
回顾6年深度学习算法实践和演进
作者:Peter(滑铁卢大学 计算机)
原文链接:https://zhuanlan.zhihu.com/p/464515049
本文转载自知乎,著作权归属原作者,如有侵权,请联系删文。
01
这篇文章更多是结合自己实践经历,通过一些业界经典成果回顾了过去6年在深度学习算法方向上的技术迭代。最后做了一些归纳总结和展望。
02
先对语音做一系列信号处理,转换成中间格式,比如filter-bank。 然后还会经过提取phoneme(音素)的阶段。 再经过一些语言模型,路径搜索,词表等复杂流程。 最后产生文字结果。
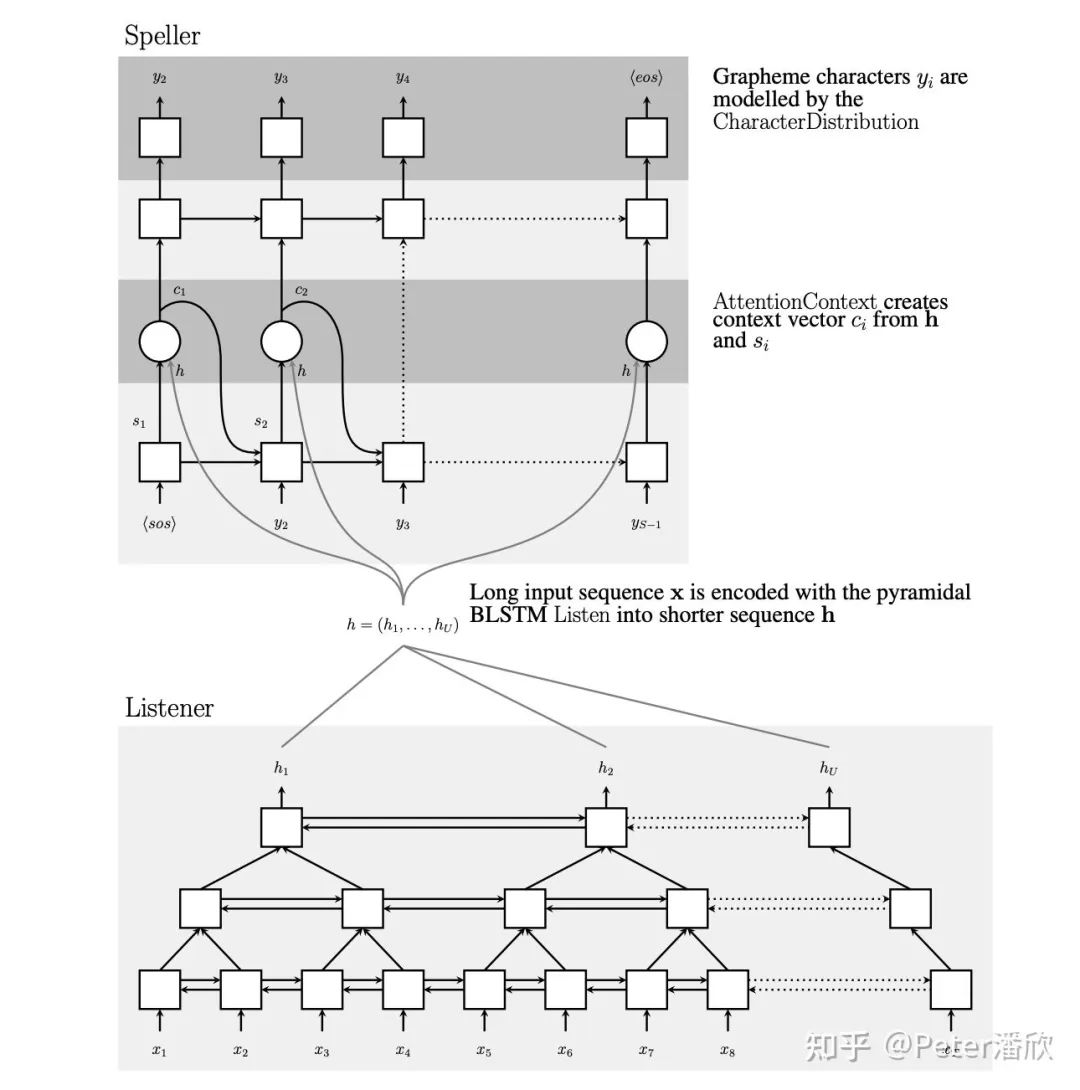
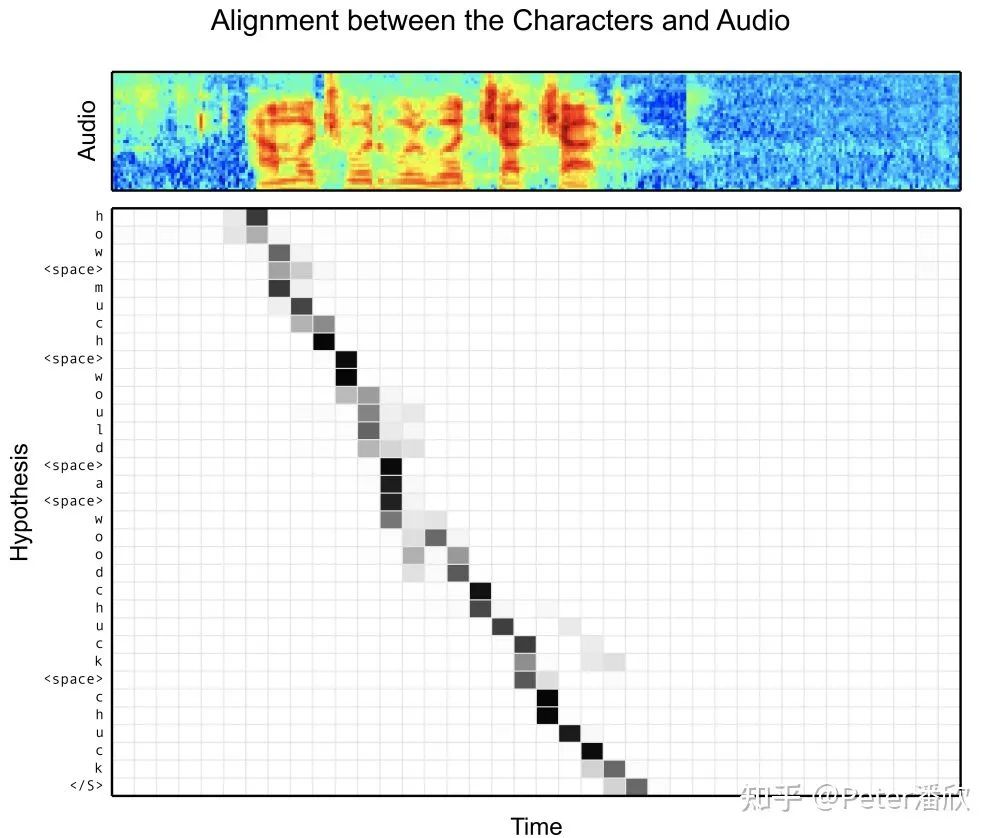
端到端语音识别。相比传统多阶段方法,这个模型使用filter-bank spectra作为输入,通过seq2eq with attention的结构直接输出了语言文字。在没有附加外部语言模型的情况下就达到了14%的WER。附加语言模型达到10%的WER。 在当时的K40 GPU算力下,这个模型的复杂度是非常高的。其中多层bi-lstm encoder在序列比较长的时候几乎训不动。为了解决这个问题,采用了金字塔结构的encoder,逐层降低序列长度。 attention机制帮助decoder能够提取encoder sequence重要信息,显著提升解码的效果。同时decoder内部隐式学习了语言模型。
03
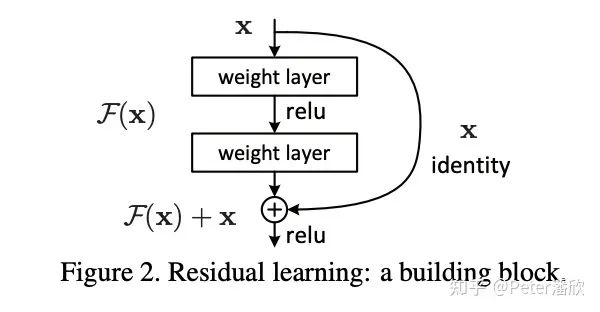
