
让检测告别遮挡 | NMS-Loss是如何解决目标检测中的遮挡问题的?

极市导读
本文发现了NMS造成的训练目标和评估指标之间的弱连接问题,并提出了一种新的损失函数NMS-loss,使NMS过程可以端到端地被训练而不需要任何附加的网络参数。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

1简介
非极大值抑制(Non-Maximum Suppression, NMS)在目标检测中至关重要,它通过合并假阳性(FP)和假阴性(FN)影响目标检测结果,尤其是在人群遮挡场景中。在本文中提出了NMS造成的训练目标和评估指标之间的弱连接问题,并提出了一种新的损失函数NMS-loss,使NMS过程可以端到端地被训练而不需要任何附加的网络参数。NMS-loss惩罚2种情况,即FP没有被抑制,而FN被NMS错误地删除。具体来说,NMS-Loss提出了pull loss将具有相同目标的预测拉得很近,以及push loss将具有不同目标的预测推得很远。

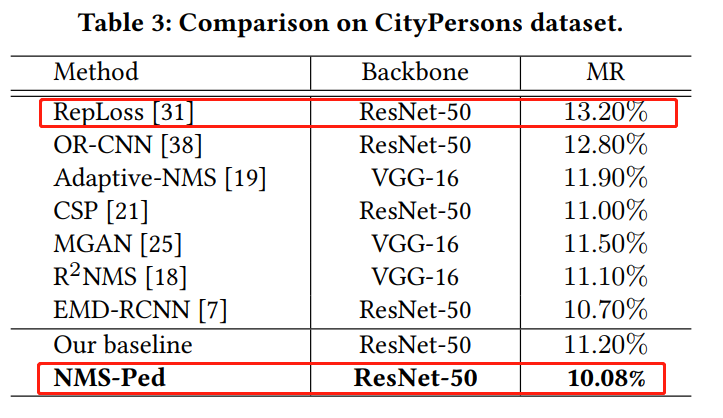
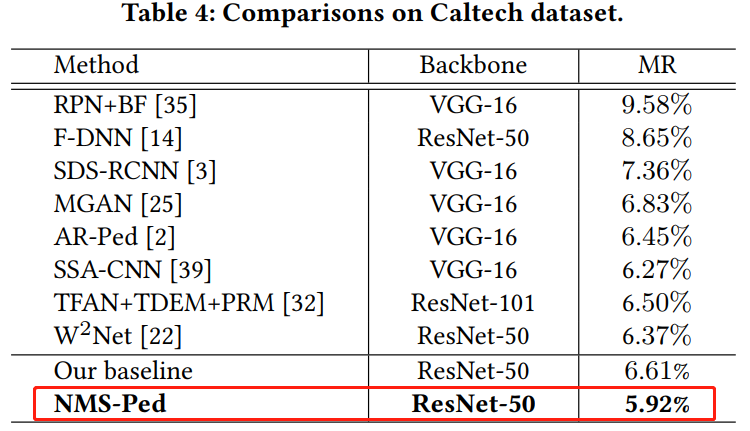
实验结果表明,在NMS-Loss的帮助下NMS-Ped检测器在Caltech数据集上的Miss Rate为5.92%,在CityPersons数据集上的Miss Rate为10.08%,均优于现有的同类检测器。
本文主要贡献
首先提出了行人检测中训练目标与评估指标之间的弱连接问题,并提出了一种新的NMS-loss,使NMS过程在不引入任何参数和运行时间开销的情况下可以端到端进行训练。 作者提出了精心设计的pull loss和push loss,分别考虑预测坐标和置信度,帮助网络提高精度和召回性能。 在行人检测中,作者借助NMS-Loss提出的NMS-Ped在Caltech和CityPersons数据集上优于现有的SOTA方法。
2NMS-LOSS
传统的NMS流程如Alg.1中所示,没有考虑红色字体。

NMS从一组得分为S的检测框开始,首先,将得分最大的proposal 从集合移动到最终保留检测的集合;然后,删除中得分为的且与的重叠高于阈值的框。对剩下的集重复此过程。但是,现有的方法没有将NMS纳入训练过程中来调整检测框,使得学习目标与评价指标不一致,这意味着NMS未抑制FP和NMS消除FN分别会损害精度和召回率。为了避免不一致,作者提出NMS-loss将NMS程序引入到训练过程中,自适应地选择由NMS引起的错误预测,并使用精心设计的pull和push两种损失来最小化FP和FN。具体来说NMS-Loss定义为:

其中为pull损失用来惩罚FP同时不抑制由NMS,为push损失用来惩罚NMS的FN错误删除。系数和是平衡损失的权重。NMS-Loss的细节在Alg.1中用红色文本强调。与传统pipeline不同,这里使用一组,包含相应的检测框ground truth index,用于识别FP和FN。在NMS-Loss计算过程中,M是一个辅助字典,以ground truth指数为key,对应最大检测得分为value,用来记录每个ground truth的max score预测。NMS-loss自然地合并到NMS过程中,而不包含任何额外的训练参数。对于测试来说,NMS-Loss的运行时成本为零。
2.1 定义Pull Loss
以降低FP为目标需要找出错误的预测。为此,在每次迭代中检查当前的max score预测是否为其对应的 ground truth的max score预测。如果不是,则说明是一个未被NMS抑制的FP,pull loss应在和 ground truth的max score prediction 之间执行(见图1)。形式上pull loss计算如下:
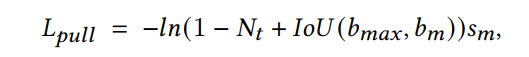
其中为预定义的NMS阈值,为对应于的预测score。作者注意到pull loss的2个特性:
当和之间的IoU较小时,pull loss有增加的趋势,迫使网络学会将拉向。NMS的阈值用于防止异常值的梯度对模型学习的影响过大。另外,对于NMS只需要使FP和TP之间的IoU高于即可。在pull loss中使用来减小异常值的梯度,可以使网络易于学习和收敛。 FP预测得分对pull loss也有较大影响。FP得分越高,对评价结果的影响越大,直观上需要更多的关注。此外,它使网络学习修正FP不仅要制约box坐标,而且要考虑降低预测分数。
2.2 定义Push Loss
在NMS中,当前的最大score预测用消除了获得高于的IoU的box。如果剔除的框对应的ground truth index 与不同,则为FN,降低召回率(见图1)。为了避免错误地删除提出push loss来惩罚FN:
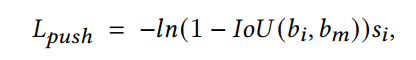
其中为对应的预测得分。与pull loss不同当时,push loss增大,模型学会将推离。为了避免模型倾向于通过降低FN的分数来减少push loss,作者只使用来重新加权损失,而不使用反向传播梯度。对于拥挤的场景,特别是在CityPersons数据集中,边界框的ground truths是相互重叠的。在IoU=0的情况下,将他们的预测相互排斥是不合理的。为了处理这个问题,作者只在预测IoU高于其对应ground truth box的IoU时才计算。本文所提的Pull Loss和Push Loss是根据预测来执行的。当pull/push loss被激活时,网络会尝试pull/push两个预测,分别pull/push彼此。因为高分预测通常会得到一个更准确的位置,所以在一个不准确的预测基础上移动一个准确的预测是不合理的。为了解决这个问题,作者停止了高分预测的梯度向后传播,导致网络专注于错误的预测。
2.3 与RepLoss的不同之处在哪里?

RepLoss通过设置损失函数的方式,使预测框和所负责的真实目标框的距离缩小,而使得其与周围非负责目标框(包含真实目标框和预测框)的距离加大 。如下式,如果与周围目标的距离越大,损失值会越小。

作者对NMS-Loss和RepLoss进行了详细的比较,因为这2种方法都是基于它们的目标进行pull/push预测的。主要有3个区别:
RepLoss在所有实例上执行,而NMS-Loss只在被NMS错误处理的实例上执行,从而实现了端到端训练。 RepLoss只考虑回归,而score在NMS-Loss中也用于实例重加权。 在密集人群场景下RepLoss将实例推开,即使它们的目标本来很接近,使RepLoss与回归损失相矛盾。相反,NMS-Loss会推送与其他IoU高于其对应ground truth box IoU的实例,这样可以消除RepLoss的矛盾。
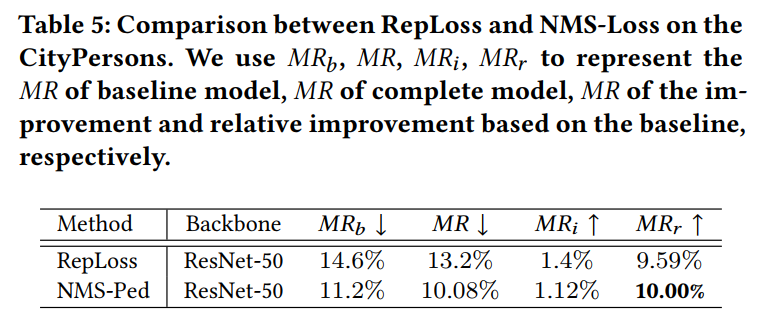
如表所示,NMS-Loss不仅比RepLoss表现更好,而且在CityPersons上有更高的相对改善。这表明,NMS-Loss可以在广泛使用的数据集上实现稳定的相对改进(高于10%)。
3实验


参考
[1].NMS-Loss: Learning with Non-Maximum Suppression for Crowded Pedestrian Detection
[2].Repulsion Loss: Detecting Pedestrians in a Crowd
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
