
【深度学习】图像去模糊算法代码实践!
1.起源:GAN
结构与原理
在介绍DeblurGANv2之前,我们需要大概了解一下GAN,GAN最初的应用是图片生成,即根据训练集生成图片,如生成手写数字图像、人脸图像、动物图像等等,其主要结构如下:
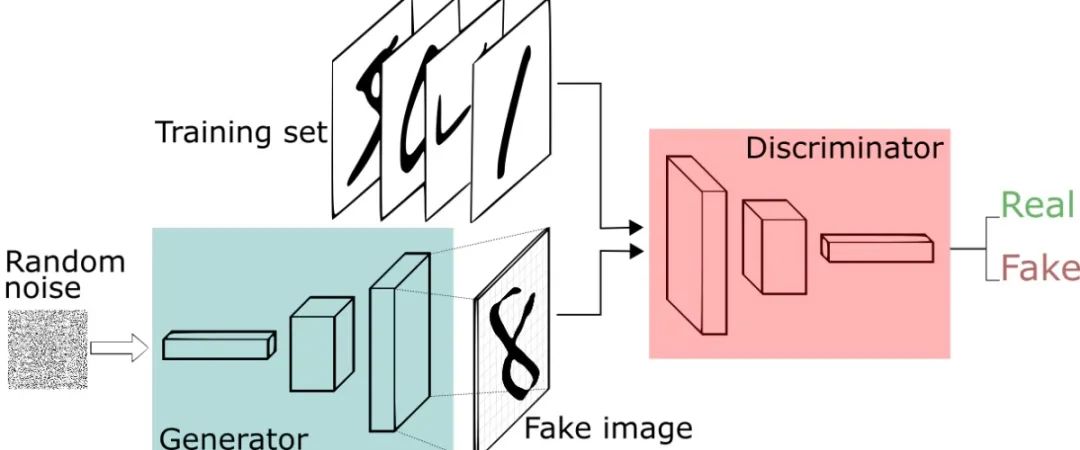
我们先由上图的左下方开始,假设现在只有一个样本,即batch size为1,则Random noise是一个由服从标准正态分布的随机数组成的向量。首先,我们将Random noise输入Generator,最原始GAN的Generator是一个多层感知机,其输入是一个向量,输出也是一个向量,然后我们将输出的向量reshape成一个矩阵,这个矩阵就是一张图片(一个矩阵是因为MNIST手写数据集中的图片是单通道的灰度图,如果想生成彩色图像就reshape成三个矩阵),即与上图的“8”对应。我们称Generator生成的图像为fake image,训练集中的图片为real image。
上图中的Distriminator为判别器,它是一个二分类的多层感知机,输出只有一个数,由于多层感知机只接受向量为其输入,我们将一张图片由矩阵展开为向量后再输入Discriminator,经过一系列运算后输出一个0~1之间的数,这个数越接近于0,代表着判别器认为这张图片是fake image;反之,假如输出的数越接近于1,则判别器认为这张图片是real image。为了方便,我们将Generator简称为G,Distriminator简称为D。
总而言之,G的目的是让自己生成的fake image尽可能欺骗D,而D的任务是尽可能辨别出fake image和real image,二者不停博弈。最终理想情况下,G生成的数据与真实数据非常接近,而D无论输入fake image还是real image都输出0.5。
损失函数
GAN的损失函数是Binary cross entropy loss,简称为BCELoss,其主要利用了极大似然的思想,实际上就是二分类对应的交叉熵损失函数。公式如下:
其中是样本数,是第个样本的真实值,是第个样本的预测值。对于第个样本来说,由于取值只能是0或1,此时只看第个样本,所以。当时,,而的取值范围为0~1,故当时,=0,当时,,我们的目标是使的值越小越好,即当越接近0时,的值越小。反之,当时,,越接近1时,的值越小。总之,当越接近于时,的值越小。
那么BCELoss和GAN有什么关系呢?
我们将GAN的Loss分为和,即生成器的损失和判别器的损失。
对于生成器来说,它希望自己生成的图片能骗过判别器,即希望D(fake)越接近1越好,D(fake)就是G生成的图片输入D后的输出值,D(fake)接近于1意味着G生成的图片可以以假乱真来欺骗判别器,所以GLoss的公式如下所示:
当越接近1,越小,意味着生成器骗过了判别器;
对于判别器来说,它的损失分为两部分,首先,它不希望自己被fake image欺骗,即与相反,这里用表示:
当越接近0,越小,意味着判别器分辨出了fake image;
其次,判别器做出判断必须有依据,所以它需要知道真实图片是什么样的才能正确地辨别假图片,这里用表示:
当越接近1,越小,意味着判别器辨别出了real image。
其实就是这两个损失值的平均值:
优化器
介绍完GAN的损失函数后,我们还剩下最后一个问题:怎么使损失函数的值越来越小?
这里就需要说一下优化器(Optimizer),优化器就是使损失函数值越来越小的工具,常用的优化器有SGD、NAG、RMSProp、Adagrad、Adam和Adam的一些变种,其中最常用的是Adam。
最终结果

由上图我们可以清楚地看出来,随着训练轮数增加,G生成的fake image越来越接近手写数字。
目前GAN有很多应用,每个应用对应的论文和Pytorch代码可以参考下面的链接,其中也有GAN的代码,大家可以根据代码进一步理解GAN:https://github.com/eriklindernoren/PyTorch-GAN
2.图像去模糊算法:DeblurGANv2
数据集
图像去模糊的数据集通常由许多组图像组成,每组图像就是一张清晰图像和与之对应的模糊图像。然而,其数据集的制作并不容易,目前常用的方法有两种,第一种是用高帧数的摄像机拍摄视频,从视频中找到连续帧中的模糊图片和清晰图片作为一组数据;第二种方法是用已知或随机生成的运动模糊核对清晰图片进行模糊操作,生成对应的一组数据。albumentations是Python中常用的数据扩增库,可以对图片进行旋转、缩放、裁剪等操作,我们也可以使用albumentations给图像增加运动模糊,具体操作如下:
首先安装albumentations库,在cmd或虚拟环境中输入:
python -m pip install albumentations
为了给图像添加运动模糊,我们需要用matplotlib库来读取、显示和保存图片。
import albumentations as A
from matplotlib import pyplot as plt
# 读取和显示原图
img = plt.imread('./images/ywxd.jpg')
plt.imshow(img)
plt.axis('off')
plt.show()

albumentations添加运动模糊操作如下,其中blur_limit是卷积核大小的范围,这里卷积核大小在150到180之间,卷积核越大,模糊效果越明显;p是进行运动模糊操作概率。
aug = A.MotionBlur(blur_limit=(50, 80), p=1.0)
aug_img = aug(image=img)['image']
plt.imshow(aug_img)
plt.axis('off')
plt.show()

如果想查看对应的模糊核,我们可以对aug这个实例调用get_params方法,这里为了大家观看方便,我使用的是3*3的卷积核。
aug = A.MotionBlur(blur_limit=(3, 3), p=1.0)
aug.get_params(){'kernel': array([[0. , 0. , 0.33333334],
[0.33333334, 0.33333334, 0. ],
[0. , 0. , 0. ]], dtype=float32)}
我使用的数据集是DeblurGANv1的数据集,链接:https://gas.graviti.cn/dataset/datawhale/BlurredSharp
模糊图片:

清晰图片:

网络结构
DeblurGANv2的思路与GAN大致相同,区别之处在于其对GAN做了大量优化,我们先来看Generator的结构:
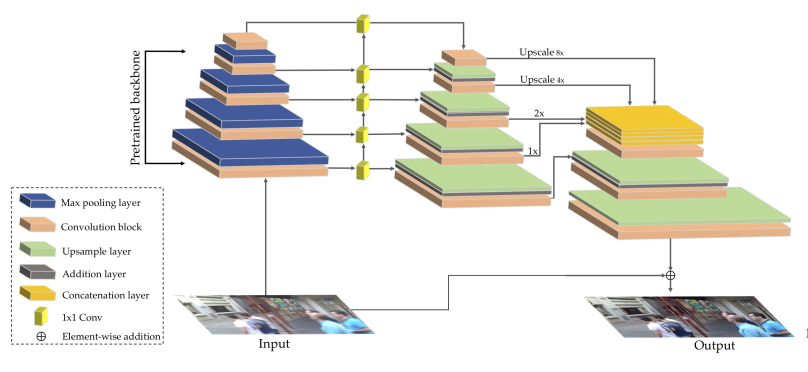
观察上图可以发现,G主要有两个改变:
输入用模糊的图片替代了GAN中的随机向量
网络结构引入了目标检测中的FPN结构,融合了多尺度的特征
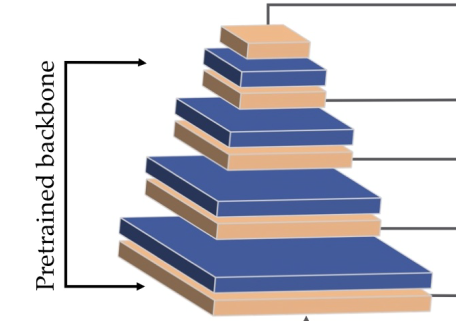
另外,在特征提取部分作者提供了三种网络主干:MobileNetv2、inceptionresnetv2和densenet121,经过作者实验得出,inceptionresnetv2的效果最好,但模型较大,而MobilNetv2在不降低太大效果的基础上大大减少了网络参数,网络主干在上图中对应部分如下所示:
最后,将fpn的输出与原图进行按元素相加操作得到最终输出。
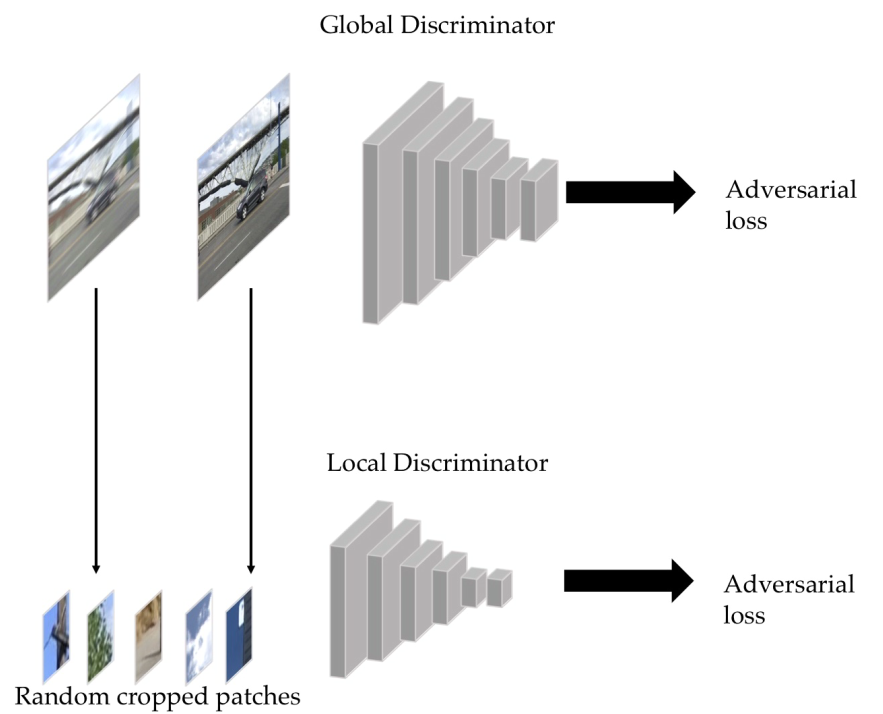
DeblurGANv2的判别器由全局和局部两部分组成,全局判别器输入的是整张图片,局部判别器输入的是随机裁剪后的图片,将输入图片经过一系列卷积操作后输出一个数,这个数代表判别器认为其为real image的概率,判别器的结构如下所示:
损失函数
DeblurGANv2与GAN差别最大的部分就是它的损失函数,我们首先看看D的loss:
D的目的是为了辨别图片的真假,所以D(fake)越小,D(real)越大时,代表D能很好地判断图片的真假,故对于D来说,越小越好
为了防止过拟合,后面还会加上一个L2惩罚项:
G的loss较D复杂很多,它由和组成,其实就是一个perceptual loss,它其实就是将real image和fake image分别输入vgg19,将输出的特征图做MSELoss(均方误差),而作者在perceptual loss的基础上又做了一些改变,公式可以总结为下式:
由公式可以很容易推断,的作用就是让G生成的图片和原图尽可能相似来达到去模糊的目的。
对于来说,其可以总结为下面公式:
由于G的目的是尽可能以假乱真骗过D,所以和越接近于1越好,即越小越好。
最后,G的loss如下所示:
作者给出的lambda为0.001,可以看出作者更注重生成图像与原图的相似性。
3.代码实践
训练自己的数据集
(目前仅支持gpu训练!)
github项目地址:https://github.com/VITA-Group/DeblurGANv2
数据地址:https://gas.graviti.cn/dataset/datawhale/BlurredSharp
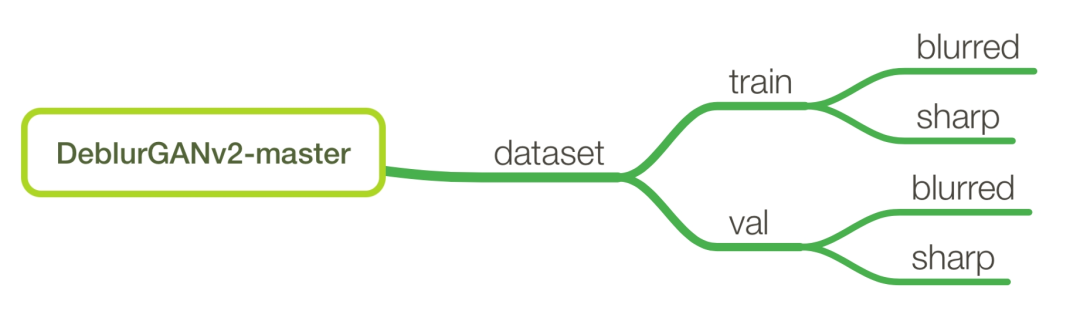
首先将数据文件夹和项目文件夹按照下面结构放置:
安装python环境,在cmd中输入:
conda create -n deblur python=3.9
conda activate deblur
python -m pip install -r requirements.txt
修改config文件夹中的配置文件config.yaml:
project: deblur_gan
experiment_desc: fpn
train:
files_a: &FILES_A ./dataset/train/blurred/*.png
files_b: &FILES_B ./dataset/train/sharp/*.png
size: &SIZE 256
crop: random
preload: &PRELOAD false
preload_size: &PRELOAD_SIZE 0
bounds: [0, .9]
scope: geometric
corrupt: &CORRUPT
- name: cutout
prob: 0.5
num_holes: 3
max_h_size: 25
max_w_size: 25
- name: jpeg
quality_lower: 70
quality_upper: 90
- name: motion_blur
- name: median_blur
- name: gamma
- name: rgb_shift
- name: hsv_shift
- name: sharpen
val:
files_a: &FILE_A ./dataset/val/blurred/*.png
files_b: &FILE_B ./dataset/val/sharp/*.png
size: *SIZE
scope: geometric
crop: center
preload: *PRELOAD
preload_size: *PRELOAD_SIZE
bounds: [.9, 1]
corrupt: *CORRUPT
phase: train
warmup_num: 3
model:
g_name: resnet
blocks: 9
d_name: double_gan # may be no_gan, patch_gan, double_gan, multi_scale
d_layers: 3
content_loss: perceptual
adv_lambda: 0.001
disc_loss: wgan-gp
learn_residual: True
norm_layer: instance
dropout: True
num_epochs: 200
train_batches_per_epoch: 1000
val_batches_per_epoch: 100
batch_size: 1
image_size: [256, 256]
optimizer:
name: adam
lr: 0.0001
scheduler:
name: linear
start_epoch: 50
min_lr: 0.0000001
如果是windows系统需要删除train.py第180行
然后在cmd中cd到项目路径并输入:
python train.py
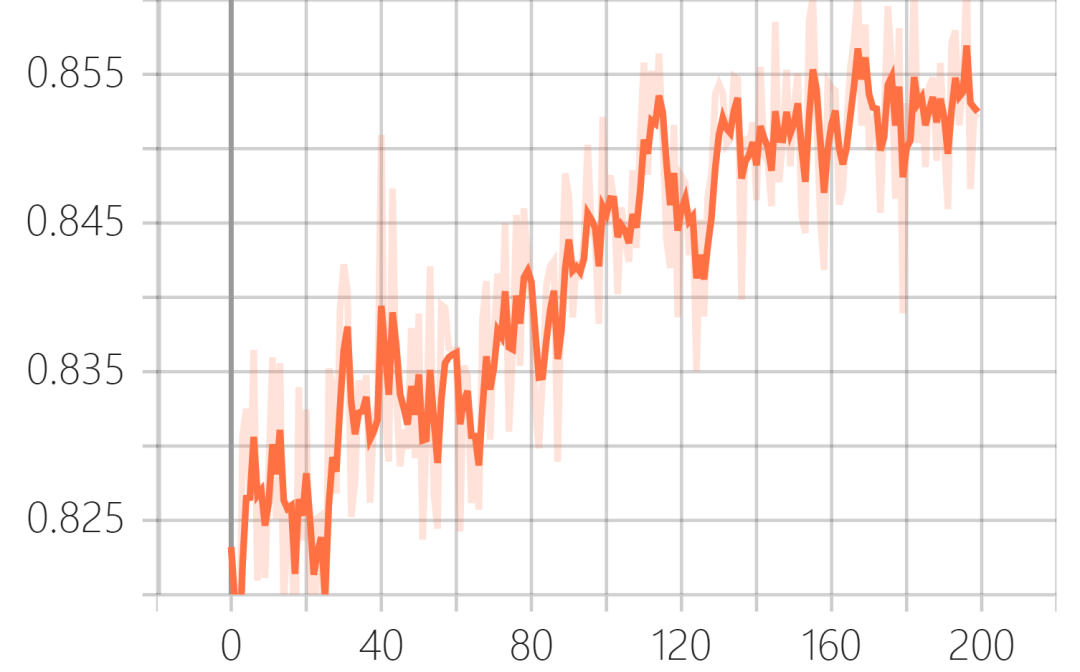
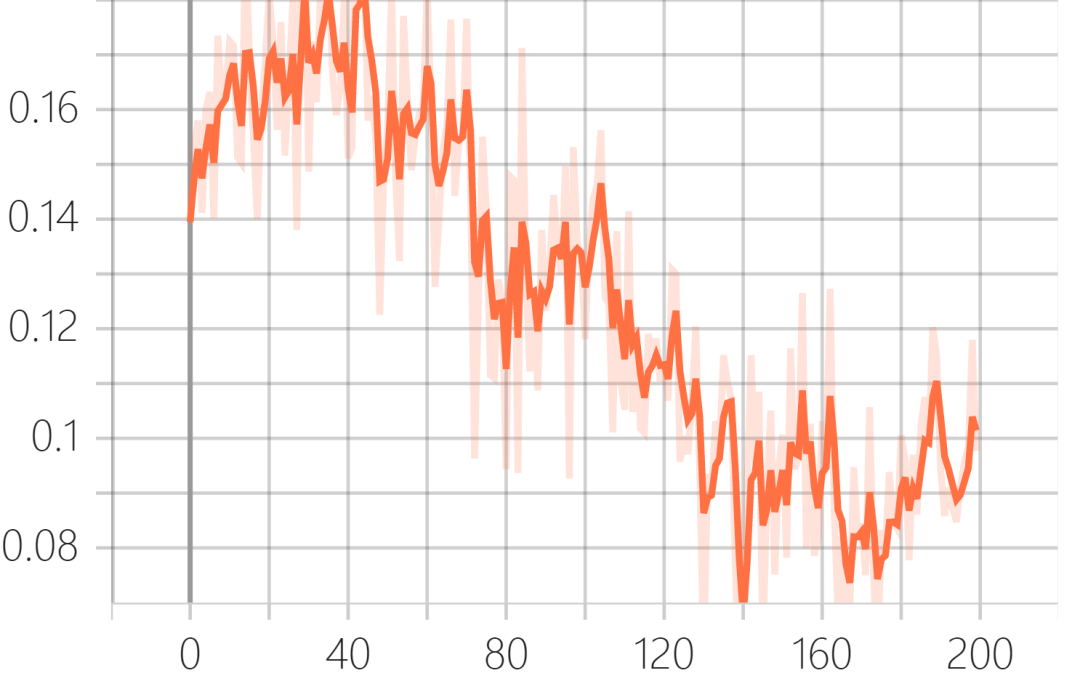
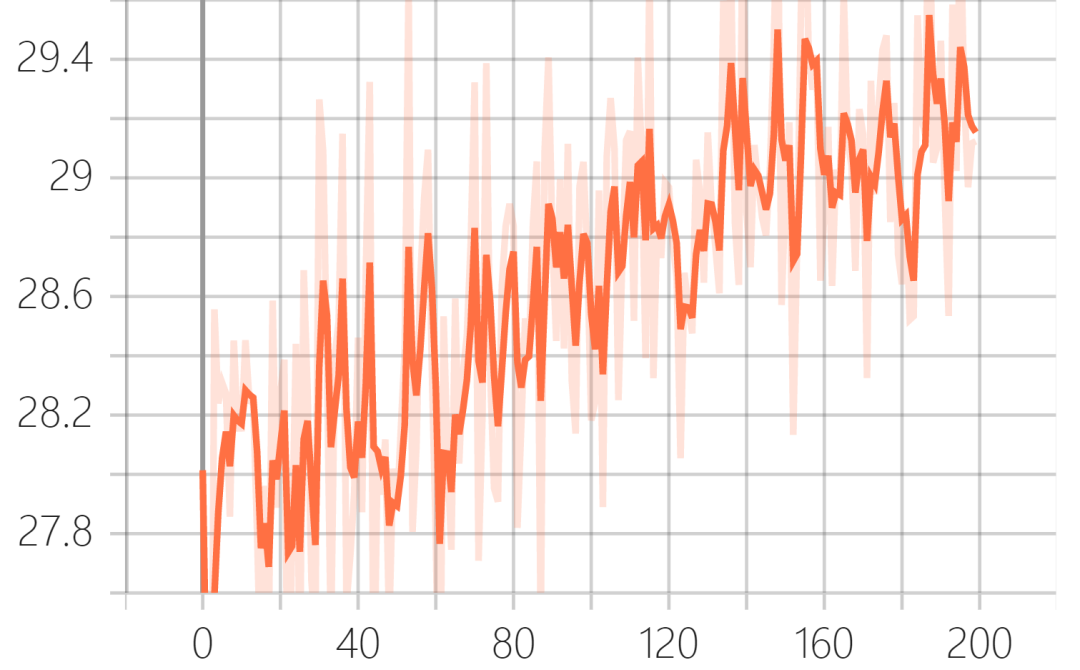
训练结果可以在tensorboard中可视化出来:
验证集ssim(结构相似性):
验证集GLoss:
验证集PSNR(峰值信噪比):
测试(CPU、GPU均可)
GPU
将测试图片以test.png保存到DeblurGANv2-master文件夹下,在CMD中输入:
python predict.py test.png
运行成功后结果submit文件夹中,predict.py中的模型文件默认为best_fpn.h5,大家也可以在DeblurGANv2的github中下载作者训练好的模型文件,保存在项目文件夹后将predict.py文件中的第93行改为想要用的模型文件即可,如将'best_fpn.h5'改为'fpn_inception.h5',但是需要将config.yaml中model对应的g_name改为相应模型,如想使用'fpn_mobilenet.h5',就将'fpn_inception'改为'fpn_mobilenet'
CPU
将predict.py文件中第21行、22和65行改为下面代码即可
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))['model'])
self.model = model
inputs = [img]
运行后就可以得到下面效果:


DeblurGAN的应用:优化YOLOv5性能


由上图可以看出,图片去模糊不仅可以提高YOLOv5的检测置信度,还可以使检测更准确。以Mobilenetv2为backbone的DeblurGANv2能达到图片实时去模糊的要求,进而可以使用到视频质量增强等方向。
线上训练
如果我们不想把数据集下载到本地的话可以考虑格物钛(Graviti)的线上训练功能,在原项目的基础上改几行代码即可。
首先我们打开项目文件夹中的dataset.py文件,在第一行导入tensorbay和PIL(如果没有安装tensorbay需要先pip install):
from tensorbay import GAS
from tensorbay.dataset import Dataset as TensorBayDataset
from PIL import Image
我们主要修改的是PairedDatasetOnline类还有_read_img函数,为了保留原来的类,我们新建一个类,将下面代码复制粘贴到dataset.py文件中即可(记得将ACCESS_KEY改为自己空间的 Graviti AccessKey):
class PairedDatasetOnline(Dataset):
def __init__(self,
files_a: Tuple[str],
files_b: Tuple[str],
transform_fn: Callable,
normalize_fn: Callable,
corrupt_fn: Optional[Callable] = None,
preload: bool = True,
preload_size: Optional[int] = 0,
verbose=True):
assert len(files_a) == len(files_b)
self.preload = preload
self.data_a = files_a
self.data_b = files_b
self.verbose = verbose
self.corrupt_fn = corrupt_fn
self.transform_fn = transform_fn
self.normalize_fn = normalize_fn
logger.info(f'Dataset has been created with {len(self.data_a)} samples')
if preload:
preload_fn = partial(self._bulk_preload, preload_size=preload_size)
if files_a == files_b:
self.data_a = self.data_b = preload_fn(self.data_a)
else:
self.data_a, self.data_b = map(preload_fn, (self.data_a, self.data_b))
self.preload = True
def _bulk_preload(self, data: Iterable[str], preload_size: int):
jobs = [delayed(self._preload)(x, preload_size=preload_size) for x in data]
jobs = tqdm(jobs, desc='preloading images', disable=not self.verbose)
return Parallel(n_jobs=cpu_count(), backend='threading')(jobs)
@staticmethod
def _preload(x: str, preload_size: int):
img = _read_img(x)
if preload_size:
h, w, *_ = img.shape
h_scale = preload_size / h
w_scale = preload_size / w
scale = max(h_scale, w_scale)
img = cv2.resize(img, fx=scale, fy=scale, dsize=None)
assert min(img.shape[:2]) >= preload_size, f'weird img shape: {img.shape}'
return img
def _preprocess(self, img, res):
def transpose(x):
return np.transpose(x, (2, 0, 1))
return map(transpose, self.normalize_fn(img, res))
def __len__(self):
return len(self.data_a)
def __getitem__(self, idx):
a, b = self.data_a[idx], self.data_b[idx]
if not self.preload:
a, b = map(_read_img, (a, b))
a, b = self.transform_fn(a, b)