后来我把早期完全没有性能优化(那会还没有FuseBatchNorm)的ResNet放到tensorflow model zoo github上开源了。AWS和一些机构没有调优就拿过去做了一些benchmark,得出tensorflow性能远差于其他框架的结论。TensorFlow的老板们表示非常不满,于是tensorflow 1.0版发布专门搞了个官方优化的性能benchmark。
04

05
AlphaGo先从人类走棋数据集上学习policy network。监督数据就是基于当前棋局s,预测人类行为a。 初步学习后,AlphaGo再和自己玩,用RL的policy gradient进一步优化policy network,提升行为准确性。 然后用policy network生成很对局数据,数据用来训练value network。value network简单来说就是预判当前局势的胜率。
AlphaGo会基于MCTS去探索子树(类似人类心中演绎棋局不同走势。演绎多长,越接近结局,预判越准)。其中探索过程会基于前面说的policy network和value network。还会用一个小policy network快速走棋到结束得到一个大概结果。 基于子树的探索,AphaGo就能够进一步加强对于不同行动的判断准确性,进而采取更优的决策。
其中一个用强化学习去发现更好的gpu device placement,让机器翻译模型能有更好的GPU分布式训练速度。 另一个用它去搜索模型结构,也就是那篇Neural Architecture Search (NAS)。它发现了更好的训练imagenet的backbone,效果要超过SOTA的ResNet等模型。这个技术后来被逐渐泛化成了AutoML。
06
07



使用预训练VGG模型某些中间层的输出作为feature extractors。 其中一些feature extractors的输出叫做content feature,另一些层的feature extractors输出经过gram matrix计算后的值叫做style feature。用VGG分别算出来原始图片(上图中的狗)的content feature,和style图片(上图中的艺术图片)的style feature。 loss = content loss + style loss。content loss是当前content feature和上一步中保存的原始图片content feature的差。用来保障图片还有原来狗的轮廓。而style loss是狗狗照片style值和艺术图片style值的差。让狗狗照片的style越来越接近艺术图片。 两个loss互相平衡,让vgg feature extractors既能够保留原图像的轮廓,同时还能添加出style。但是原狗狗图片和艺术照图片的style显然不一样,所以开始时style loss会比较大。怎么办? 解法就是将loss反向求出的gradient叠加到原始图片上。满足style loss变小的目的。经过几轮的image=image叠加gradient,原始图片image会既有狗的轮廓(content loss),已有艺术图片的style(降低style loss)。
08
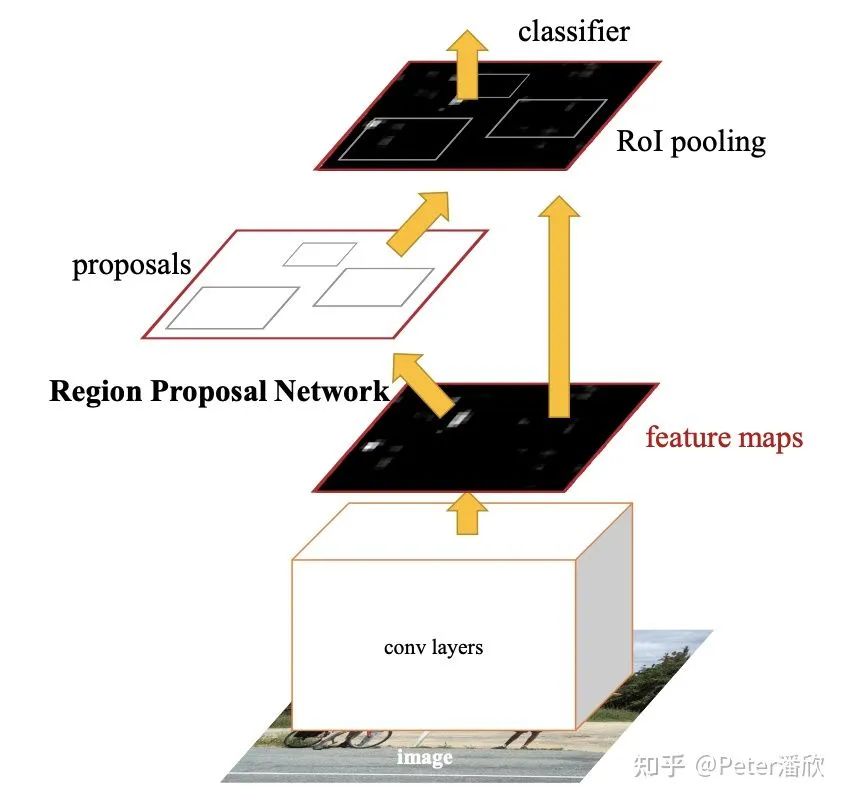
Youtube BoundingBox

底座通常是个基于图片分类模型预训练的feature extractor,比如ResNet50。 接着是在feature map上找box。通常是每个位置上有多个不同预制大小规格的box。 同时还要对每个box进行分类。
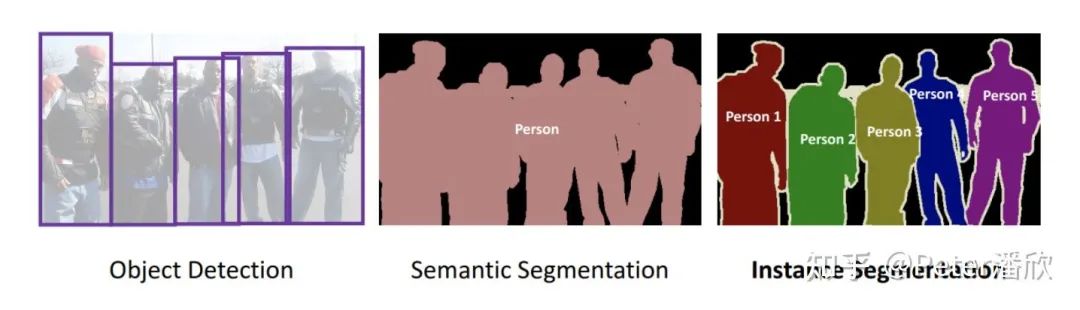
GoogleMap Segmentation
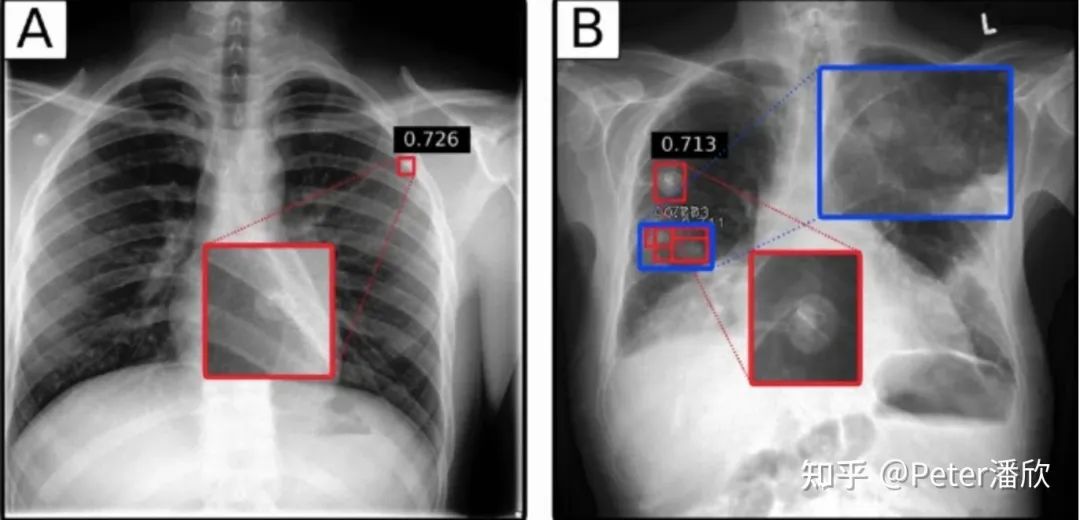
医疗影像的应用
09

10
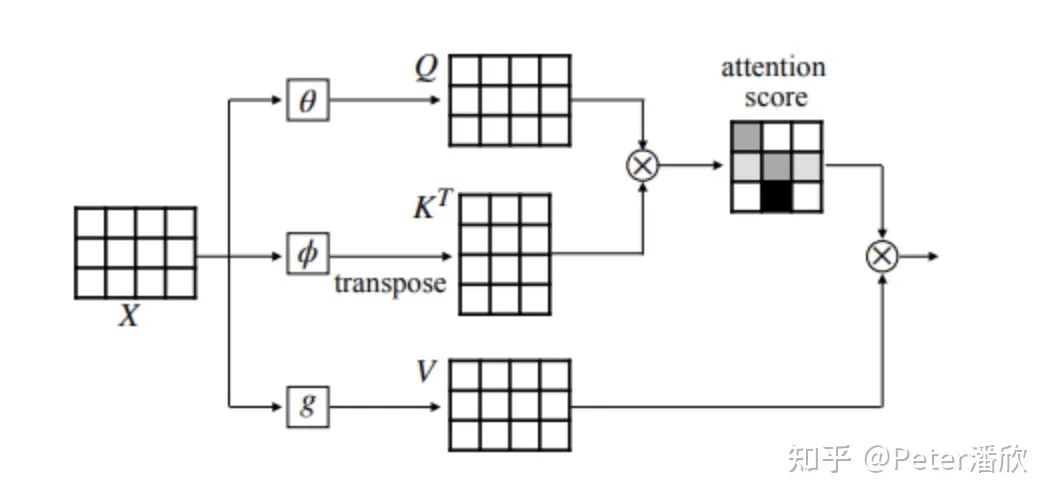
Self-Supervise和大模型
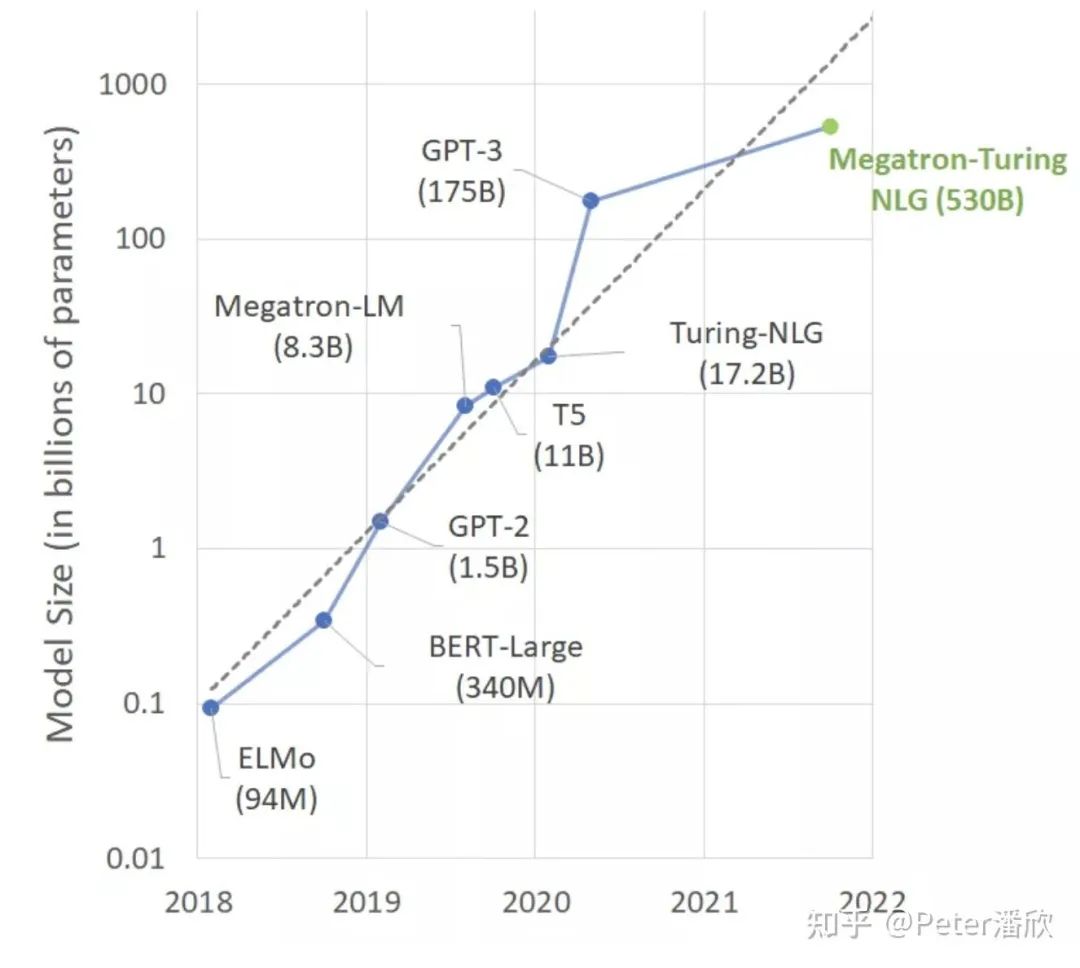
随着模型规模的增长,我们似乎正在打开AI更高阶段的另一扇门。和之前“小”模型相比,这些巨型模型有一些更接近人的特殊能力,比如:
One-shot, Few-shot Learning。使用很少的样本就能在大模型的基础上训练获得新领域的能力。 Multi-Tasking。这些大的预训练模型可以被用在很多不同的任务上。之前卷积feature extractor也有类似的能力,但是相对局限一些。
11
bfloat16。17年的时候,TPU训练卡的底层开发已经完成,为了让TensorFlow用户更好的使用TPU,需要整个python层完成bfloat16支持,并打通C++层的XLA。基于实验分析,bfloat16缓解了float16在梯度很小的时候容易round to zero的问题,保留了更多exponential bits,牺牲了不那么重要的precision bits。 int16, int8, int4。量化(quantization)和定点数计算取得了不错的成果。一方面是节省了空间,另外硬件定点数的计算效率也通常更高。比如在GPU上int8的理论速度可以比float32高一个数量级。int16可以被应用在部分模型的训练上,int8和int4等则多是在推理模型的存储和计算上使用。量化技术看似简单,其实细节很多,这里稍微展开一点: training-aware or not。在训练时就进行量化可以减少一些效果的损失。 黑白名单。许多算子是对量化不友好的(e.g. conv vs softmax)。通常对于不友好的算子,会在前面插入反量化逻辑,回到浮点数。 min-max rounding。如果简单使用min-max作为上下界,很可能因为某个outlier导致大部分数值的解析度太低。因此会有许多方法自动计算合理的min-max。将outlier clip到min or max。 Distillation。有时也叫teacher-student。用一个大模型的中间输出去调教一个小模型。蒸馏的变种也很多,比如co-distillation,三个臭皮匠顶个诸葛亮。我们在推荐排序领域,用精排去蒸馏粗排、召回取得了不错的成果。 Sparsification。前面提到DNN模型有大量参数其实是无效的。很多裁剪技术也都证明了这一点。