
Dropout算子的bitmask优化
背景
在某个风和日丽,适合写bug的早晨,老大甩给我一个链接,里面是onnxruntime对dropout算子使用bitmask的优化,思路还是很巧妙的,下面简单解析下
代码地址:[CUDA] Implement BitmaskDropout, BitmaskBiasDropout and BitmaskDropoutGrad
Naive Dropout Kernel
Dropout的操作就是生成一个(0, 1)之间的随机数,当大于dropout_rate的时候,则设置mask=1,否则则设置为mask=0,这个mask值我们也需要保存下来用于后向,一段简化版本的朴素代码:
template<typename T>
__global__ naive_dropout(const T* x, T* y, int8_t* mask, float rate, const int64_t elem_cnt){
// curand_init...
CUDA_1D_KERNEL_LOOP(i, elem_cnt){
float random_val = curand_uniform(&state);
bool mask_val = random_val > rate;
y[i] = x[i] * static_cast(mask_val);
mask[i] = mask_val;
}
}
其中随机数生成用的是NV的cuRand随机数生成库,而阅读官网文档后,在Philox算法下,可以一次性生成4个随机数,从算子的逻辑来看,这是一个memory-bound的算子,这样我们就可以应用向量化手段来提高读写带宽,大部分框架内部都做了向量化的优化,这里我们用curand_uniform4来一次性生成4个随机数:
rand_uniform_pack4.storage = curand_uniform4(&state);
const LoadType* x_load = reinterpret_cast<const LoadType*>(x + linear_index);
LoadPack x_vec;
x_vec.storage = *x_load;
MaskPack mask_vec;
LoadPack y_vec;
#pragma unroll
for (int i = 0; i < pack_size; i++) {
mask_vec.elem[i] = rand_uniform_pack4.elem[i] > rate;
T tmp_float_mask = static_cast<float>(mask_vec.elem[i]);
y_vec.elem[i] = x_vec.elem[i] * tmp_float_mask * t_scale;
}
Bitmask
在正式介绍OnnxRuntime优化的算子前,我们先简单引入bitmask的概念。顾名思义,bitmask就是用比特位来表示mask,每一个bit可以取值为0和1,那么在dropout里,我们就可以用一个bit的状态来表示该元素是否被dropout掉。
相比我们用int8_t类型来保存mask,这无疑能节省很多显存。(原来一个int8只能保存1个mask,但如果用bitmask那么一个int8就可以保存8个mask)
使用Bitmask优化的Dropout
这里我们选取该PR的dropout_impl.cu文件作为示例:
template <typename T, bool UseBitmask>
__global__ void DropoutKernel(const CUDA_LONG N, const CUDA_LONG mask_element_count, const int step_size,
const int steps_per_thread, const fast_divmod fdm_bits_per_element, const float ratio,
const std::pair<uint64_t, uint64_t> seeds, const T* X_data, T* Y_data, void* mask_data) {
CUDA_LONG idx = blockDim.x * blockIdx.x + threadIdx.x;
const float p = 1.0f - ratio;
const float scale = 1.0f / p;
curandStatePhilox4_32_10_t state;
curand_init(seeds.first, idx, seeds.second, &state);
// The Philox_4x32_10 algorithm is closely tied to the thread and block count.
// Each thread computes 4 random numbers in the same time thus the most efficient
// use of Philox_4x32_10 is to generate a multiple of 4 times number of threads.
