
更高清!谷歌推出生成文本到图像的新框架 TReCS,效果超过AttGAN

新智元报道
【新智元导读】谷歌研究人员推出新框架 TRECS,生成的图像更逼真,更符合文字的描述。
近年来,基于生成对抗性网络(GAN)的深层神经网络已经大幅提高了端到端可训练的照片式文本到图像的生成结果。许多方法也使用中间场景图(intermediate scene graph)表示来改进图像合成的效果。
通过基于对话交互的方法允许用户提供指令来逐步改进和调整生成的场景:通过指定背景中对象的相对位置,为用户提供了更大的控制权。然而,这种方法所使用的语言是有限制的,所产生的图像仅限于3D合成可视化或者卡通。
本月初,OpenAI官宣了一个基于Transformer的语言模型DALL-E,使用了GPT-3的120亿参数版本,引起了不小的轰动。
根据文字提示,DALL-E生成的图像可以像在现实世界中拍摄的一样。

DALL-E同时接收文本和图像作为单一数据流,包含多达1280个token,并使用最大似然估计来进行训练,以一个接一个地生成所有的token。这个训练过程不仅允许DALL-E可以从头开始生成图像,而且还可以重新生成现有图像的任何矩形区域,与文本提示内容基本一致。
谷歌当然不甘落后。
最近,谷歌研究院的成员们发表了一篇新论文:以细粒度用户注意力为基础的文本到图像生成.

作者在论文中提出了一个新的框架:Tag-Retrieve-Compose Synthesize system (TReCS)。该方法通过改进语言对图像元素的唤醒方式和痕迹对图像元素位置的告知方式,显著提高了图像生成过程。该系统使用了超过250亿个样本来进行训练,并有可能处理103种语言。
这篇论文的主要贡献在于:
1.第一次展示了在非常困难的文本到图像合成任务中的能力(与之前关于更短的文本任务相比)。
2.提出了TRECS,这是一种序列生成模型,它使用最先进的语言和视觉技术生成与语言和空间鼠标轨迹一致的高质量图像。
3.进行了自动和人工评估,以证明TRECS生成的图像质量比现有技术有所提高。通过广泛的研究,确定了TRECS管道的关键组成部分,这对于基于用户注意力的文本到图像生成任务至关重要。
具体效果如下:

或是这样:

TRECS的亮点在于可以同时利用文本和鼠标痕迹。相比对于其他策略,尤其是那些需要场景图的策略,说话时用鼠标指着是一种更自然的方式,供用户在图像合成过程中指示其意图。
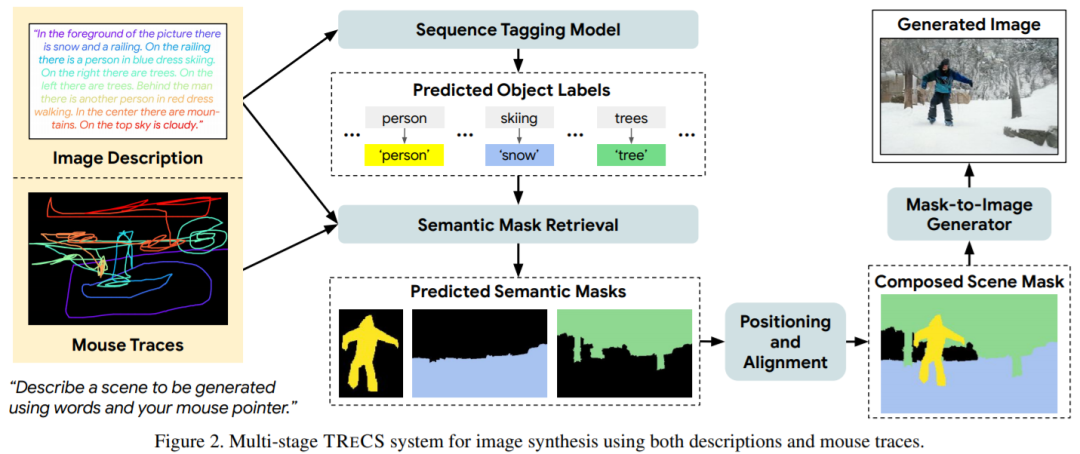
大致流程如下:
1.新的框架利用可控的鼠标轨迹作为细粒度的视觉基础来生成给定用户叙述的高质量图像,标记器用于预测短语中每个单词的对象标记。
2. 文本到图像的双重编码器用语义相关的mask掩码来检索图像。对于每个跟踪序列,选择一个mask来最大化空间重叠,克服了真实文本到对象的信息和更好的描述。
3. 选定的mask按照跟踪顺序组合,并为背景和前景对象分别绘制画布。前景掩码被置于背景掩码之上,以创建一个完整的场景分割。
4. 最后,将整个分割过程输入到掩码到图像的转换模型中,合成出真实感图像。
在评价方面,无论是自动判断还是人工评估,该系统都优于目前 SOTA 的文本图像生成技术。从日常语言中翻译出来的杂乱的叙事文本中生成真实可控的照片,显示了这种方法的可行性。同时TReCS 系统也解释了冗长而复杂的文本描述来进行文本-图像生成的复杂性。实验结果表明,该方法可以有效地生成真实感强的文本图像。
目前该方法还存在一定的限制,即:缺乏合适的评价指标来定量测量生成的图像的质量。现有的度量方法不能合理地反映基本真实图像和机器生成的真实图像之间的语义相似性。
不过,在未来的几年里,这个想法或许可以用来支持各种应用程序,并提供一个友好的人机界面。例如,可以帮助艺术家创建原型,从机器生成的照片中获得洞察力,并生成逼真的图像。此外,它可以用来设计 human-in-the-loop 的评价系统,以优化网络。
论文原文链接:
https://arxiv.org/pdf/2011.03775.pdf
