
一文看尽神经网络中不同种类的卷积层

极市导读
本文介绍了卷积神经网络中的卷积核及其改进结果,并重点分析了它们的思路和作用。>>加入极市CV技术交流群,走在计算机视觉的最前沿
在计算机视觉中,卷积是最重要的概念之一。同时研究人员也提出了各种新的卷积或者卷积组合来进行改进,其中有的改进是针对速度、有的是为了加深模型、有的是为了对速度和准确率的trade-off。本文将简单梳理一下卷积神经网络中用到的各种卷积核以及改进版本,着重讲其思路以及作用。
目录
1. Convolution
2. 1x1/Pointwise Convolutions
3. Spatial and Cross-Channel Convolutions
4. Grouped Convolutions
5. Separable Convolutions
6. Flattened Convolutions
7. Shuffled Grouped Convolutions
8. Dilated Convolution(Atrous Convolution)
9. Deformable Convolution
10. Attention
11. Summary
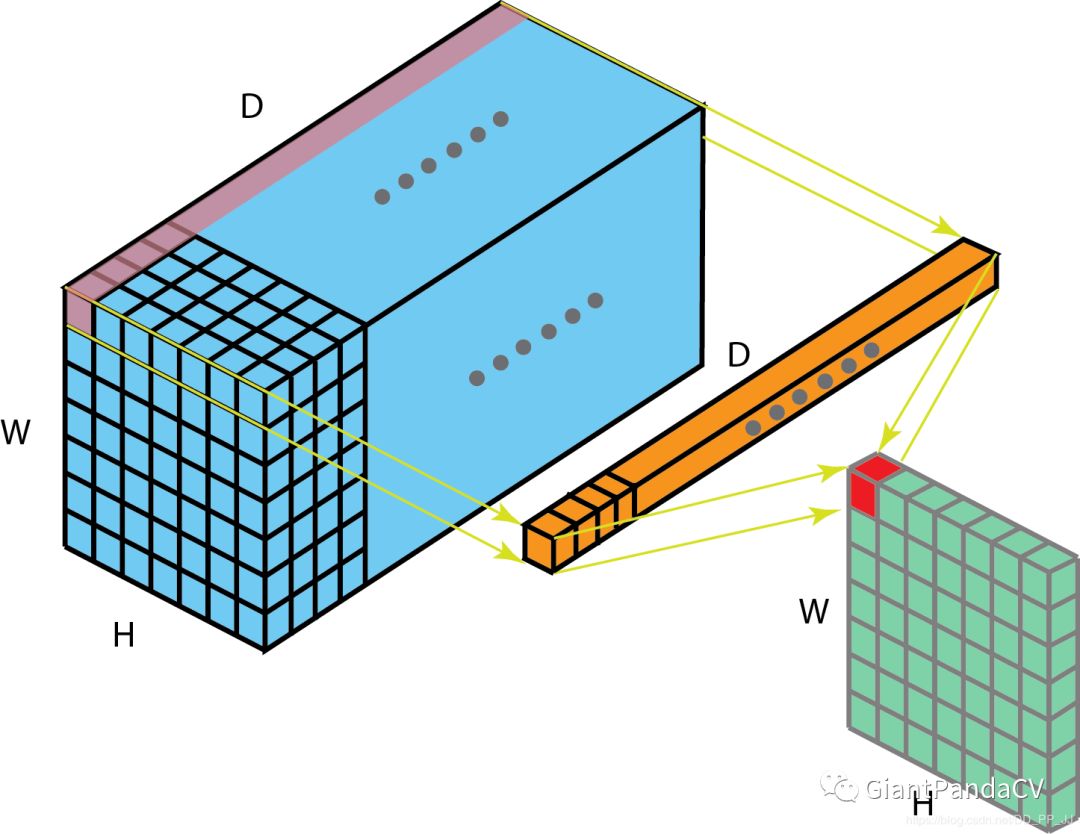
1. Convolution
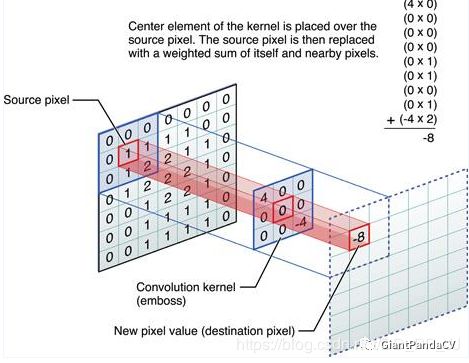
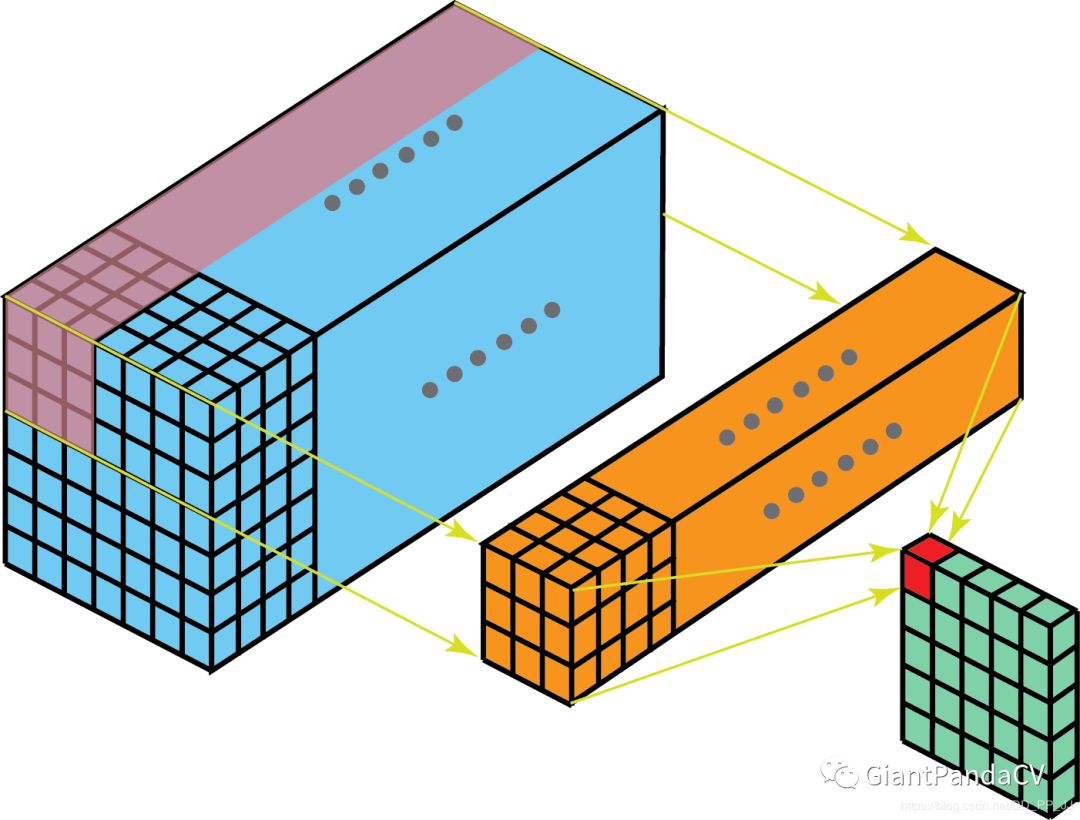
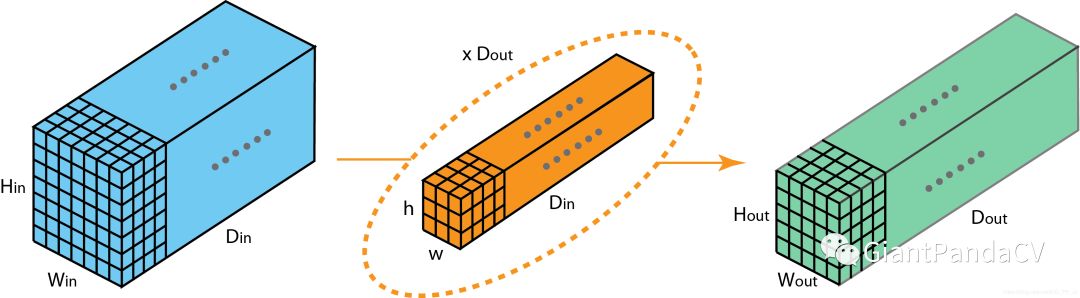
2. 1x1/Pointwise Convolutions
用于降维或者升维,可以灵活控制特征图filter个数 减少参数量,特征图filter少了,参数量也会减少。 实现跨通道的交互和信息整合。 在卷积之后增加了非线性特征(添加激活函数)。
3. Spatial and Cross-Channel Convolutions
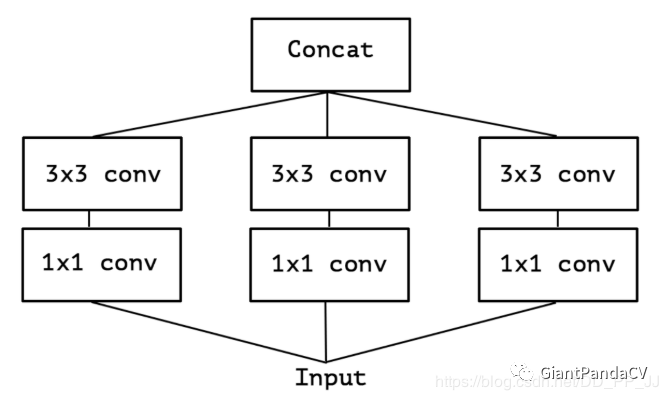
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features, conv_block=None):
super(InceptionA, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1x1 = conv_block(in_channels, 64, kernel_size=1)
self.branch5x5_1 = conv_block(in_channels, 48, kernel_size=1)
self.branch5x5_2 = conv_block(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, padding=1)
self.branch_pool = conv_block(in_channels, pool_features, kernel_size=1)
def _forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)
4. Grouped Convolutions
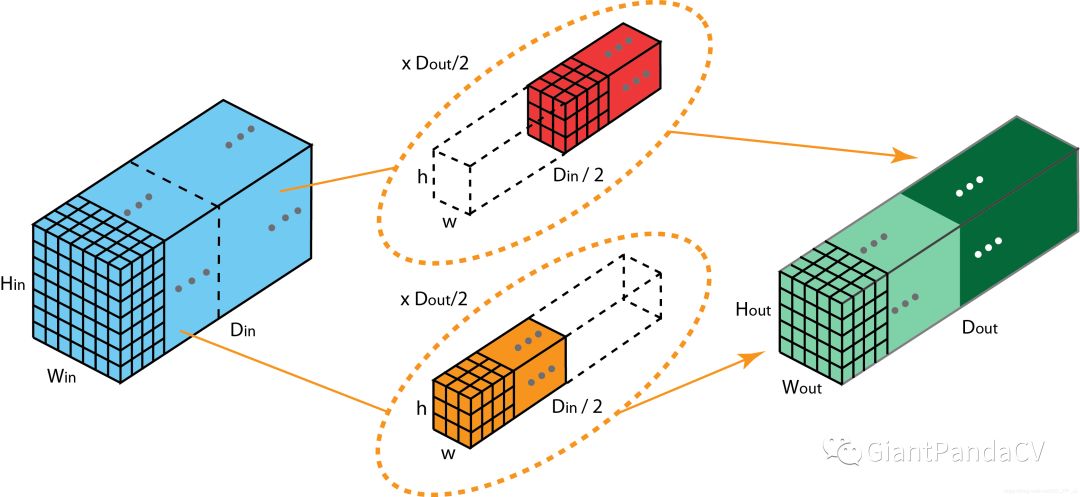
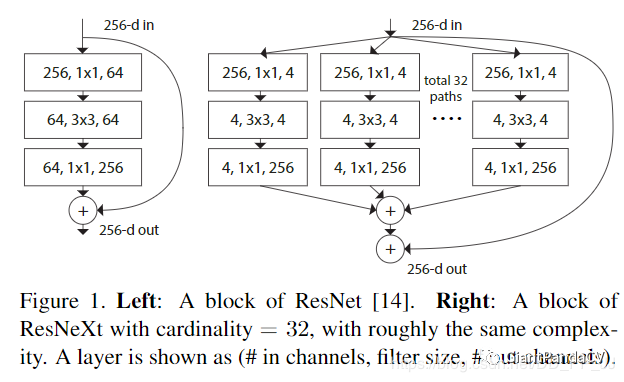
训练效率高。由于卷积被分为几个不同的组,每个组的计算就可以分配给不同的GPU核心来进行计算。这种结构的设计更符合GPU并行计算的要求,这也能解释为何ResNeXt在GPU上效率要高于Inception模块。