for (int i = 0; i < steps_per_thread; ++i) {
CUDA_LONG id = idx * kNumUnroll + i * step_size;
rand = curand_uniform4(&state);
BitmaskElementType thread_bitmask = 0;
// actual computation
#pragma unroll
for (int i = 0; i < kNumUnroll; ++i) {
CUDA_LONG li = id + i;
if (li < N) {
bool mask = (&rand.x)[i] < p;
Y_data[li] = static_cast(static_cast<float>(X_data[li]) * mask * scale);
if (UseBitmask) {
thread_bitmask |= (mask << i);
} else {
reinterpret_cast<bool*>(mask_data)[li] = mask;
}
}
}
if (UseBitmask) {
SetBitmask(id, mask_element_count, fdm_bits_per_element, thread_bitmask,
reinterpret_cast(mask_data));
}
__syncthreads();
}
}
这个kernel其实也是做了向量化的优化,其中kNumUnroll=4,我们着重看向量化循环展开的这部分逻辑:
uint32_t thread_bitmask;
for (int i = 0; i < kNumUnroll; ++i) {
CUDA_LONG li = id + i;
if (li < N) {
bool mask = (&rand.x)[i] < p;
Y_data[li] = static_cast(static_cast<float>(X_data[li]) * mask * scale);
if (UseBitmask) {
thread_bitmask |= (mask << i);
} ...
}
}
当使用bitmask的时候,将mask值进行左移,并通过逻辑或的操作,赋进thread_bitmask里的其中一个bit,这样循环结束后,每个线程的thread_bitmask就存储了其处理的4个元素的mask值。
