
Spark Action 算子
四、Action 算子
1. reduce
对整个结果集规约, 最终生成一条数据, 是整个数据集的汇总。
reduce 和 reduceByKey 完全不同, reduce 是一个 action, 并不是 Shuffled 操作,本质上 reduce 就是现在每个 partition 上求值, 最终把每个 partition 的结果再汇总。
例如:
- scala:
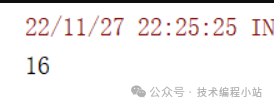
var p1 = sc.parallelize(Seq(1, 2, 3, 4, 6))
println(
p1.reduce((_+_))
)
- java:
JavaRDD<Integer> p1 = sc.parallelize(Arrays.asList(1, 2, 3, 4, 6));
System.out.println(
p1.reduce(Integer::sum)
);
- python:
p1 = sc.parallelize((1, 2, 3, 4, 6))
print(
p1.reduce(lambda i1, i2: i1 + i2)
)
2. collect
以数组的形式返回数据集中所有元素。例如:
- scala:
var p1 = sc.parallelize(Seq(1, 2, 3, 4, 6))
println(
p1.collect()
)
- java:
JavaRDD<Integer> p1 = sc.parallelize(Arrays.asList(1, 2, 3, 4, 6));
System.out.println(
p1.collect()
);
- python:
p1 = sc.parallelize((1, 2, 3, 4, 6))
print(
p1.collect()
)
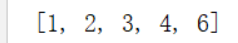
3. count
数据元素个数:
例如:
- scala:
var p1 = sc.parallelize(Seq(1, 2, 3, 4, 6))
println(
p1.count()
)
- java:
JavaRDD<Integer> p1 = sc.parallelize(Arrays.asList(1, 2, 3, 4, 6));
System.out.println(
p1.count()
);
- python:
p1 = sc.parallelize((1, 2, 3, 4, 6))
print(
p1.count()
)
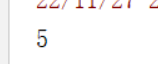
4. first
返回第一个元素:
例如:
- scala:
var p1 = sc.parallelize(Seq(1, 2, 3, 4, 6))
println(
p1.first()
)
- java:
JavaRDD<Integer> p1 = sc.parallelize(Arrays.asList(1, 2, 3, 4, 6));
System.out.println(
p1.first()
);
- python:
p1 = sc.parallelize((1, 2, 3, 4, 6))
print(
p1.first()
)
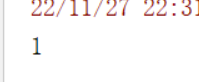
5. countByKey
求得整个数据集中 Key 以及对应 Key 出现的次数:
例如:
- scala:
val s1 = sc.parallelize(Seq("abc", "abc", "hello", "hello", "word", "word"))
println(
s1.map((_,1)).countByKey()
)
- java:
JavaRDD<String> s1 = sc.parallelize(Arrays.asList("abc", "abc", "hello", "hello", "word", "word"))
System.out.println(
s1.mapToPair(s -> new Tuple2<>(s, 1)).countByKey()
);
- python:
s1 = sc.parallelize(("abc", "abc", "hello", "hello", "word", "word"))
print(
s1.map(lambda s: (s, 1)).countByKey()
)

6. take
返回前 N 个元素:
例如:
- scala:
val s1 = sc.parallelize(Seq("abc", "abc", "hello", "hello", "word", "word"))
println(
s1.take(3)
)
- java:
JavaRDD<String> s1 = sc.parallelize(Arrays.asList("abc", "abc", "hello", "hello", "word", "word"));
System.out.println(
s1.take(3)
);
- python:
s1 = sc.parallelize(("abc", "abc", "hello", "hello", "word", "word"))
print(
s1.take(3)
)

