = self.conv(inputs)x = F.sigmoid(x)x = self.pool(x)return x# Layer类继承方式组网class ThreeDNet(paddle.nn.Layer):def __init__(self):super(ThreeDNet, self).__init__()self.Block1024 = Block1024()self.Block512 = Block512()self.Block256 = Block256()self.Block128 = Block128()self.conv11 = paddle.nn.Conv1D(in_channels=3, out_channels=33, kernel_size=13)self.conv7a = paddle.nn.Conv1D(in_channels=33, out_channels=99, kernel_size=11)self.conv7b = paddle.nn.Conv1D(in_channels=33, out_channels=99, kernel_size=11)self.conv5a = paddle.nn.Conv1D(in_channels=99, out_channels=297, kernel_size=7)self.conv5b = paddle.nn.Conv1D(in_channels=99, out_channels=297, kernel_size=7)self.conv5c = paddle.nn.Conv1D(in_channels=99, out_channels=297, kernel_size=7)self.conv5d = paddle.nn.Conv1D(in_channels=99, out_channels=297, kernel_size=7)self.conv5e = paddle.nn.Conv1D(in_channels=99, out_channels=297, kernel_size=7)self.conv3a = paddle.nn.Conv1D(in_channels=297, out_channels=10, kernel_size=5)self.conv3b = paddle.nn.Conv1D(in_channels=297, out_channels=10, kernel_size=5)self.conv3c = paddle.nn.Conv1D(in_channels=297, out_channels=10, kernel_size=5)self.conv3d = paddle.nn.Conv1D(in_channels=297, out_channels=10, kernel_size=5)self.conv3e = paddle.nn.Conv1D(in_channels=297, out_channels=10, kernel_size=5)self.conv3f = paddle.nn.Conv1D(in_channels=297, out_channels=10, kernel_size=5)self.conv3g = paddle.nn.Conv1D(in_channels=297, out_channels=10, kernel_size=5)self.conv3h = paddle.nn.Conv1D(in_channels=297, out_channels=10, kernel_size=5)self.BlockOut = BlockOut()def forward(self, inputs):x11 = self.conv11(inputs)a = self.Block1024(x11)x7 = self.conv7a(x11)b1 = self.Block512(x7)b2 = self.Block512(self.conv7b(a))xb = paddle.concat(x=[b1, b2], axis=-1)x5 = self.conv5a(x7)xb5 = self.conv5b(xb)c1 = self.Block256(self.conv5c(b1))c2 = self.Block256(self.conv5d(b2))c3 = self.Block256(self.conv5e(xb))c4 = self.Block256(x5)c5 = self.Block256(xb5)xc = paddle.concat(x=[c1, c2, c3, c4, c5], axis=-1)x3 = self.conv3a(x5)xbc3 = self.conv3b(xb5)xc3 = self.conv3c(xc)d1 = self.Block128(self.conv3d(c1))d2 = self.Block128(self.conv3e(c2))d3 = self.Block128(self.conv3f(c3))d4 = self.Block128(self.conv3g(xc))d5 = self.Block128(self.conv3h(xb5))d6 = self.Block128(x3)d7 = self.Block128(xbc3)d8 = self.Block128(xc3)xd = paddle.concat(x=[d1, d2, d3, d4, d5, d6, d7, d8], axis=-1)output = self.BlockOut(xd)return outputthreeDNet = ThreeDNet()
2.查看网络结构
使用高层API查看网络结构,由于是全卷积神经网络,因此神经网络可以适配3D点云中点的个数,即坐标点的个数可以是任意的:
paddle.summary(threeDNet, (1, 3, 1024)) # (1, 3, N)N表示坐标点的个数,可以是的任意值(因为第一层卷积核为7,因此要大于或等于7,但实际中应该不存在只有7个点的点云)paddle.summary(threeDNet, (1, 3, 1024)) # (1, 3, N)N表示坐标点的个数,可以是的任意值(因为第一层卷积核为7,因此要大于或等于7,但实际中应该不存在只有7个点的点云)-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv1D-1 [[1, 3, 1024]] [1, 33, 1012] 1,320