模型效率高。模型参数随着组数或者基数的增加而减少。
效果好。分组卷积可能能够比普通卷积组成的模型效果更优,这是因为滤波器之间的关系是稀疏的,而划分组以后对模型可以起到一定正则化的作用。从COCO数据集榜单就可以看出来,有很多是ResNeXt101作为backbone的模型在排行榜非常靠前的位置。
5. Separable Convolutions
空间也就是指:[height, width]这两维度组成的。 深度也就是指:channel这一维度。
5.1 Spatially Separable Convolutions
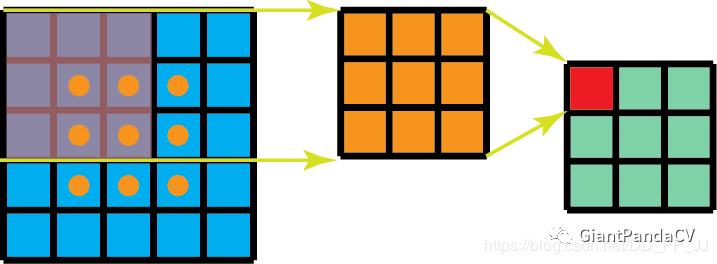
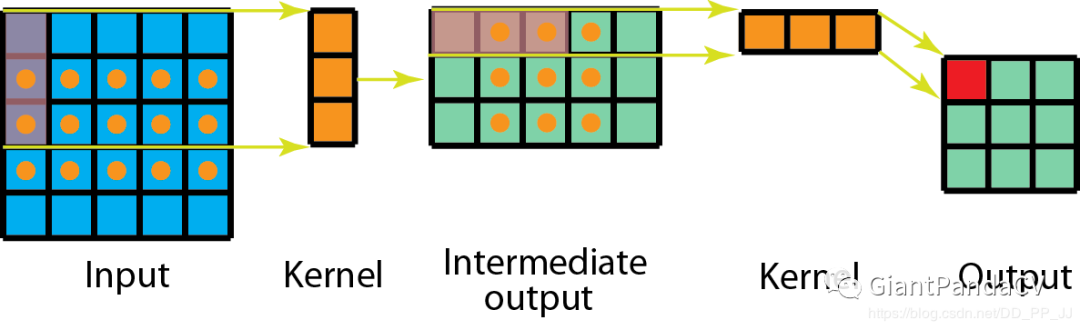
5.2 Depthwise Separable Convolutions
Depthwise Convolution: 独立地施加在每个通道的空间卷积 Pointwise Convolution: 1x1 convolution,通过深度卷积将通道输出投影到一个新的通道空间。
class DWConv(nn.Module):
