
谷歌提出最新时序框架--Deep Transformer
Deep Transformer Models for TSF

Transformer技术在诸多问题,例如翻译,文本分类,搜索推荐问题中都取得了巨大的成功,那么能否用于时间序列相关的数据呢?答案是肯定的,而且效果非常棒。本篇文章我们就基于Transformer的方法动态地学习时间序列数据的复杂模式,并且在时间序列相关的问题上取得了目前最好的效果。
问题定义
假设时间序列有个每周的数据点:
对于一个步的预测,监督的ML模型的输入就是
我们输出的就是:
每个输出点可以是一个标量或者是一个包含了大量特征的向量。
模型框架
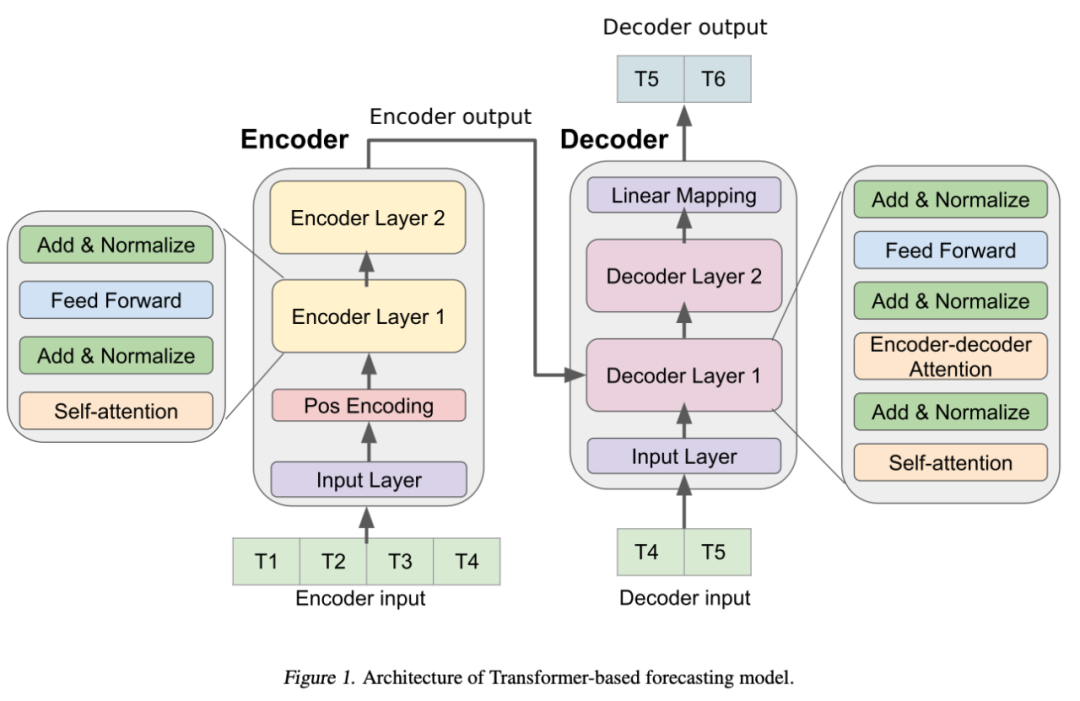
1. Encoder
Encoder由输入层、位置编码层和四个相同编码器层的堆栈组成。
输入层通过一个完全连接的网络将输入的时间序列数据映射到一个维度为的向量。这一步对于模型采用多头注意机制至关重要。
使用sin和cos函数的位置编码,通过将输入向量与位置编码向量按元素相加,对时间序列数据中的顺序信息进行编码。
最终的向量被输入到四个encoder层。每个encoder层由两个子层组成:一个self-attention的子层和一个全连接的前馈子层。每个子层后面都有一个normalization层。编码器生成一个维向量,往后传入decoder层。
2. decoder层
此处Transformer的Decoder设计架构和最早的Transformer是类似的。Decoder包括输入层、四个相同的解码器层和一个输出层。Decoder输入从编码器输入的最后一个数据点开始。输入层将解码器输入映射到维向量。除了每个编码器层中的两个子层之外,解码器插入第三个子层以在编码器输出上应用自注意机制。
最后,还有一个输出层,它将最后一个Decoder层的输出映射到目标时间序列。
我们在解码器中使用前look-ahead masking和在输入和目标输出之间的one-position的偏移,以确保时间序列数据点的预测将仅依赖于先前的数据点。
效果比较
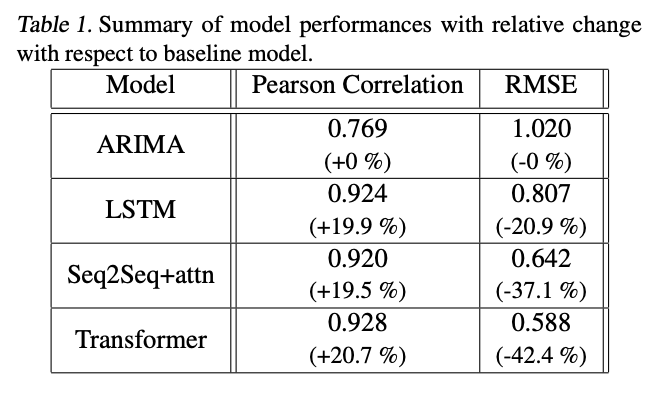
Transformer架构的效果远好于其他的效果
Time Delay Embedding实验
对于一个标量的序列数据,它的delay embedding(TDE)就是将每个scalar值映射到一个唯独的time-delay的空间,
我们发现并非是越大越好,在5-7之间是最好的。
本文提出的基于Transformer的时间序列数据预测方法。与其他序列对齐的深度学习方法相比,
Transformer的方法利用self-attention对序列数据进行建模,可以从时间序列数据中学习不同长度的复杂依赖关系。 基于Transformer的方案具有非常好的可扩展性,适用于单变量和多变量时间序列数据的建模,只需对模型实现进行最小的修改。
https://arxiv.org/pdf/2001.08317.pdf