AdaptiveAvgPool1D-1 [[1, 33, 1012]] [1, 33, 1024] 0
Block1024-1 [[1, 33, 1012]] [1, 33, 1024] 0
Conv1D-2 [[1, 33, 1012]] [1, 99, 1002] 36,036
AdaptiveAvgPool1D-2 [[1, 99, 1014]] [1, 99, 512] 0
Block512-1 [[1, 99, 1014]] [1, 99, 512] 0
Conv1D-3 [[1, 33, 1024]] [1, 99, 1014] 36,036
Conv1D-4 [[1, 99, 1002]] [1, 297, 996] 206,118
Conv1D-5 [[1, 99, 1024]] [1, 297, 1018] 206,118
Conv1D-6 [[1, 99, 512]] [1, 297, 506] 206,118
AdaptiveAvgPool1D-3 [[1, 297, 1018]] [1, 297, 256] 0
Block256-1 [[1, 297, 1018]] [1, 297, 256] 0
Conv1D-7 [[1, 99, 512]] [1, 297, 506] 206,118
Conv1D-8 [[1, 99, 1024]] [1, 297, 1018] 206,118
Conv1D-9 [[1, 297, 996]] [1, 10, 992] 14,860
Conv1D-10 [[1, 297, 1018]] [1, 10, 1014] 14,860
Conv1D-11 [[1, 297, 1280]] [1, 10, 1276] 14,860
Conv1D-12 [[1, 297, 256]] [1, 10, 252] 14,860
AdaptiveMaxPool1D-1 [[1, 10, 1276]] [1, 10, 10] 0
Block128-1 [[1, 10, 1276]] [1, 10, 10] 0
Conv1D-13 [[1, 297, 256]] [1, 10, 252] 14,860
Conv1D-14 [[1, 297, 256]] [1, 10, 252] 14,860
Conv1D-15 [[1, 297, 1280]] [1, 10, 1276] 14,860
Conv1D-16 [[1, 297, 1018]] [1, 10, 1014] 14,860
Conv1D-17 [[1, 10, 80]] [1, 1, 78] 31
AdaptiveAvgPool1D-4 [[1, 1, 78]] [1, 1, 10] 0
BlockOut-1 [[1, 10, 80]] [1, 1, 10] 0
===============================================================================
Total params: 1,222,893
Trainable params: 1,222,893
Non-trainable params: 0
-------------------------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 13.88
Params size (MB): 4.66
Estimated Total Size (MB): 18.55
-------------------------------------------------------------------------------
{'total_params': 1222893, 'trainable_params': 1222893}
3.模型训练
# 用 DataLoader 实现数据加载train_loader = paddle.io.DataLoader(train_dataset, batch_size=1, shuffle=True)# mnist=Mnist()threeDNet.train()# 设置迭代次数epochs = 100# 设置优化器lr = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=0.00025, T_max=int(train_dataset.__len__() * epochs / 128))optim = paddle.optimizer.Momentum(learning_rate=lr, parameters=threeDNet.parameters(), weight_decay=1e-5)# 设置损失函数loss_fn = paddle.nn.CrossEntropyLoss()# 评估指标BestAcc = 0for epoch in range(epochs):acc = 0loss = 0count = 0for batch_id, data in enumerate(train_loader()):x_data = data[0] # 训练数据y_data = data[1] # 训练数据标签predicts = threeDNet(x_data) # 预测结果# 计算损失 等价于 prepare 中loss的设置loss += loss_fn(predicts, y_data)# 计算准确率 等价于 prepare 中metrics的设置acc += paddle.metric.accuracy(predicts, y_data)if count >= 128:# 反向传播loss.backward()# 更新参数optim.step()# 梯度清零optim.clear_grad()count = 0count += 1loss.backward()optim.step()optim.clear_grad(): {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id+1, loss.numpy()/train_dataset.__len__(), acc.numpy()/train_dataset.__len__()))if acc.numpy()/train_dataset.__len__() > BestAcc:state_dict = threeDNet.state_dict()# save state_dict of threeDNet"threeDNet/threeDNet.pdparams")BestAcc = acc.numpy()/train_dataset.__len__()
部分训练日志截取:
epoch: 0, batch_id: 3991, loss is: [2.2351303], acc is: [0.19418693]epoch: 1, batch_id: 3991, loss is: [2.1812398], acc is: [0.22275119]epoch: 2, batch_id: 3991, loss is: [2.1573942], acc is: [0.22625908]epoch: 3, batch_id: 3991, loss is: [2.138466], acc is: [0.24805813]epoch: 4, batch_id: 3991, loss is: [2.1174479], acc is: [0.2731145]epoch: 5, batch_id: 3991, loss is: [2.1015415], acc is: [0.29766977]epoch: 6, batch_id: 3991, loss is: [2.0876462], acc is: [0.331997]epoch: 7, batch_id: 3991, loss is: [2.0767505], acc is: [0.3755951]epoch: 8, batch_id: 3991, loss is: [2.0677485], acc is: [0.41618642]epoch: 9, batch_id: 3991, loss is: [2.0585632], acc is: [0.43172136]epoch: 10, batch_id: 3991, loss is: [2.0521076], acc is: [0.4550238]... ...epoch: 95, batch_id: 3991, loss is: [1.8270358], acc is: [0.72788775]epoch: 96, batch_id: 3991, loss is: [1.8227352], acc is: [0.72563267]epoch: 97, batch_id: 3991, loss is: [1.8221083], acc is: [0.73189676]epoch: 98, batch_id: 3991, loss is: [1.8253901], acc is: [0.71961915]epoch: 99, batch_id: 3991, loss is: [1.8208766], acc is: [0.72588325]
四、测试效果评估
# 加载模型权重threeDNet_PATH = "threeDNet/threeDNet.pdparams"threeDNet_state_dict = paddle.load(threeDNet_PATH)threeDNet.set_dict(threeDNet_state_dict)threeDNet.eval()# 加载测试集test_loader = paddle.io.DataLoader(test_dataset, batch_size=1)
批量测试
loss_fn = paddle.nn.CrossEntropyLoss()loss = 0acc = 0count = 0for batch_id, data in enumerate(test_loader()):if count > 500: # 只取前500条数据,数据过多会内存溢出breakx_data = data[0] # 测试数据y_data = data[1] # 测试数据标签predicts = threeDNet(x_data)# 预测结果# 计算损失与精度loss += loss_fn(predicts, y_data)acc += paddle.metric.accuracy(predicts, y_data)count += 1# 打印信息print("loss is: {}, acc is: {}".format(loss.numpy()/count, acc.numpy()/count))
loss is: [2.1944385], acc is: [0.1996008]
2.逐个测试
取某一条数据进行可视化,更直观地检测模型效果:
import numpy as npfrom mpl_toolkits import mplot3d%matplotlib inlineimport matplotlib.pyplot as pltimport numpy as npindex = 0for batch_id, data in enumerate(test_loader()):if batch_id != index:continuex_data = data[0] # 测试数据y_data = data[1] # 测试数据标签predicts = threeDNet(x_data)# 预测结果# 可视化xdata = np.array(data[0][0][0])ydata = np.array(data[0][0][1])zdata = np.array(data[0][0][2])# 3D点云可视化ax = plt.axes(projection='3d')ax.scatter3D(xdata, ydata, zdata, c='r')plt.show()print("该3D点云物体的期望结果是{},实际结果是{}".format([k for k,v in category.items() if v == int(y_data)], [k for k,v in category.items() if v == np.argsort(predicts[0][0][-1][0])]))
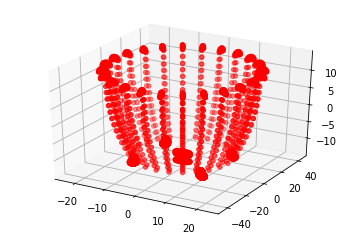
<Figure size 432x288 with 1 Axes>
该3D点云物体的期望结果是['bathtub'],实际结果是['bathtub']
五、总结与升华
本项目是对3D点云物体识别的尝试,在数据处理和模型组网的时候,我花了较多的时间。
特别是模型组网,我设计了一个全卷积神经网络来识别3D点云物体,刚开始设计的网络比较小,识别的效果并不理想,后来,我把卷积核增大,并加深网络以及加上跳连,使模型有一个较好的拟合效果。
本文仅做学术分享,如有侵权,请联系删文。