
【论文解读】训练更快,泛化更强的Dropout:Multi-Sample Dropout
论文简介:大幅减少训练迭代次数,提高泛化能力:Multi-Sample Dropout
论文标题:Multi-Sample Dropout for Accelerated Training and Better Generalization
论文链接:https://arxiv.org/pdf/1905.09788.pdf
论文作者:{Hiroshi Inoue}
论文简介
本文阐述的也是一种 dropout 技术的变形——multi-sample dropout。传统 dropout 在每轮训练时会从输入中随机选择一组样本(称之为 dropout 样本),而 multi-sample dropout 会创建多个 dropout 样本,然后平均所有样本的损失,从而得到最终的损失。这种方法只要在 dropout 层后复制部分训练网络,并在这些复制的全连接层之间共享权重就可以了,无需新运算符。通过综合 M 个 dropout 样本的损失来更新网络参数,使得最终损失比任何一个 dropout 样本的损失都低。这样做的效果类似于对一个 minibatch 中的每个输入重复训练 M 次。因此,它大大减少了训练迭代次数。
Multi-Sample Dropout
图 1 是一个简单的 multi-sample dropout 实例,作图为我们经常在炼丹中用到的“流水线”Dropout,在图片中这个 multi-sample dropout 使用了 2 个 dropout 。该实例中只使用了现有的深度学习框架和常见的操作符。如图所示,每个 dropout 样本都复制了原网络中 dropout 层和 dropout 后的几层,图中实例复制了「dropout」、「fully connected」和「softmax + loss func」层。在 dropout 层中,每个 dropout 样本使用不同的掩码来使其神经元子集不同,但复制的全连接层之间会共享参数(即连接权重),然后利用相同的损失函数,如交叉熵,计算每个 dropout 的损失,并对所有 dropout 样本的损失值进行平均,就可以得到最终的损失值。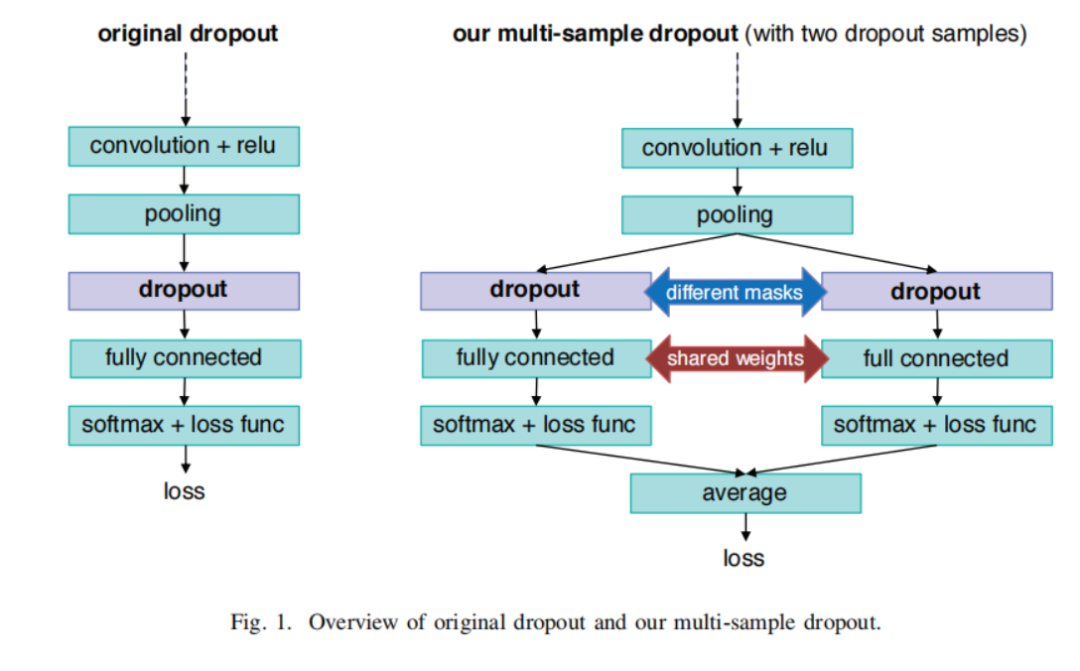 该方法以最后的损失值作为优化训练的目标函数,以最后一个全连接层输出中的最大值的类标签作为预测标签。当 dropout 应用于网络尾段时,由于重复操作而增加的训练时间并不多。值得注意的是,multi-sample dropout 中 dropout 样本的数量可以是任意的,而图 1 中展示了有两个 dropout 样本的实例。
该方法以最后的损失值作为优化训练的目标函数,以最后一个全连接层输出中的最大值的类标签作为预测标签。当 dropout 应用于网络尾段时,由于重复操作而增加的训练时间并不多。值得注意的是,multi-sample dropout 中 dropout 样本的数量可以是任意的,而图 1 中展示了有两个 dropout 样本的实例。
另外需要注意的是,神经元在推理过程中是不会被忽略的。只计算一个 dropout 样本的损失是因为 dropout 样本在推理时是一样的,这样做可以对网络进行修剪以消除冗余计算。要注意的是,在推理时使用所有的 dropout 样本并不会严重影响预测性能,只是稍微增加了推理时间的计算成本。
Pytorch实现
https://github.com/lonePatient/multi-sample_dropout_pytorch
在初始化方法中,定义了一个ModuleList,包含多个Dropout, 在forward中,对样本进行多次dropout,最后对out求平均,对loss求平均。其中,dropout_num为超参数,表示Multi-Sample中,Multi的具体值,核心代码如下:
self.dropouts = nn.ModuleList([nn.Dropout(dropout_p) for _ in range(dropout_num)])
完整ResNet模型结构:
class ResNet(nn.Module):
def __init__(self, ResidualBlock, num_classes,dropout_num,dropout_p):
super(ResNet, self).__init__()
self.inchannel = 32
self.conv1 = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU(),
)
self.layer1 = self.make_layer(ResidualBlock, 32, 2, stride=1)
self.layer2 = self.make_layer(ResidualBlock, 64, 2, stride=2)
self.layer3 = self.make_layer(ResidualBlock, 64, 2, stride=2)
self.layer4 = self.make_layer(ResidualBlock, 128, 2, stride=2)