7. saveAsTextFile
将结果存入 path 对应的目录中:
例如:
- scala:
val s1 = sc.parallelize(Seq("abc", "abc", "hello", "hello", "word", "word"))
s1.saveAsTextFile("D:/test/output/text/")
- java:
JavaRDD<String> s1 = sc.parallelize(Arrays.asList("abc", "abc", "hello", "hello", "word", "word"));
s1.saveAsTextFile("D:/test/output/text/");
- python:
s1 = sc.parallelize(("abc", "abc", "hello", "hello", "word", "word"))
s1.saveAsTextFile("D:/test/output/text/")
8. lookup
根据 key 查询对应的 value :
例如:
- scala:
val s1 = sc.parallelize(Seq("小明:15.5", "小明:13.3", "张三:14.4", "张三:37.6", "李四:95.9", "李四:45.4"))
println(
s1.map(s=>(s.split(":")(0),s.split(":")(1).toDouble))
.lookup("小明").toList
)
- java:
JavaRDD<String> s1 = sc.parallelize(Arrays.asList("小明:15.5", "小明:13.3", "张三:14.4", "张三:37.6", "李四:95.9", "李四:45.4"));
System.out.println(
s1.mapToPair(s -> new Tuple2<>(s.split(":")[0], Double.parseDouble(s.split(":")[1])))
.lookup("小明")
);
- python:
s1 = sc.parallelize(("小明:15.5", "小明:13.3", "张三:14.4", "张三:37.6", "李四:95.9", "李四:45.4"))
print(
s1.map(lambda s: (s.split(":")[0], float(s.split(":")[1])))
.lookup("小明")
)

五、补充算子
1. RDD 持久化
对于需要复用的RDD,可以进行缓存,已防止重复计算,持久化主要有三个算子,cache、persist、Checkpoint,其中persist可以指定存储的类型,是硬盘还是内存,cache 底层调用的 persist 默认存储在内存中 ,Checkpoint 则可以存储在 HDFS 中:
例如:
- scala:
val s1 = sc.parallelize(Seq("小明:15.5", "小明:13.3", "张三:14.4", "张三:37.6", "李四:95.9", "李四:45.4"))
//缓存
s1.cache // 底层调用的 persist
//持久化
s1.persist(StorageLevel.MEMORY_AND_DISK) //使用内存和磁盘(内存不够时才使用磁盘)
s1.persist(StorageLevel.MEMORY_ONLY) //持久化到内存
// Checkpoint 应使用Checkpoint把数据发在HDFS上
sc.setCheckpointDir("/data/spark/") //实际中写HDFS目录
s1.checkpoint()
//清空缓存
s1.unpersist()
- java:
JavaRDD<String> s1 = sc.parallelize(Arrays.asList("小明:15.5", "小明:13.3", "张三:14.4", "张三:37.6", "李四:95.9", "李四:45.4"));
//缓存
s1.cache(); // 底层调用的 persist
//持久化
s1.persist(StorageLevel.MEMORY_AND_DISK()); //使用内存和磁盘(内存不够时才使用磁盘)
s1.persist(StorageLevel.MEMORY_ONLY()); //持久化到内存
// Checkpoint 应使用Checkpoint把数据发在HDFS上
sc.setCheckpointDir("/data/spark/");//实际中写HDFS目录
s1.checkpoint();
//清空缓存
s1.unpersist();
- python:
s1 = sc.parallelize(("小明:15.5", "小明:13.3", "张三:14.4", "张三:37.6", "李四:95.9", "李四:45.4"))
# 缓存
s1.cache() # 底层调用的persist
# 持久化
s1.persist(StorageLevel.MEMORY_AND_DISK) # 使用内存和磁盘(内存不够时才使用磁盘)
s1.persist(StorageLevel.MEMORY_ONLY) # 持久化到内存
# Checkpoint 使用Checkpoint把数据发在HDFS上
sc.setCheckpointDir("/data/spark/") # 实际中写HDFS目录
s1.checkpoint()
# 清空缓存
s1.unpersist()
2. 共享变量,累加器
支持在所有 不同节点上进行全局累加计算:
例如:
- scala:
//创建一个计数器/累加器
var ljq = sc.longAccumulator("mycounter")
ljq.add(2)
println(ljq.value)
- java:
SparkContext sparkContext = JavaSparkContext.toSparkContext(sc);
//创建一个计数器/累加器
LongAccumulator ljq = sparkContext.longAccumulator("mycounter");
ljq.add(2);
System.out.println(ljq.value());
- python:
ljq = sc.accumulator("mycounter")
ljq.add(2)
print(ljq.value)
3. 共享变量,广播变量
支持在所有 不同节点上进行全局累加计算:
例如:
- scala:
val list = Seq(1, 2, 3, 4, 6)
val broadcast = sc.broadcast(list)
val value = broadcast.value
println(value.toList)
- java:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 6);
Broadcast<List<Integer>> broadcast = sc.broadcast(list);
List<Integer> value = broadcast.getValue();
System.out.println(value);
- python:
list = (1, 2, 3, 4, 6)
broadcast = sc.broadcast(list)
value = broadcast.value
print(value)
评论