假设我们的处理的4个元素的mask值分别是1 0 1 1,那么示意图如下:
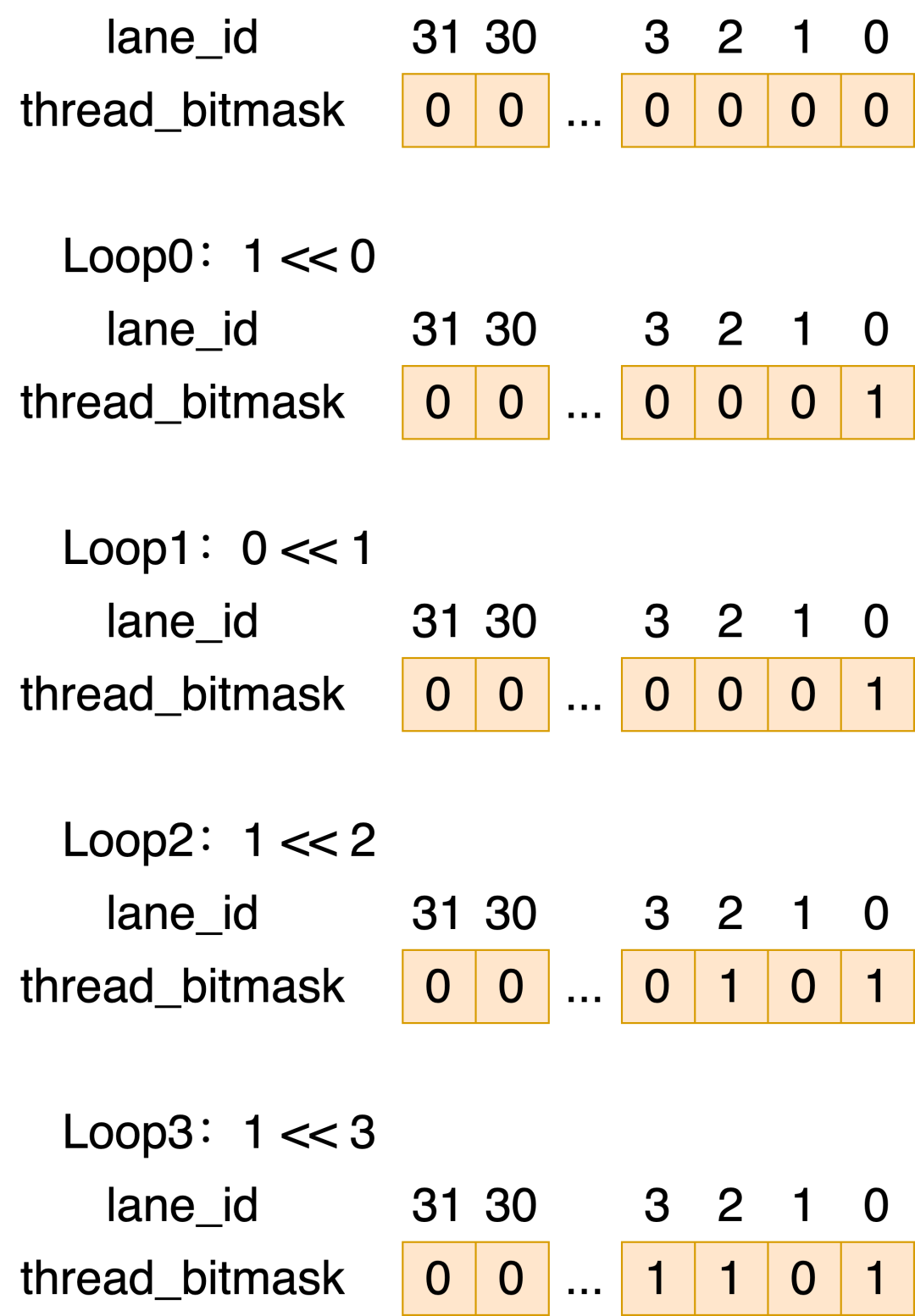
每个线程计算好mask后,下一步就是怎么把各个mask存储进变量中,对应的是bitmask.cuh中的SetBitmask函数
template <int NumUnroll>
__device__ __forceinline__ void SetBitmask(const CUDA_LONG id, const CUDA_LONG mask_element_count,
const fast_divmod fdm_bits_per_element, BitmaskElementType thread_bitmask,
BitmaskElementType* mask_data) {
int bitmask_idx, bitmask_shift;
fdm_bits_per_element.divmod(id, bitmask_idx, bitmask_shift);
BitmaskElementType bitmask = (thread_bitmask << bitmask_shift);
#if defined(USE_CUDA) && __CUDA_ARCH__ >= 800
BitmaskElementType thread_mask = __match_any_sync(0xFFFFFFFF, bitmask_idx);
bitmask = __reduce_or_sync(thread_mask, bitmask);
#else
#pragma unroll
for (int stride = kNumBitsPerBitmaskElement / (NumUnroll * 2); stride > 0; stride /= 2) {
bitmask |= WARP_SHFL_DOWN(bitmask, stride);
}
// Choose a single from the "thread mask" group to perform the output write.
if (bitmask_shift == 0 && bitmask_idx < mask_element_count) {
mask_data[bitmask_idx] = bitmask;
