
全卷积神经网络(FCN)
回顾
上期我们一起学习了,关于传统的目标检测算法的大致思路,通常是利用滑动窗口进行选取目标候选框,然后利用一些算法进行特征提取,最后再扔到分类器中去检测分类,这样效率上来说是比较低的。
前奏 | 传统目标检测算法思路
那么今天我们一起学习一下一个解决提高检测效率的一个方法,全卷积神经网络(FCN),我们知道,对于一个各层参数结构都设计好的神经网络来说,输入的图片大小是要求固定的,比如AlexNet,VGGNet, GoogleNet等网络,都要求输入固定大小的图片才能正常工作。
而FCN的精髓就是让一个已经设计好的网络可以输入任意大小的图片。接下来,我们就一起看一下FCN和CNN有什么区别?
1. CNN和FCN网络结构对比
CNN网络
假如我们要设计一个用来区分猫,狗和背景的网络,正常的CNN的网络的架构应该是如下图: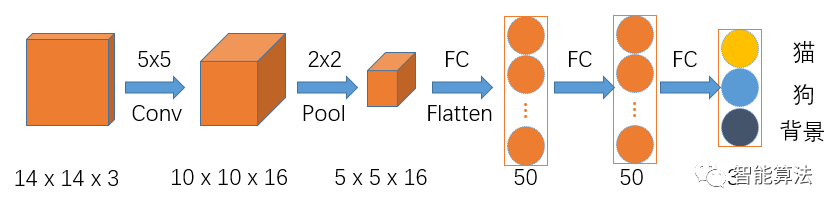
假如输入图片size为14x14x3的彩色图,如上图,首先经过一个5x5的卷积层,卷积层的输出通道数为16,得到一个10x10x16的一组特征图,然后经过2x2的池化层,得到5x5x16的特征图,接着Flatten后进入两个50个神经元的全连接层,最后输出分类结果。
这里由于全连接层中输入层神经元的个数是固定,这就导致反推出卷积层的输入要求是固定的,这就不利于不同尺寸的图片进行训练,想要深入了解上面过程,可参考之前文章:
FCN网络
全卷积神经网络,顾名思义是该网络中全是卷积层链接,如下图: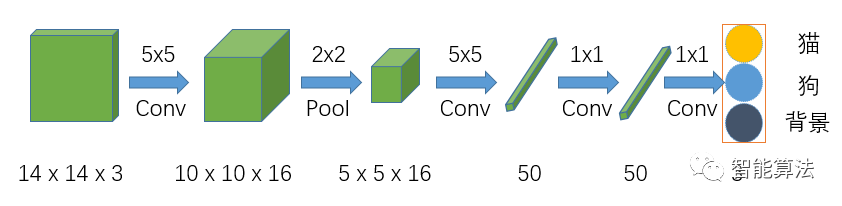
该网络在前面两步跟CNN的结构是一样的,但是在CNN网络Flatten的时候,FCN网络将之换成了一个卷积核size为5x5,输出通道为50的卷积层,之后的全连接层都换成了1x1的卷积层。
我们知道1x1的卷积其实就相当于全连接操作,具体可以参考之前文章:
CNN中神奇的1x1卷积
从上两个图比较可知全卷积网络和CNN网络的主要区别在于FCN将CNN中的全连接层换成了卷积操作。
换成全卷积操作后,由于没有了全连接层的输入层神经元个数的限制,所以卷积层的输入可以接受不同尺寸的图像,也就不用要求训练图像和测试图像size一致。
那么问题也来了,如果输入尺寸不一样,那么输出的尺寸也肯定是不同的,那么该如何去理解FCN的输出呢?
