
谷歌MaskGIT|双向Transformer,图像生成新范式!
图像生成长期以来一直被GAN所统治,虽然GAN的生成结果非常逼真,但在多样性方面却不如基于最大似然的方法(VAE、自回归模型等)。在去年,我们也看到了DALL-E、VQGAN等生成模型,模仿NLP的成功,利用Transformer来做图像生成,但这类方法有个很大的缺点,就是生成速度太慢了。

Transformer-based的图像生成基本完全参考NLP处理序列数据的做法,需要两个步骤:
Tokenization:自然语言都是离散值,而图像是连续值,想像NLP一样处理必须先离散化,iGPT里直接把图像变成一个个马赛克色块,ViT则是切成多块后分别进行线性映射,还有的方法专门学了一个自编码器,用encoder把图像映射成token,再用decoder还原 Autoregressive Prediction:用单向Transformer一个个token地预测,最终生成图像
虽然这类方法的生成结果还可以,但是从直觉上却不那么顺溜。仔细想人是怎么画画的,大多数人肯定是先画个草稿,然后再逐步细化、填色,由整体到局部,而不是从上到下从左到右一个个像素去填充。
MaskGIT的核心思想,就是参考人的作画逻辑,先生成一部分token,再逐渐去完善。

MaskGIT: Masked Generative Image Transformer
https://arxiv.org/abs/2202.04200
MaskGIT
MaskGIT的模型结构如下:
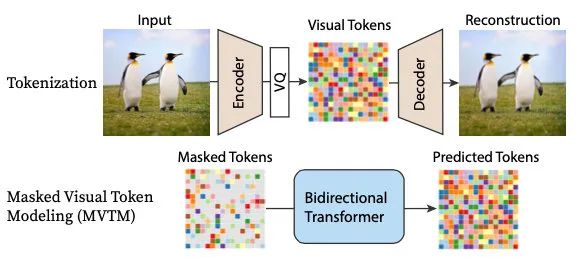
对于Tokenization步骤,直接参考VQGAN的思路,学习一个encoder-decoder。
主要的改进点在第二步上,在生成阶段,重复以下步骤:
并行预测所有被mask的部分,这时会给出一个概率最高的token和概率值 计算本轮要保留的token数目 根据数目倒推概率值,不满足条件的继续mask掉,回到步骤1重新生成
在训练阶段,不像BERT只mask掉15%,MaskGIT会随机选取各种值,来模拟生成阶段的情况。
生成阶段的核心,就在于如何计算这一轮要mask多少token,这个schedule函数有两个特性:
定义域在0到1之间、值域在0到1之间的连续函数
在对Linear、Concave、Convex三类函数实验后,发现Cosine是表现最好的:

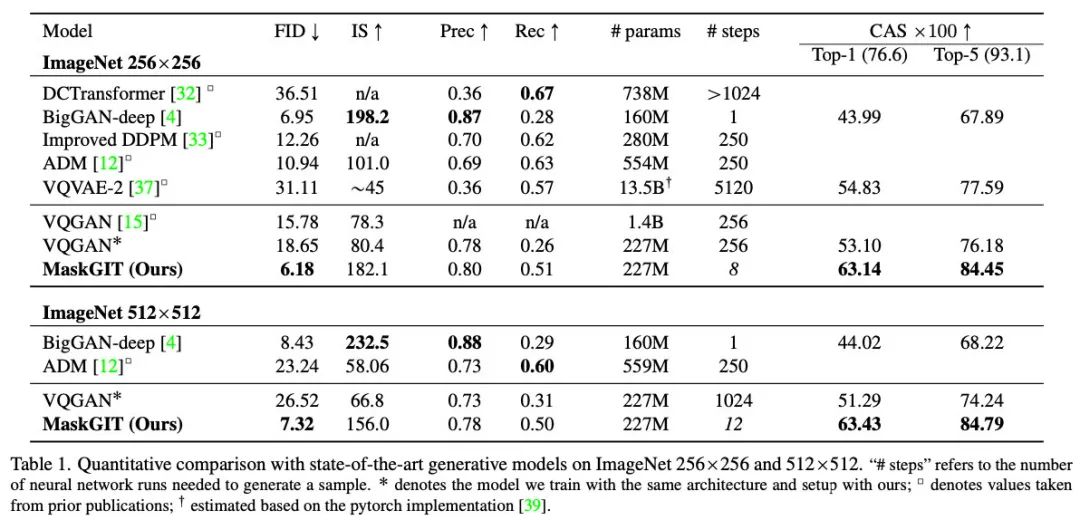
从最终的效果可以看到,MaskGIT在图像质量上(FID、IS分数)接近当前最好的BigGAN,在速度上远胜VAGAN,在多样性(CAS分数)上超越了BigGAN:
同时作者发现,MaskGIT在编辑图像上有很大的潜力,尤其是class-conditioned image editing任务,自回归模型基本做不了,GAN来做也很难,对MaskGIT却十分容易,推动了一波鬼畜P图的发展(下面的例子让我深度怀疑作者是猫控):

总结
MaskGIT作者在文中说到,双向Transformer的启发源自于机器翻译的一些工作,不过这却是图像领域的第一篇工作。MaskGIT的出发点相比单向自回归,在图像生成上更加make sense,相信之后也看到一些相关改进。
其中我想到一点,也是从直觉上出发的,我们人在画画时,免不了对草图的涂改,而MaskGIT是没有涂改机会的,有没有更好的soft mask方式,或者迭代策略,可以对已经生成完的token进行迭代,这样说不定就能超过GAN的生成质量了。
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