if self.corrupt_fn is not None:
a = self.corrupt_fn(a)
a, b = self._preprocess(a, b)
return {'a': a, 'b': b}
@staticmethod
def from_config(config):
config = deepcopy(config)
# files_a, files_b = map(lambda x: sorted(glob(config[x], recursive=True)), ('files_a', 'files_b'))
segment_name = 'train' if 'train' in config['files_a'] else 'val'
ACCESS_KEY = "yours"
gas = GAS(ACCESS_KEY)
dataset = TensorBayDataset("BlurredSharp", gas)
segment = dataset[segment_name]
files_a = [i for i in segment if 'blurred' == i.path.split('/')[2]]
files_b = [i for i in segment if 'sharp' == i.path.split('/')[2]]
transform_fn = aug.get_transforms(size=config['size'], scope=config['scope'], crop=config['crop'])
normalize_fn = aug.get_normalize()
corrupt_fn = aug.get_corrupt_function(config['corrupt'])
# ToDo: add more hash functions
verbose = config.get('verbose', True)
return PairedDatasetOnline(files_a=files_a,
files_b=files_b,
preload=config['preload'],
preload_size=config['preload_size'],
corrupt_fn=corrupt_fn,
normalize_fn=normalize_fn,
transform_fn=transform_fn,
verbose=verbose)
再将_read_img改为:
def _read_img(x):
with x.open() as fp:
img = cv2.cvtColor(np.asarray(Image.open(fp)), cv2.COLOR_RGB2BGR)
if img is None:
logger.warning(f'Can not read image {x} with OpenCV, switching to scikit-image')
img = imread(x)[:, :, ::-1]
return img
最后一步将train.py第184行的datasets = map(PairedDataset.from_config, datasets)改为datasets = map(PairedDatasetOnline.from_config, datasets)即可。
往期精彩回顾 本站qq群554839127,加入微信群请扫码: