
自回归解码加速64倍,谷歌提出图像合成新模型MaskGIT

来源:机器之心 本文约2200字,建议阅读5分钟
一种使用双向 transformer 解码器的新型图像合成模型 MaskGIT,在性能和速度上都获得了大幅改进。
来自谷歌研究院的研究者提出了一种使用双向 transformer 解码器的新型图像合成模型 MaskGIT,在性能和速度上都获得了大幅改进。
生成式 transformer 在合成高保真和高分辨率图像方面得到了快速普及。但迄今为止最好的生成式 transformer 模型仍是将图像视为一系列 token,并按照光栅扫描顺序(即逐行)解码图像。然而这种策略既不是最优的,也不高效。
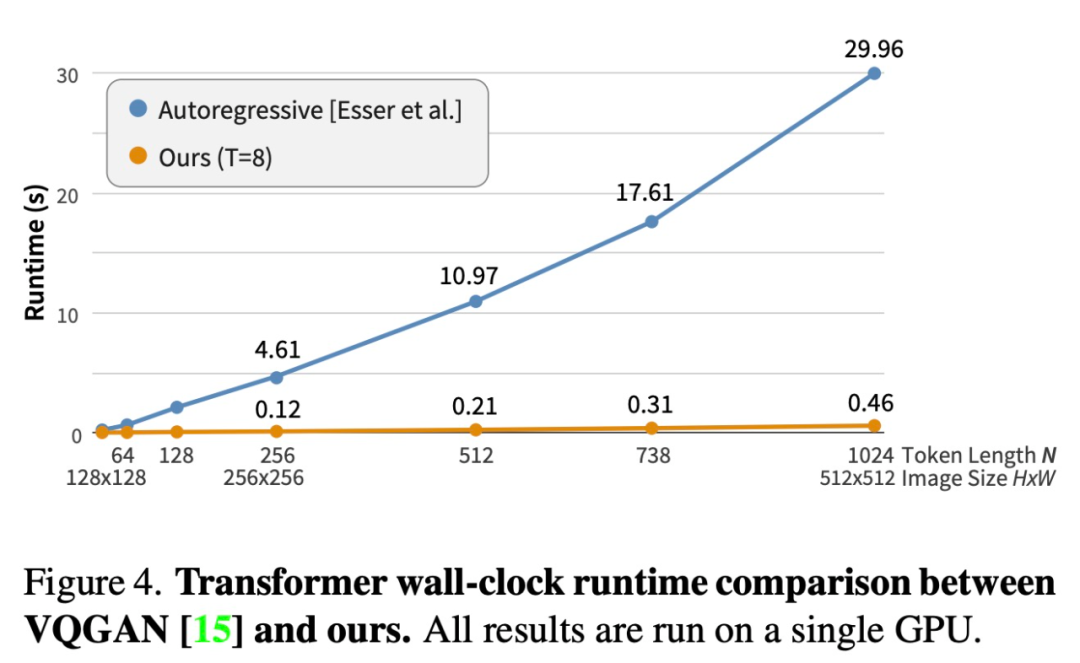
近日,来自谷歌研究院的研究者提出了一种使用双向 transformer 解码器的新型图像合成模型 MaskGIT。在训练期间,MaskGIT 通过关注各个方向的 token 来学习预测随机掩码 token。在推理阶段,模型首先同时生成图像的所有 token,然后以上一次生成为条件迭代地细化图像。实验表明,MaskGIT 在 ImageNet 数据集上显著优于 SOTA transformer 模型,并将自回归解码的速度提高了 64 倍。

论文地址:https://arxiv.org/abs/2202.04200
 tokenize 成潜在嵌入 E(x);
tokenize 成潜在嵌入 E(x);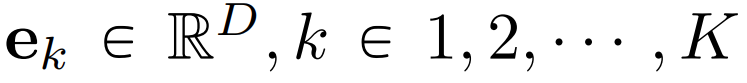 ,以将嵌入量化为视觉 token;
,以将嵌入量化为视觉 token;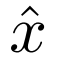 。
。 表示将图像输入到 VQ 编码器获得的潜在 token,其中 N 是重构后的 token 矩阵的长度,
表示将图像输入到 VQ 编码器获得的潜在 token,其中 N 是重构后的 token 矩阵的长度,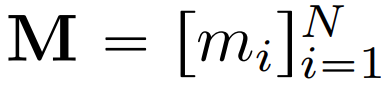 是对应的二进制掩码。在训练期间,该研究采样 token 的子集,并用一个特殊的 [MASK] token 替代它们。如果 m_i=1,就用 [MASK] 取代 token y_i;如果 m_i=0,y_i 保留。
是对应的二进制掩码。在训练期间,该研究采样 token 的子集,并用一个特殊的 [MASK] token 替代它们。如果 m_i=1,就用 [MASK] 取代 token y_i;如果 m_i=0,y_i 保留。 进行参数化,然后按照如下步骤:
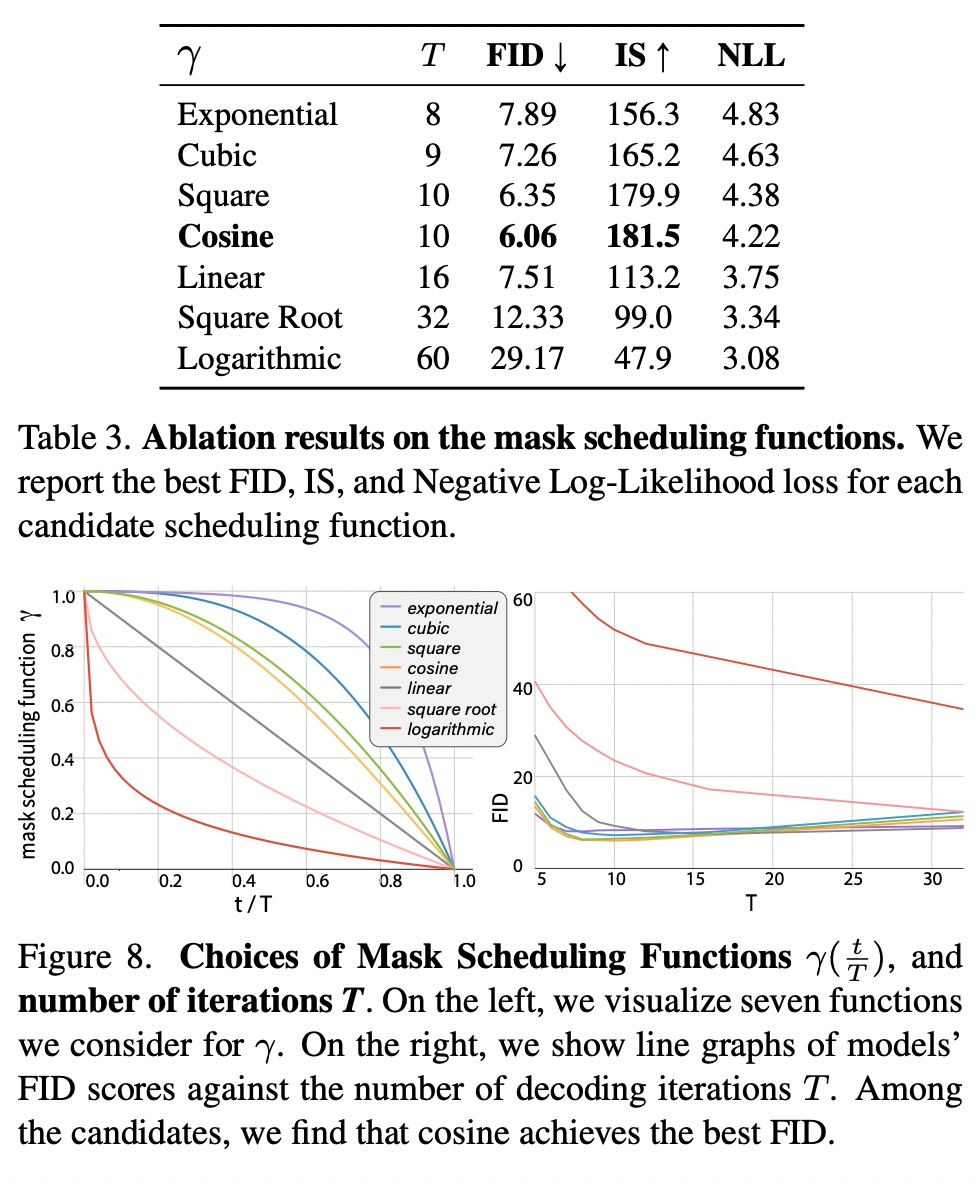
进行参数化,然后按照如下步骤: 个 token 来放置掩码,其中 N 是长度。掩码调度显著影响了图像的生成质量。
个 token 来放置掩码,其中 N 是长度。掩码调度显著影响了图像的生成质量。 。该研究提出的迭代解码方法,每次迭代的算法运行步骤如下:
。该研究提出的迭代解码方法,每次迭代的算法运行步骤如下: 对掩码过程进行建模,该函数负责计算给定潜在 token 的掩码比率。在推理期间,函数
对掩码过程进行建模,该函数负责计算给定潜在 token 的掩码比率。在推理期间,函数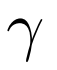 用
用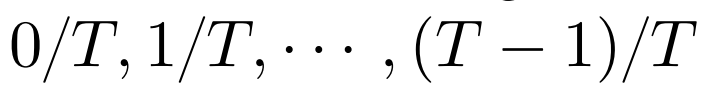 的输入代表解码的进度;在训练期间,该研究在 [0,1) 中随机采样一个比率 r 来模拟各种解码场景。
的输入代表解码的进度;在训练期间,该研究在 [0,1) 中随机采样一个比率 r 来模拟各种解码场景。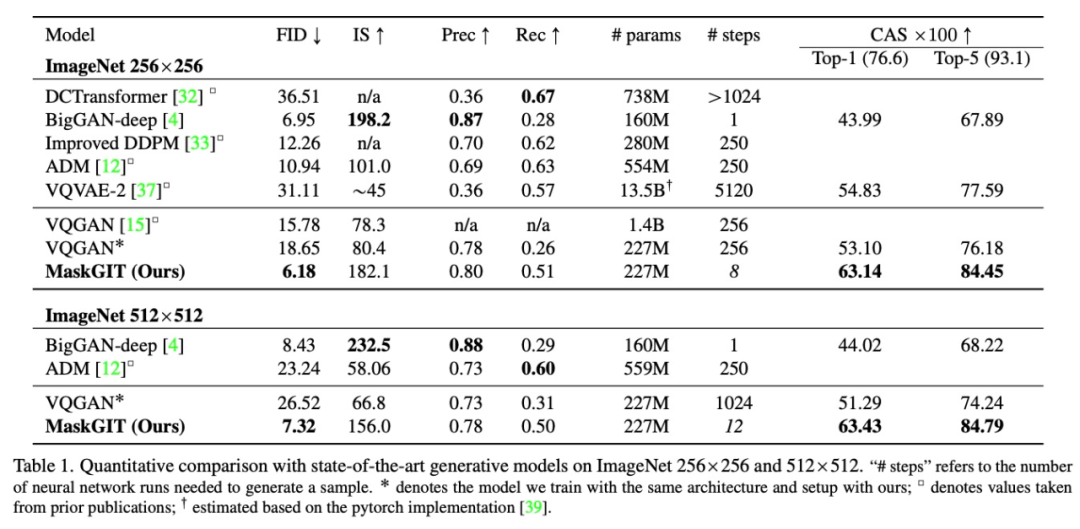




评论