def __init__(self, in_plane, out_plane):
super(DWConv, self).__init__()
self.depth_conv = nn.Conv2d(in_channels=in_plane,
out_channels=in_plane,
kernel_size=3,
stride=1,
padding=1,
groups=in_plane)
self.point_conv = nn.Conv2d(in_channels=in_plane,
out_channels=out_plane,
kernel_size=1,
stride=1,
padding=0,
groups=1)
def forward(self, x):
x = self.depth_conv(x)
x = self.point_conv(x)
return x
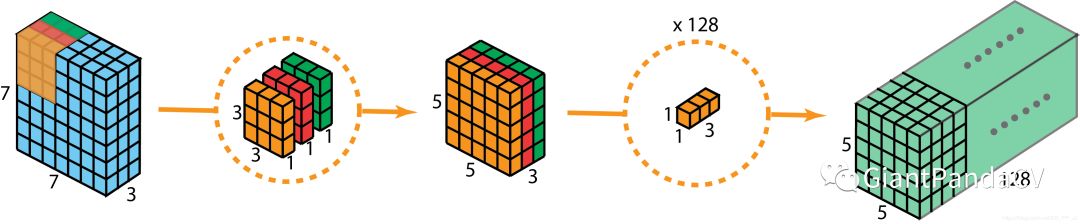
可分离卷积是先用Depthwise Convolution, 然后再使用1x1卷积;Inception中是先使用1x1 Convolution,然后再使用Depthwise Convolution。 深度可分离卷积实现的时候没有增加非线性特征(也就是使用激活函数)。