通过一些技术(比如是loss中增加相关约束),可以让有效的参数远离0,无效的参数逼近0。在通过一些结构化的技术,可以裁剪调模型中很大一部分,而保障效果无损,或者损失较少。 Jeff看中的Pathway里稀疏激活不知是否也可以归到这一类。这是一个很诱人,也是一个非常难的方向。诱人在于不但可以将模型压缩几个数量级,理论计算量和能耗都能大幅压缩。艰难在于现在硬件和模型训练方式都不容易达到这个目标。但是,人脑似乎就是这么工作的。人类在思考的时候,大脑只有比较少的一部分被激活。
12
“大多数”是因为互联网公司的主要AI算力其实都消耗在推荐排序类的深度学习模型上了。这些模型不但承载了互联网公司的主要业务形态(比如电商和视频的推荐),还承担了公司关键收入来源(比如广告推荐)。 “沉默”是说深度学习的技术突破和首先应用通常不源于这个方向,而更多来自于CV,NLP等更基础的方面。许多推荐排序技术的提升大多来自于CV,NLP成功技术的跨领域应用。深度学习领域的顶级研究员也相对少提到推荐排序相关的问题(有可能是个人局限性视角)。
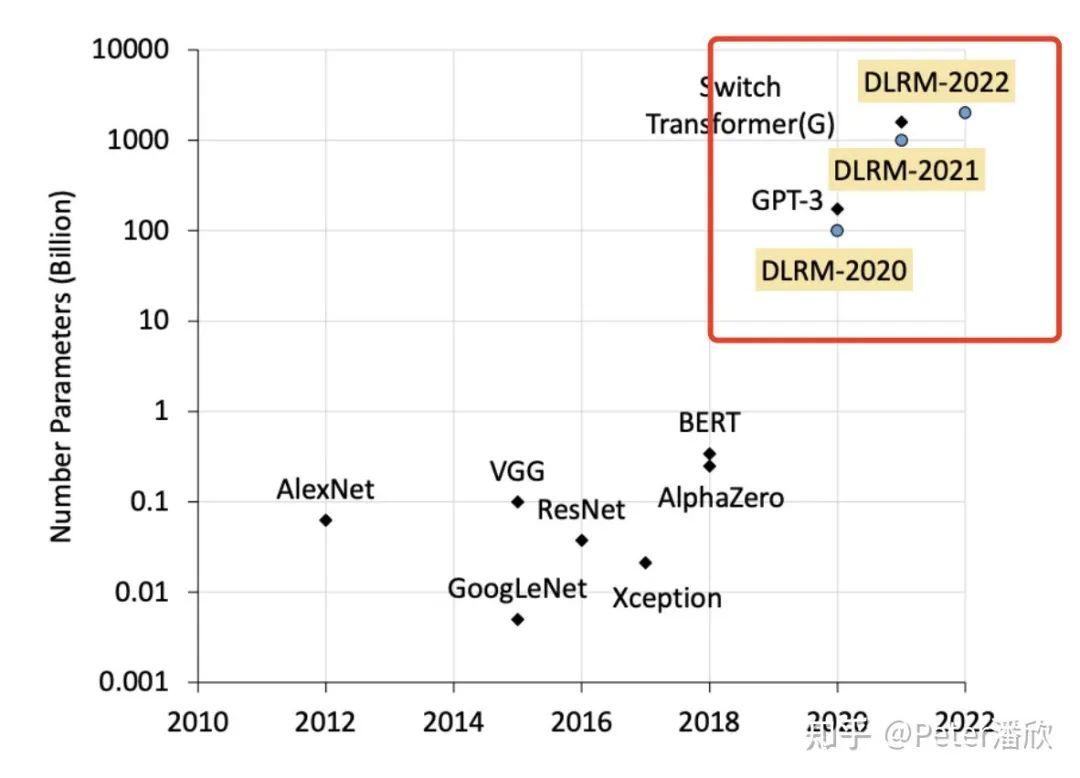
海量的Embedding和渺小的DNN
LR,FM,FFM,WDL,MMOE
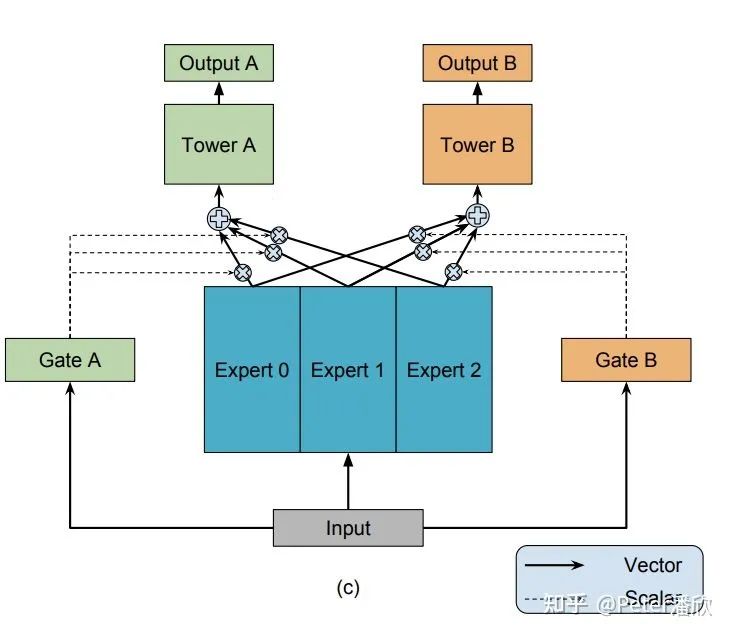
Tower, Tree, Graph
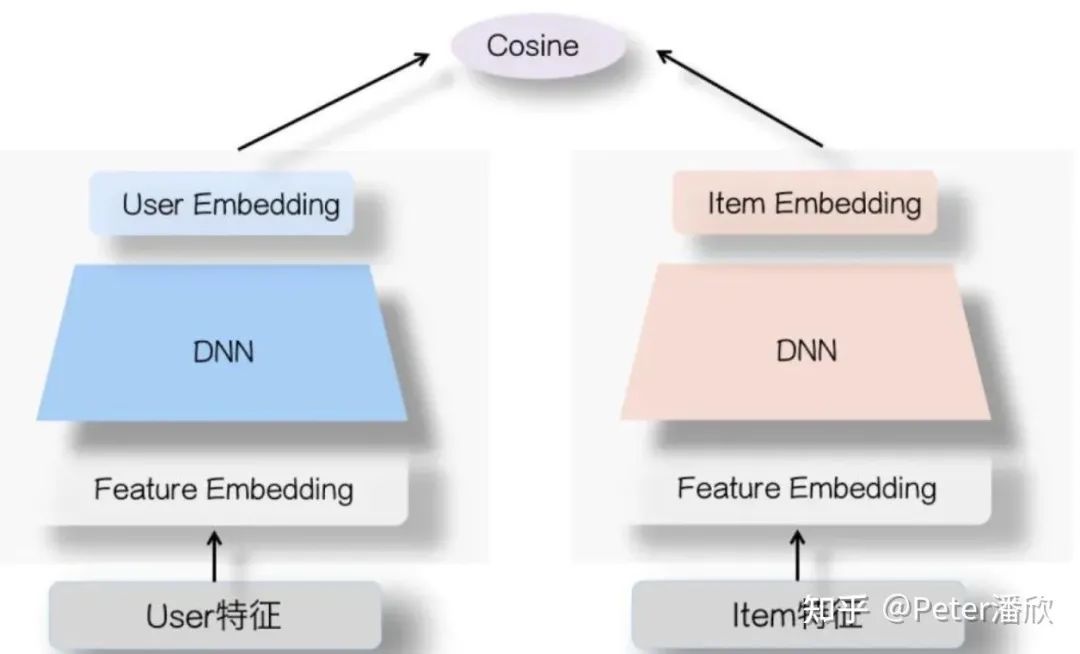
多场景,端到端,预训练
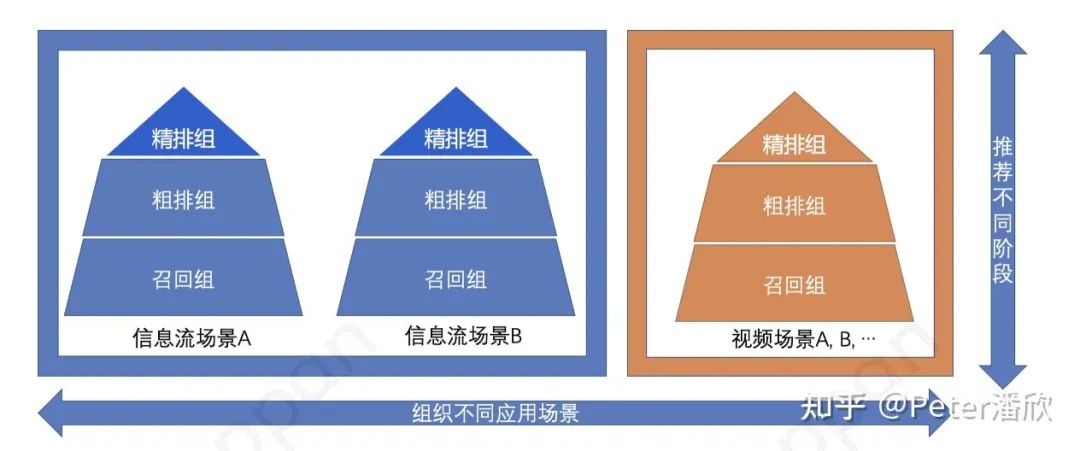
横向来看,构造多场景的异构图,或者通过share和independent feature的方式构造多业务场景的MMOE模型。基于更丰富的数据进行预训练,而后应用在子场景上。这种方式对对于新用户和中小场景的提升尤其明显。 纵向上看,通过一次性训练任务同时训练召回、粗排、精排模型。利用精排更复杂和精准的预测结果来蒸馏前面两个阶段。这种方式一方面可以显著提升召回、粗排的效果,也可以压缩粗排模型的体积。
13
更宽、更深、更大的模型持续带来效果和能力上的惊喜,但是似乎在22年走到了一个反思的节点。用VGG的100M和Megatron的530B相比,规模提升了1000~10000倍。然而,规模的边际效用降低,能耗和迭代效率都成为较大的问题。 模型越来越全能,算法越来越归一。放在10年前,CV和NLP的研究员可能风马牛不相及。但是现在我发现CV,NLP,语音的SOTA模型都能用上Transformer结构,都能用上自监督训练。而且模型能够编码多种模态的输入。 可解释,可控性,可预测能力依然没有突破。就好像对人脑的理解一样,对于深度学习模型的理解依然很单薄。或许高维空间本身就是无法被直观理解的。无法被理解的基础上,就不容易被管控。通过one-shot似乎可以让模型快速掌握新的能力,但是对于模型其他能力的影响缺失很难判断的。就好比你让一辆车很容易躲避障碍物,却可能导致它侧翻的概率增加。 随机应变和规划能力不足。虽然模型有着超越人类的感知和记忆能力,但是面对复杂世界的行动和决策却相对较弱。从AlphaGo和一些相关工作,可能强化学习是一个可以持续挖掘突破的方向。但是强化学习的发展有可能带来对可控性和可预测性的担忧。假如用强化学习来训练无人机,并用“击中目标”作为Reward。会发生什么?能不能让它“绝不伤害人类”。 算力、数据、算法的进步造就了今天技术成就。但是现在能耗,硬件算力,体系结构(e.g. 冯诺依曼架构、内存墙)都对人工智能的发展产生了制约,可能迈向通用人工智能的路上还需要先进行、更彻底的底层颠覆。
受限能耗、系统性能、模型迭代效率,边际效益递减等因素,模型的规模增长不会像过去几年一样高速,而是朝更高效的模型结构(e.g. Sparse Activation),训练方式(Self-supervise),更高效的部署(e.g. Distillation)发展。 模型的感知和记忆能力会快速、全面超过人类水平,并且固化下来,形成通用化的应用场景。BERT可能只是一个开始,基于视频等复杂环境的自监督学习可能会构建更好的“世界模型”(world model),这个模型的通用能力会进一步的提升。 模型的动态决策能力,复杂场景的应变能力还有较大的发展空间。模型的可解释性、可控性短期可能不会有比较大的突破,但是大的研究机构会持续的投入,并形成一些差异化的竞争力。 深度学习算法和生命科学,金融风控等场景结合,可能会逐步有更多突破性的应用进展。比如在生命科学、生物制药方向,可能会产生影响整个人类物种的技术。而一旦金融风控等领域取得重大突破,社会的许多治理会逐渐从人变成机器。 在虚拟世界(或者说是现在比较火的元宇宙),未来5~10年可能会先出现比较通用的智能体。原因是基于强化学习的相关技术在虚拟世界有较低的迭代成本和安全顾虑。
——The End——

分享
收藏
点赞
在看
评论