2. FCN如何理解网络的输出?
特征图尺寸变化
我们首先不考虑通道数,来看一下上面网络中的特征图尺寸的具体变化,如下图,图中绿色为卷积核,蓝色为特征图: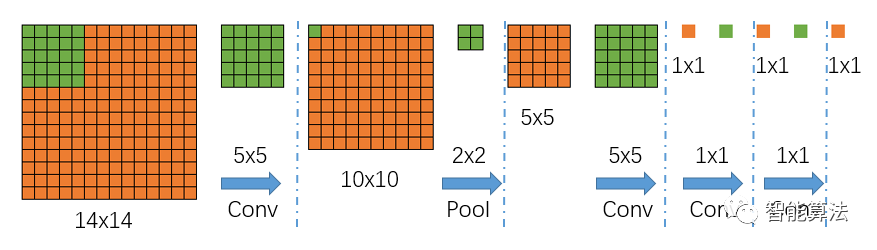
从上图中,我们可以看到,输入是一个14x14大小的图片,经过一个5x5的卷积(不填充)后,得到一个10x10的特征图,然后再经过一个2x2的池化后,尺寸缩小到一半变成5x5的特征图,再经过一个5x5的卷积后,特征图变为1x1,接着后面再进行两次1x1的卷积(类似全连接操作),最终得到一个1x1的输出结果,那么该1x1的输出结果,就代表最前面14x14图像区域的分类情况,如果对应到上面的猫狗和背景的分类任务,那么最后输出的结果应该是一个1x3的矩阵,其中每个值代表14x14的输入图片中对应类别的分类得分。
不同尺寸的输入图片
好了,不是说可以接收任意尺寸的输入吗?我们接下来看一个大一点的图片输入进来,会得到什么样的结果,如下图: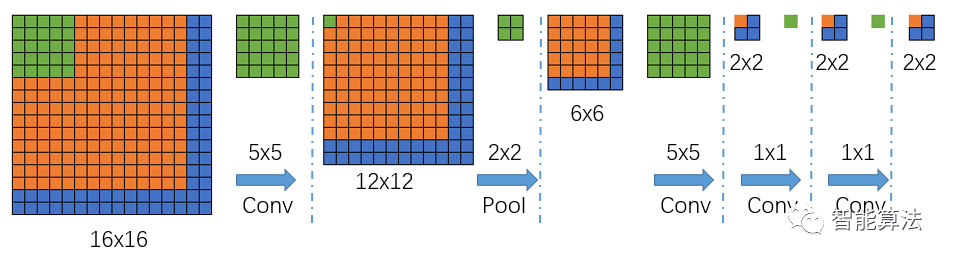
我们可以看到上面的图,输入尺寸由原来的14x14变成了16x16,那么经过一个5x5的卷积(不填充)后,得到一个12x12的特征图,然后再经过一个2x2的池化后,尺寸缩小到一半变成6x6的特征图,再经过一个5x5的卷积后,特征图变为2x2,接着后面再进行两次1x1的卷积(类似全连接操作),最终得到一个2x2的输出结果,那么该2x2的输出结果,就代表最前面16x16图像区域的分1类情况,然而,输出是2x2,怎么跟前面对应呢?
哪一个像素对应哪个区域呢?
我们看下图:

根据卷积池化反推,前面图3,我们知道,最后的输出1x1代表了前面14x14的输入的分类结果,那么我们根据卷积核的作用范围可以推出,上图中最后输出2x2中左上角的橙色输出就代表了16x16中的橙色区域(红色框),依次类推,输出2x2中右上角的蓝色输出就代表了16x16中的黄色框区域,输出2x2中左下角的蓝色输出就代表了16x16中的黑色框区域,输出2x2中右下角的蓝色输出就代表了16x16中的紫色框区域,其中每个框的大小都是14x14.也就是说输出的每个值代表了输入图像中的一个区域的分类情况。
3. FCN如何对目标检测进行加速?
根据上面的图5,我们知道FCN最后的输出,每个值都对应到输入图像的一个检测区域,也就是说FCN的输出直接反应了对应输入图像检测区域的分类情况,由于图4和图5均没考虑通道情况,那么我们将网络放到一个正常的28x28x3的图像上,考虑上特征图的通道数,看下输出值的对应情况,如下图: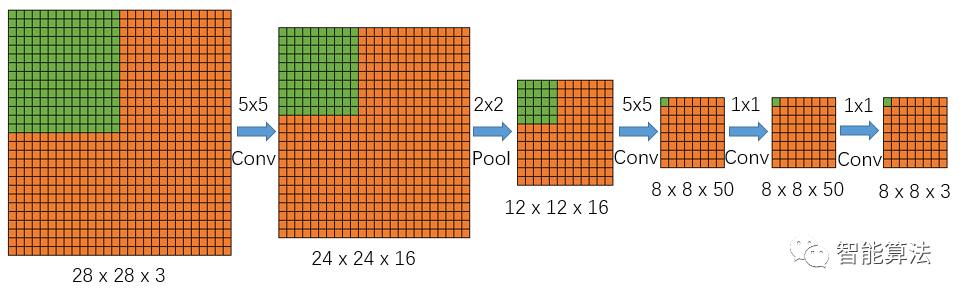
图6 FCN如何加速
上图中绿色区域表现了依次通过网络后的特征图尺寸变化情况。
跟图5类似,因为这是一个猫狗和背景的三分类任务,所以最后输出的图像大小为8x8x3,以输出图像左上角绿色点为例,该点深度为3,对应输入图像的绿色区域,该点的3个值反应了输入图的绿色区域是分类为猫狗还是背景的得分情况。
总的来说,FCN利用了输出结果和输入图像的对应关系,直接给出了输入图像相应区域的分类情况,取消了传统目标检测中的滑动窗口选取候选框。
FNC优缺点
输出结果的每个值映射到输入图像上的感受野的窗口是固定的,也就是检测窗口是固定的,导致检测效果没那么好,但是速度却得到了很大的提升,而且可以输入任意尺寸的图片,为目标检测提供了一种新思路。
好了,这期我们学到这里,下期我们继续深入,学习下目标检测的评价指标都有哪些。