self.fc = nn.Linear(128,num_classes)
self.dropouts = nn.ModuleList([nn.Dropout(dropout_p) for _ in range(dropout_num)])
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) #strides=[1,1]
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x,y = None,loss_fn = None):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
feature = F.avg_pool2d(out, 4)
if len(self.dropouts) == 0:
out = feature.view(feature.size(0), -1)
out = self.fc(out)
if loss_fn is not None:
loss = loss_fn(out,y)
return out,loss
return out,None
else:
for i,dropout in enumerate(self.dropouts):
if i== 0:
out = dropout(feature)
out = out.view(out.size(0),-1)
out = self.fc(out)
if loss_fn is not None:
loss = loss_fn(out, y)
else:
temp_out = dropout(feature)
temp_out = temp_out.view(temp_out.size(0),-1)
out =out+ self.fc(temp_out)
if loss_fn is not None:
loss = loss+loss_fn(temp_out, y)
if loss_fn is not None:
return out / len(self.dropouts),loss / len(self.dropouts)
return out,None
Bert如何使用Multi-Sample Dropout
于BERT家族模型使用了很多Dropout,采用上述实现过于复杂,一种更简单的实现:
for step, (input_ids, attention_mask, token_type_ids, y) in enumerate(tk):
input_ids, attention_mask, token_type_ids, y = input_ids.to(device), attention_mask.to(
device), token_type_ids.to(device), y.to(device).long()
with autocast():
for i in range(batch_n_iter):
output = model(input_ids, attention_mask, token_type_ids).logits
loss = criterion(output, y) / CFG['accum_iter']
SCALER.scale(loss).backward()
SCALER.step(optimizer)
SCALER.update()
optimizer.zero_grad()
其中,batch_n_iter为超参数,表示Multi-Sample中,Multi的具体值。
如果大家用抱抱脸的话,可以按照下面模板设置:
class multilabel_dropout():
# Multisample Dropout 论文: https://arxiv.org/abs/1905.09788
def __init__(self, HIGH_DROPOUT, HIDDEN_SIZE):
self.high_dropout = torch.nn.Dropout(config.HIGH_DROPOUT)
self.classifier = torch.nn.Linear(config.HIDDEN_SIZE * 2, 2)
def forward(self, out):
return torch.mean(torch.stack([
self.classifier(self.high_dropout(p))
for p in np.linspace(0.1,0.5, 5)
], dim=0), dim=0)
Multi-Sample Dropout作用
关于原理的话,因为发现网上写的很全了,这里偷懒了,大家可以看参考资料,这里主要给大家提供下代码了。
大幅减少训练迭代次数 提高泛化能力
参考资料
Multi-Sample Dropout for Accelerated Training and Better Generalization
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 机器学习在线手册 深度学习笔记专辑 《统计学习方法》的代码复现专辑 AI基础下载 本站qq群955171419,加入微信群请扫码: