
ECCV 2020 微软亚洲研究院6篇精选论文集锦

极市导读
ECCV(European Conference on Computer Vision)是计算机视觉领域的三大顶会之一。今年的 ECCV 大会于8月23日至28日在线上举行。微软亚洲研究院在本届大会上有21篇论文入选,本文精选了其中6篇有代表性的为大家进行介绍。
A Closer Look at Local Aggregation Operators in Point Cloud Analysis
论文链接:https://arxiv.org/abs/2007.01294
代码地址:https://github.com/zeliu98/CloserLook3D
近些年涌现了很多不同的 3D 点云网络和算子,例如自 PointNet++、DGCN、Continuous Conv、DeepGCN、KPConv 等等,尽管它们在常见的基准评测集上的性能逐步有所提升,但由于各种网络采用不同的局部算子、整体网络结构和实现细节,所以人们对该领域的实质进步一直缺乏准确地评估。
为此,微软亚洲研究院和中国科大的研究人员尝试对该领域的进步进行更准确、公平地评估,并提出了无需可学参数的新型 3D 点云算子位置池化 PosPool。研究指出:
1)尽管不同 3D 算子的设计各异,但在相同整体网络和实现细节下,所有算子的性能都惊人的相似。
2)无需更复杂的 3D 网络,经典的深度残差网络就能在各种规模和各种场景的数据集上取得优异的表现。结合几种典型局部算子后,均能在 PartNet 上超过此前 SOTA 7个点以上。
3)极简无参的位置池化算子 PosPool (位置池化)即能比肩各种更复杂的 3D 局部算子。
该论文的方法没有引入复杂的设计,希望这一基准方法可以让今后 3D 点云识别的研究可以从中受益。
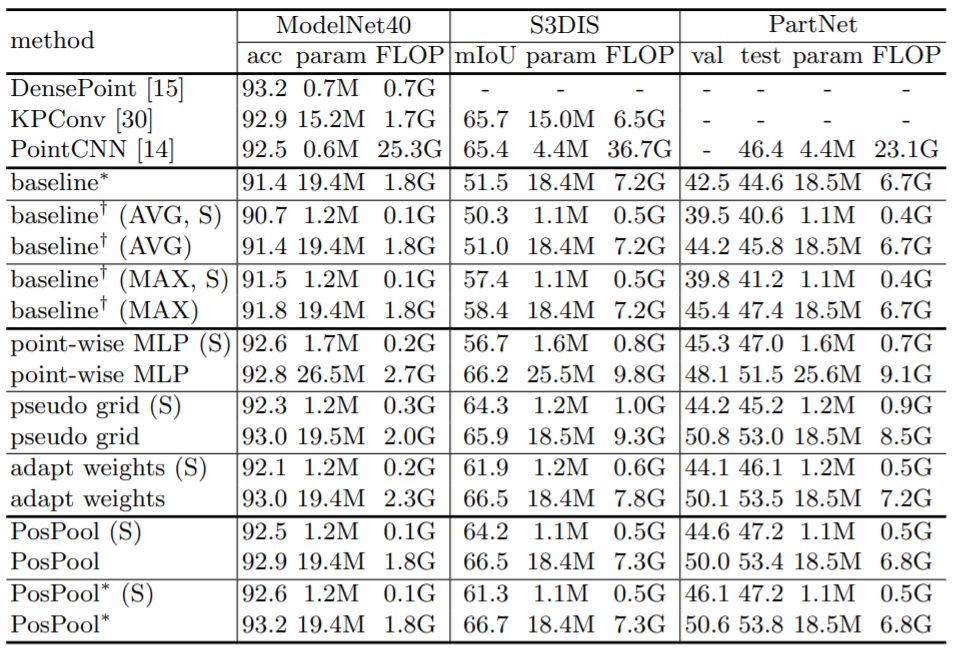
表1:不同 3D 局部算子在标准数据集中的表现(其中 S 表示小一些的模型,PosPool * 表示一种变体)
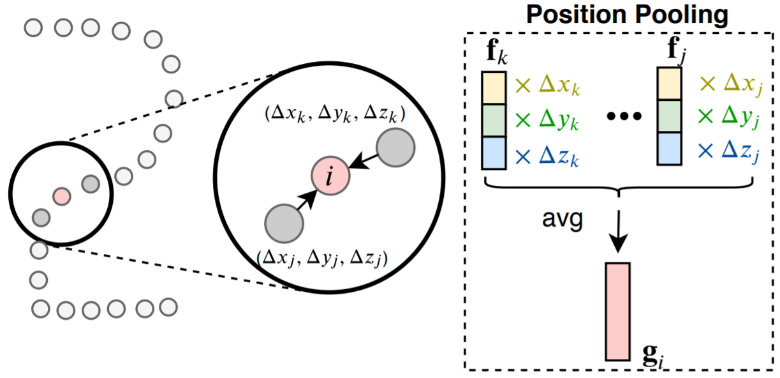
图1:位置池化(PosPool)算子示意
多摄像机多人三维人体姿态估计 VoxelPose
VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild
论文链接:https://arxiv.org/abs/2004.06239v1.pdf
代码地址:https://github.com/microsoft/voxelpose-pytorch
微软亚洲研究院的研究员在本篇论文中提出了一种新的多摄像机多人姿态估计的方法 VoxelPose。该任务存在两个重要挑战:
(1)将每个视角中的关键点聚类成多个实例,
(2)将不同视角中同一个人的关键点进行关联。
在之前的工作中,以上两个问题通常会由两个独立的模型来完成,然而在图像背景复杂、遮挡严重的情况下,因为缺少足够的信息,让这个任务变得非常困难,从而使得结果不尽如人意。在该论文中,研究员们基于 voxel 表达方式,提出了一种方法可以直接在三维空间进行推理,无需在二维图像上进行任何硬决策。
简单来说,就是从多个摄像机的图像中构建基于 voxel 的对场景(包括人)的表达,然后提出一个检测网络用来检测人在三维空间中的大概位置,最后利用姿态估计网络在每一个检测出来的位置附近检测精细的三维人体姿态。研究员们在 Campus 和 Shelf 数据集上都大幅提升了当前最好方法的结果。重要的是,在存在非常多遮挡的场景下,该方法依然能够稳定地估计出所有人的姿态。
这是首个基于计算机视觉方案在复杂场景里进行准确的姿态估计和跟踪的方法。该方法的优化版本已被应用到微软的 Connected Store 项目中,用来估计零售商店场景下的多人姿态。
以下是 VoxelPose 在多个公开数据集上的结果展示。
在 Panoptic 数据集上的结果
在 Campus 数据集上的结果。研究员并没有在这个数据集上进行训练,而是直接使用了在 Panoptic 数据集上训练好的模型。
在 Shelf 数据集上的结果。同样,研究员没有在这个数据集上进行训练,直接使用了在 Panoptic 数据集上训练好的模型。
生成图片质量评估 GIQA
GIQA: Generated Image Quality Assessment
论文链接:https://arxiv.org/abs/2003.08932.pdf
代码地址:https://github.com/cientgu/GIQA
这些年来,深度生成模型取得了巨大的进展,然而并非所有生成的结果都十分完美。微软亚洲研究院提出了一个新的研究领域:生成图片质量评估 (GIQA),并从两个角度提出了三种 GIQA 的方法,对单张生成图片的质量进行打分,并筛选出符合需求的图片。

图2:GIQA 对生成图片的打分分布
首先是基于学习的 GIQA:研究员们发现在训练 GAN 的时候,生成图片的质量会随着迭代次数的增加越来越好。所以,一个直接的想法就是用迭代次数当质量的“伪标签”,通过监督式的学习来学一个打分器,从而对生成图片的质量进行打分。该方法被称之为 MBC-GIQA。
另一种思路是基于数据驱动的 GIQA:其核心思想是用一张生成图片来自于真实分布的概率去衡量图片的质量,概率越大,质量越高。然而这需要对真实分布进行建模,因此,基于所建模型的不同,研究员们提出了两种方法 GMM-GIQA 和 KNN-GIQA。
研究员们收集了 LGIQA 质量评估数据集,并衡量了此次提出的方法,发现 GMM-GIQA 能取得最好的结果,远远超过传统的图像质量评估方法。所以,GMM-GIQA 是目前最推荐使用的方法。

图3:微软亚洲研究院的方法和之前的方法挑出的最高质量和最低质量的图片
微软亚洲研究院的新方法还有很多衍生应用。其中一个是模型质量评估。对于生成模型,可以独立的衡量生成图片的质量和多样性。另一个有趣的应用是通过后处理丢弃一部分图片,让剩下的图片有更好的生成质量。此外,研究员们还通过结合 OHEM,在 GAN 的训练过程中,给低质量生成图片更高的惩罚权重,从而让 GAN 生成出更高质量的图片。
整体来看,GIQA 是一个新颖且对学术界和产业界都很有意义的研究方向,经验证,新提出的几种 GIQA 方法,都具有相当高的有效性和应用价值。
基于物理与神经网络的光照估计
Object-based Illumination Estimation with Rendering-aware Neural Networks
论文链接: https://arxiv.org/abs/2008.02514v1.pdf
混合现实(Mixed Reality)技术允许用户将虚拟物体与真实世界相融合,得以实现类似在现实世界中观察虚拟物体的效果。然而,如何将虚拟物体按照真实的环境进行绘制依然是一个具有挑战的问题。真实世界中的物体都是受到周围真实环境的光照照射的,如果绘制混合的虚拟物体无法保持一致的光照效果,用户则会感受到光照的不一致性,从而影响观感体验。因此,研究人员需要根据当前的,即将混合虚拟物体的真实世界照片,来估计当前真实环境中的光照条件。
传统的基于图像的光照估计算法往往从图像的全局考虑,并假设输入图像是背景环境光照的一部分,而在一些混合现实的应用中,用户的视角往往会集中于场景的一个局部。针对这样的输入数据,传统基于全局信息的光照估计算法很难给出稳定的光照预测。为了解决这一问题,微软亚洲研究院的研究员们提出了一种基于场景局部光影信息来进行光照估计的算法。仅仅给定一个场景的局部作为输入,但这个局部中物体本身的高光反射、阴影变化等都反映了当前环境光照的信息,可以有效的作为光照估计的线索。
然而,场景中物体的光影与环境光照的关系是一个比较复杂的过程,虽然可以利用基于物理的渲染方法来模拟这一过程,但由于这个关系的高度非线性性质使得从光影反向推导光照的问题难于进行优化。更重要的是,这一反向求解光照的过程同时会受到场景的几何形体,材质属性等性质的影响,因此,纯粹基于物理的反向优化方法往往难以准确得到精确、稳定的求解。
针对这一问题,微软亚洲研究院的研究员们将基于物理的光照计算与基于学习的神经网络训练相结合,同时利用基于物理计算对于光照与光影之间的已知关系,以及神经网络的可学习型和鲁棒性,得到了基于物理知识的光照估计神经网络。此外,研究员们还设计了一个循环卷积网络 (Recurrent-CNN) 通过利用输入视频的时间序列,提高光照估计在整个视频上的稳定性。
实验表明,本篇论文提出的光照估计方法可以有效地根据场景中局部物体上的光影效果来估计当前的环境光照。该方法适用于不同场景以及不同的物体材质属性,极大地提高了混合现实渲染的真实感和用户体验。

图4:输入图像

图5:嵌入虚拟物体的绘制效果,虚拟物体的光影根据估计出的环境光照计算得出
SRNet: 提升三维人体姿态估计的泛化能力
SRNet: Improving Generalization in 3D Human Pose Estimation
论文地址:https://arxiv.org/abs/2007.09389
许多基于深度学习的视觉识别任务,在实际应用中,都会因为遭受训练数据的“长尾分布”问题而使得性能下降。对于三维人体姿态估计任务来说也是如此,训练数据中很稀少甚至是从来没有见过的姿态,在测试时往往效果不佳,即模型不能很好地泛化。但有趣的是,“局部”的人体姿态,从统计上并没有遭受严重的长尾问题。比如,一个在测试时从来没有见过的姿态,它的每一个“局部”姿态可能都在训练数据里见过,如图6所示。
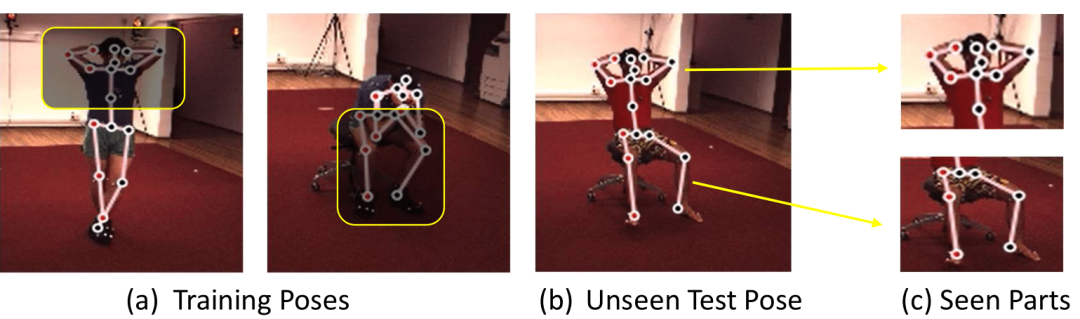
图6:一个没有见过的测试姿态 (b) 可以被分解成若干局部姿态 (c),而这些局部姿态在训练数据 (a) 中都见过。SRNet 方法利用了这个性质来提升对于稀少或者是没有见过的人体姿态的估计性能
基于这个观察,研究员们设计出了一个如图7 (c)(d) 所示的网络结构,命名为 SRNet。该方法首先把所有的人体关键点分解成若干个组,因为组内的各个关键点有着更强的相互关联,而组与组之间关键点的关联则相对较弱。每个组内的关键点会先经过一个独立的子网络以加强局部关系(特征)的计算。然后,通过从剩下其他组的关键点中计算出一个“低维的全局信息”,再加回到这个组,来表示组内的关键点和组外关键点的弱相关关系。通过控制这个“全局信息”的维度,组内的关键点学习既减弱了对组外的弱相关关键点的依赖,又没有丢失全局的一致性。由于减弱了对弱相关关键点的依赖,该模型能够更好地反映“局部”姿态的分布,从而可以更好地泛化到新的组合姿态中去。
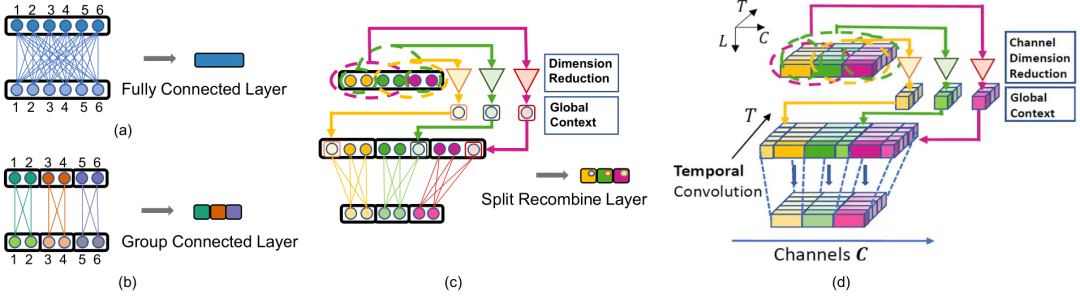
图7: (a) 全连接层;(b) 分组连接层;(c) SR (split-and-recombine) 连接层;(d) SR 卷积层
研究员们在 Human3.6M,MPI-INF-3DHP 等数据集上,通过详实的对比实验验证了 SRNet 的有效性。尤其是在跨数据集(提升19.3%),跨动作(提升12.2%)以及不常见姿态(提升39.7%)的测试上,SRNet 都带来了大幅的性能提升,超越了之前的方法。
TCGM: 基于信息论的多模态半监督学习框架
TCGM: An Information-Theoretic Framework for Semi-Supervised Multi-Modality Learning
论文地址:https://arxiv.org/abs/2007.06793v1.pdf
相比较单模态,利用多模态数据学习可以融合多个角度的信息,从而能够学到更加鲁邦的模型。如图8所示,临床医学上,人们可以利用 X 光片、看病记录等多个信息来进行疾病诊断。然而,在很多实际应用中 (比如医疗),获取标签成本较高,因此数据中会只有一部分样本具有标注信息,即所谓的半监督学习。微软亚洲研究院的研究员们在本篇论文中阐述了如何利用多模态信息,更有效率地学到性能较好的分类器。
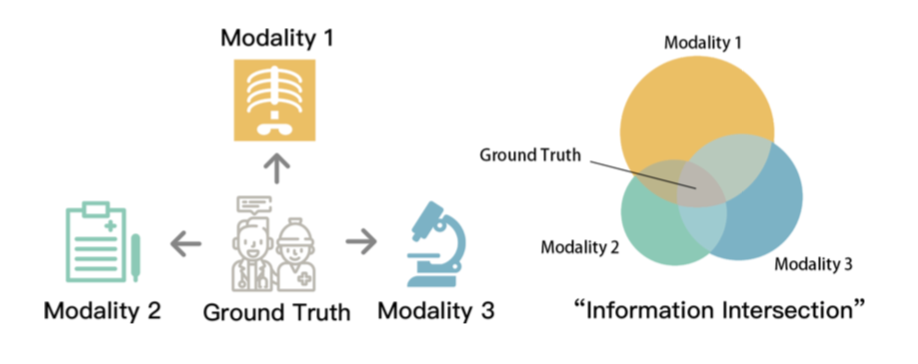
图8:左图-条件独立假设(医疗),右图-真实标签为所有模态的交叉信息
在多模态学习中,一个公认的假设是,标签 Y 是所有模态的“交叉信息”,去除掉标签后,所有模态信息独立,如图8(右图)所示。这一交叉信息可以被全相关这一指标所刻画。全相关用来描述多个变量间的公共信息,在模态数为2时,则退化为互信息。因此,假设数据有 M 个模态,那么可以选择在无标签样本上最大化 M 个模态的全相关的下界。这一下界可以表达为 M 个分类器的函数。理论证明,最大化这一下界可以学到贝叶斯分类器的排列变换。而在有标签的数据上,则最小化每个分类器的交叉熵,从而唯一地学到贝叶斯分类器。微软亚洲研究院的研究员们将该方法称为全相关收益最大化方法 (TCGM)。
研究员们用 D_u≔{x_i^([M]) }_i 表示无标签数据,D_l≔{(x_i^[M] ,y_i)}_i 表示有标签数据,其中 x_i^([M])≔{x_i^1,…,x_i^M } 和 y_i 分别表示第 i 个样本的 M 个模态的数据和标签,并且用 h_m 来表示第 m 个分类器,p_c 来表示第 c 类别的先验分布。
本篇论文提出的全相关收益最大化方法可以概括为在 D_l 上训练各个分类器,并在无标签数据 D_u 上最大化 M 个模态的全相关的下界。对于后者,根据 f-divergence 理论以及标签 Y 是交叉信息的假设,可以将全相关的对偶下界表示为 M 个分类器函数,这一函数的经验分布形式为:

该函数可以看成是两项相减,第一项表示对于同一个样本,M 个分类器输出一致的标签,并在第二项上约束这些分类器在不同样本上的表现不同,如图9所示。
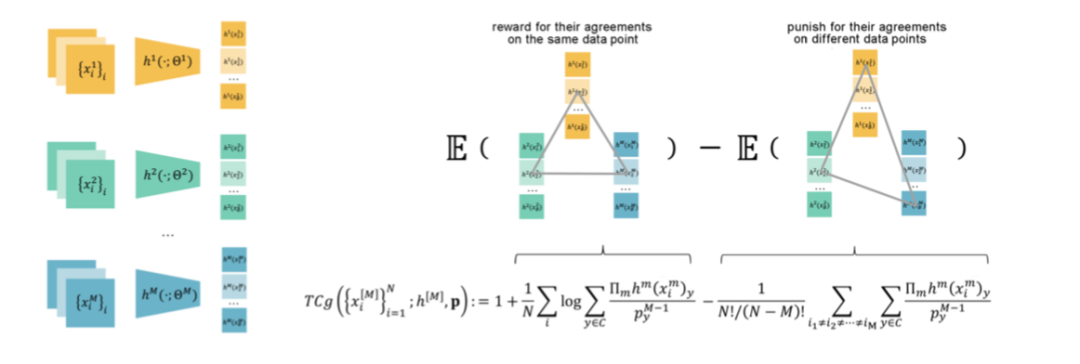
图9:全相关收益最大化框架
理论证明,通过最大化这一函数,学到的 {h_m }_m 为贝叶斯分类器的排列变换。进而,研究员们在有标签的数据上分别训练这 M 个分类器,从而可以唯一地学到贝叶斯分类器。
为了验证方法的有效性,研究员们在新闻分类,阿尔茨海默疾病以及情绪识别上做了实验(如图10、11、12)。在这些实验中,TCGM 方法都比已有方法取得了更好的效果,尤其是当标签比例较低时。
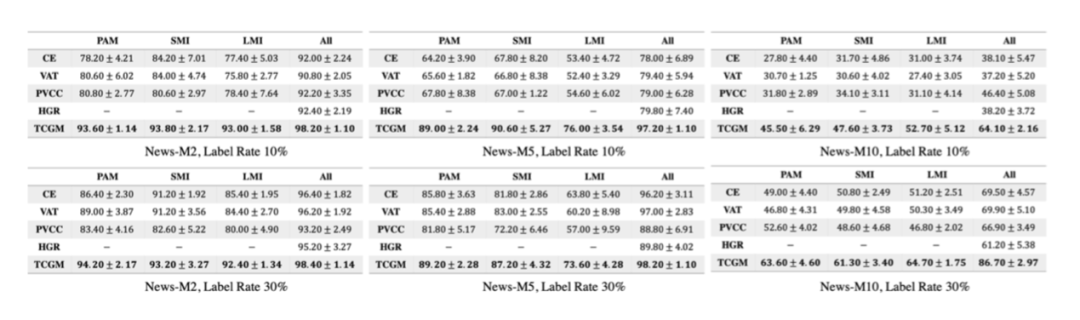
图10:新闻分类实验

图11:阿尔茨海默疾病预测

图12:情绪识别
推荐阅读