}
首先fdm_bits_per_element是一个快速除法的操作,除数设置为32(因为这里用uint32_t存储32个bit),他的操作等价于:
bitmask_idx = id / 32; 表示该线程的bitmask应该写到第几个mask_data中
bitmask_shift = id % 32; 表示该线程的bitmask应该偏移到 1个mask中的哪个bit位
而前面我们每个线程处理4个元素,那么对应的id是:
id: 0 4 8 12 ... 28
bitmask_idx: 0 0 0 0 0
bitmask_shift: 0 4 8 12
由于每个线程的thread_bitmask都只有前4位有效,而我们要想把多个线程的thread_bitmask放到一个uint32_t变量中,就需要对其做偏移。1个uint32_t可以存储8个线程的thread_bitmask,一个示意图如下:
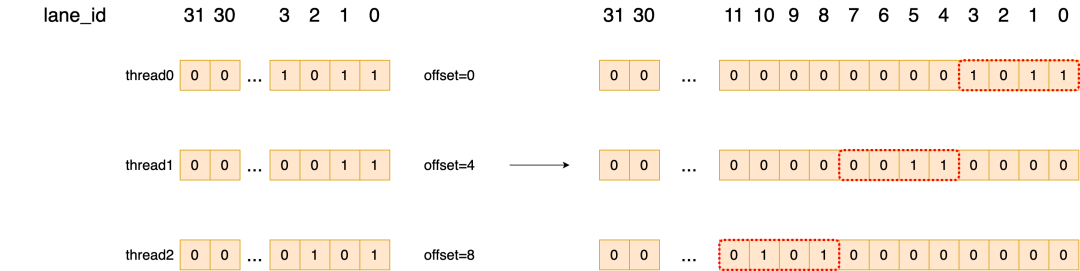
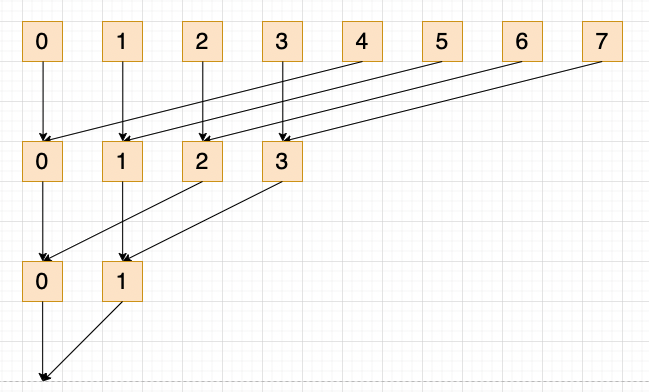
最后就是将所有线程给结合起来,笔者对__match_any_snyc不太熟悉,我们看warp_shfl_down版本的操作,它将stride设置为kNumBitsPerBitmaskElement / (NumUnroll * 2),这里kNumBitsPerBitmaskElemen=32,NumUnroll=4,那是对每8个线程放一起做warp级别的reduce和逻辑或操作,一个线程reduce示意图如下:
我们取第一次reduce中,0号线程和4号线程的操作具体分析:
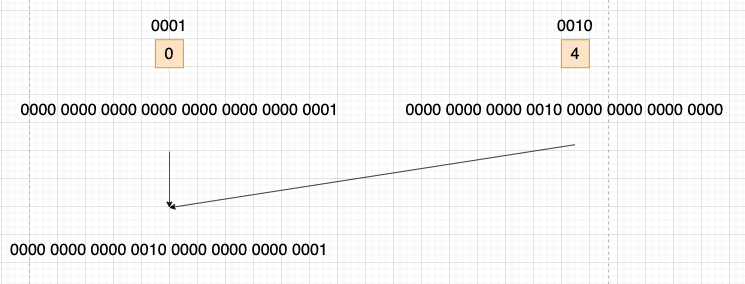
这样就将所有线程的bitmask结合到一起,最后选择第一个线程负责写入到mask_data中
笔者认为这里可能存在部分线程不活跃的情况,warp_shfl_down不应该所有线程参与操作,而是应该用__activemask()
性能数据
OnnxRuntime的PR也有对应的Profile数据:
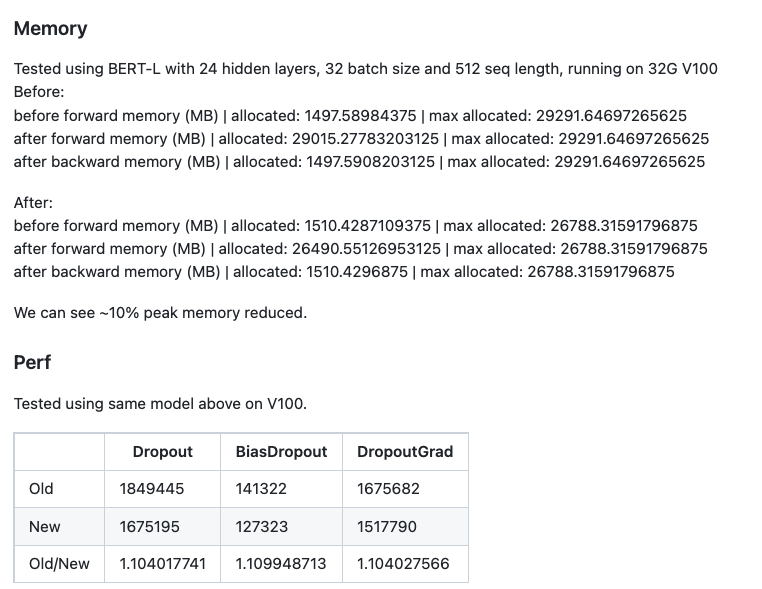
选取了Bert模型,对于峰值显存有10%的减少,而带宽也有10%的提升(一方面是用了bitmask写入数据变少了,另一方面说一般用了向量化优化基本都可以打满带宽)
