
使用3D卷积神经网络进行次优视图回归
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


自动三维(3D)对象重建是通过感知其表面来构建一个物理对象的几何表示的任务。虽然新的单视图重建技术可以预测表面,但它们导致不完整的模型,特别是对于非公共对象,如古董对象或艺术雕塑。因此,为了实现任务的目标,必须自动确定传感器将放置的位置,使表面将被完全观察到。这个问题被称为次最佳视角问题。在本文中,作者提出了一种数据驱动的方法来解决这个问题。所提出的方法用先前的重建来训练一个3D卷积神经网络(3D CNN),以便回归次最佳视图的位置。据作者所知,这是使用数据驱动的方法在三维物体重建任务中直接推断连续空间中次佳视图的第一批作品之一。通过两组实验,作者验证了所提出的方法。在第一组中,分析了提议的体系结构的几个变体。预测的下一个最佳视图被观察到是接近地面真相的位置。在第二组实验中,作者要求所提出的方法重建几个看不见的物体,即在训练和验证过程中3D CNN没有考虑到的物体。观察到的覆盖率高达90%。与当前最先进的方法相比,本文提出的方法提高了以前的次优视图分类方法的性能,并且在运行时间上非常快(3帧每秒),因为它不需要计算以前信息度量所需的昂贵射线追踪。
本文的研究进展如下:
1.而本文解决了一个回归问题。主要的含义是,在这项工作中,一个人不限于离散的预定义的传感位置;相反,NBV是由连续体决定的。
2. 本文就网络结构中的层数问题进行了分析。这样的分析在[25]中并不存在。
3.这项工作也提出了关于dropout存在的分析。
4. 对预测的nvs进行了定性和定量分析,并将其与实际情况进行了比较。
5. 作者测试了13个新对象,这些对象既不包括在[24]训练数据集中,也不包括在[25]中。
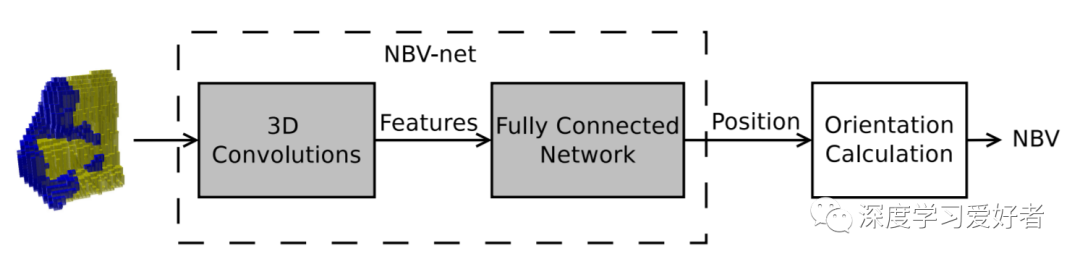
次优视图规划的整体回归方法
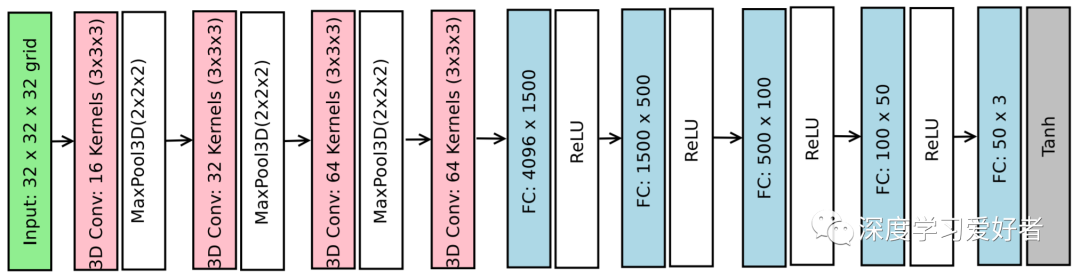
NBV-net 4 - 5架构
数字4-5代表4个特征提取层和5个完全连通的层。
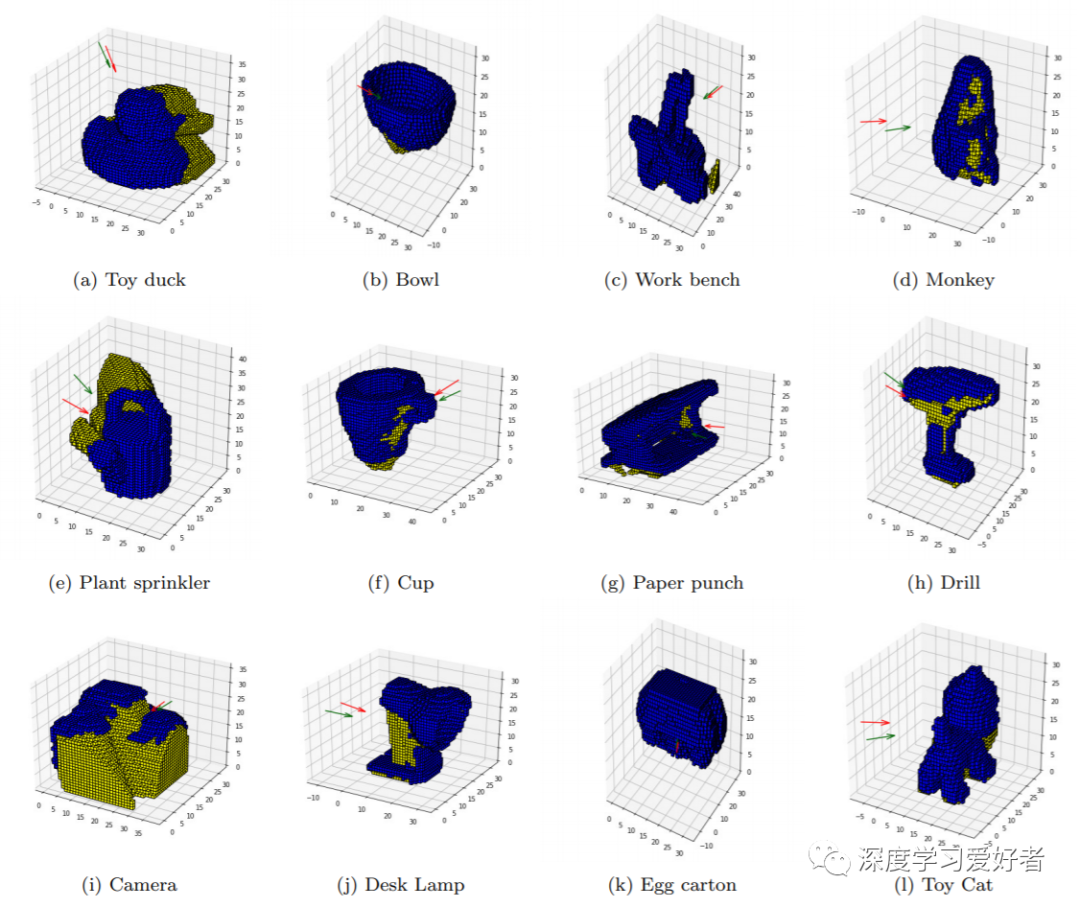
数据集中几个对象的预测下一个最佳视图与地面真相的比较。蓝色体素表示测量表面。黄色体素表示未知空间。预测的次最佳视图用红色表示。仅次于最佳视图的地面真相用绿色表示。

模型
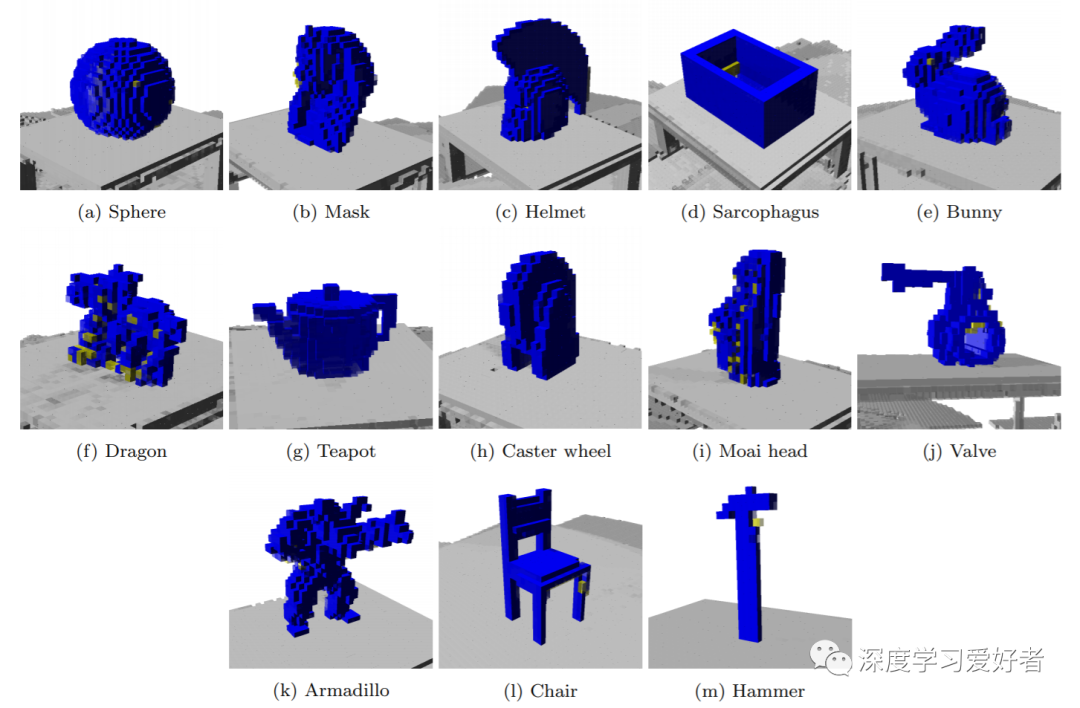
测试结果
作者提出了一种基于深度学习的次优视图回归方法。在这种方法中,作者解决了连续空间中次优视图预测。所提议的网络架构是为特定的问题而设计的,它已经经过训练和验证。作者的实验表明,提出的方法可以很好地概括出在训练和验证过程中没有被网络看到的物体形状。该方法的快速响应是其优点之一,因为它消除了昂贵的射线追踪所需的国家最先进的方法。作者将本文提出的方法与其他两种相关方法进行了比较。作者可以得出结论,本文提出的方法在物体重建的百分比和计算次优视图所需的处理时间之间取得了良好的平衡。对于未来的研究,作者将研究新的损失函数以及在大型建筑重建中的应用。最后,计划继续扩展包括其他对象在内的训练和验证数据集。
论文链接:https://arxiv.org/pdf/2101.09397.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~