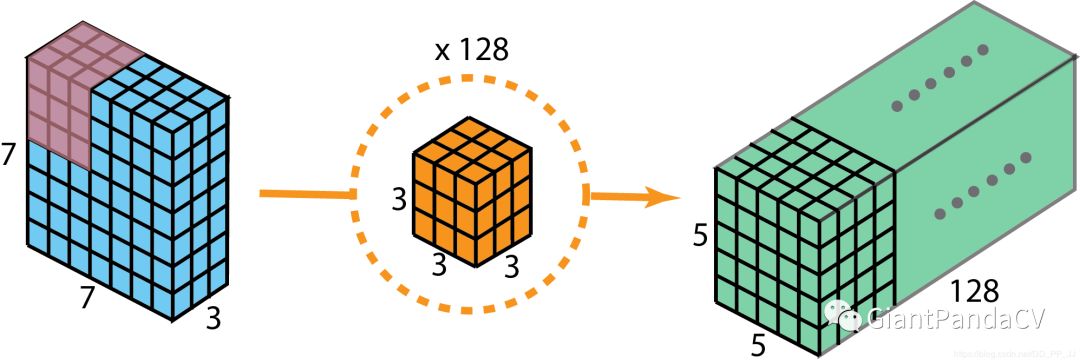
6. Flattened Convolutions

7. Shuffled Grouped Convolutions
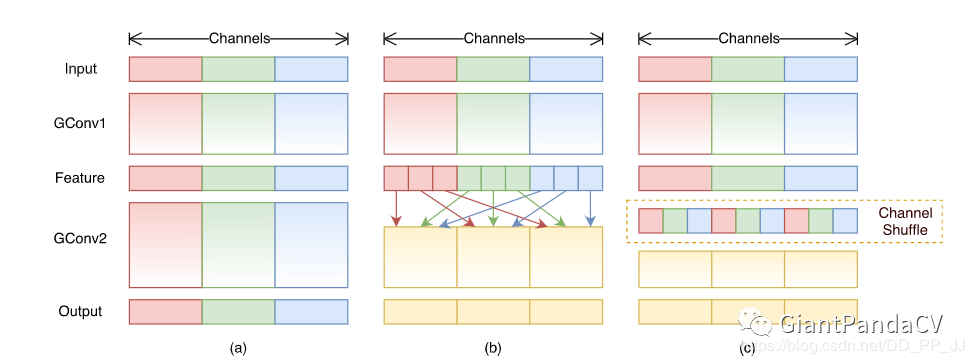
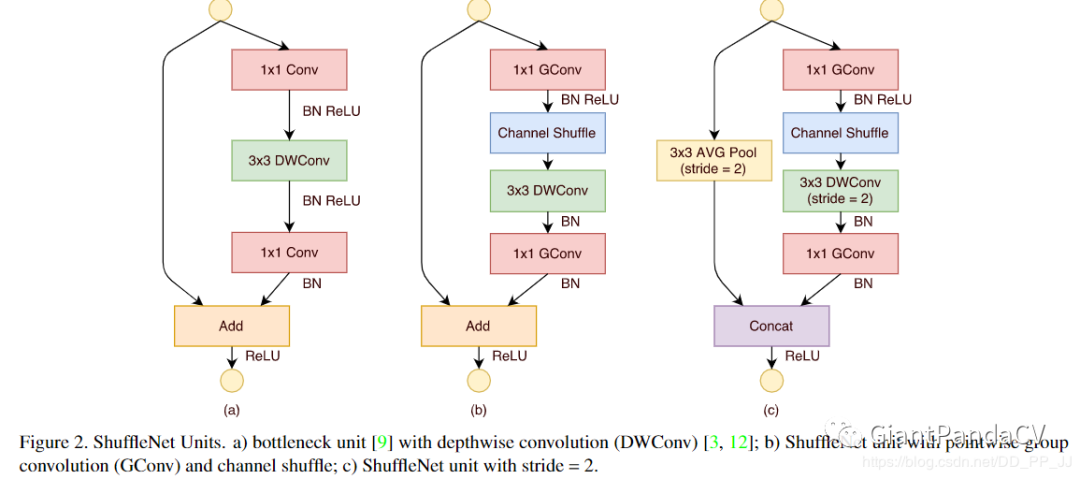
shuffled grouped convolution = grouped convolution + Channel Shuffle pointwise grouped convolution = 1x1 convolution + grouped convolution depthwise separable convolution
8. Dilated Convolution(Atrous Convolution)
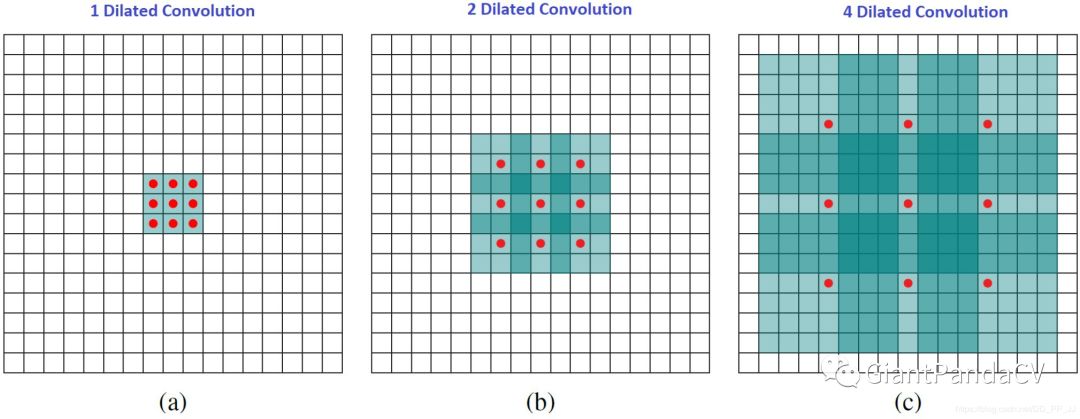
Gridding Effect:
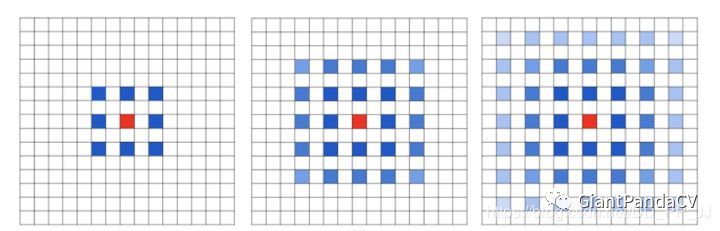
上下文信息多少
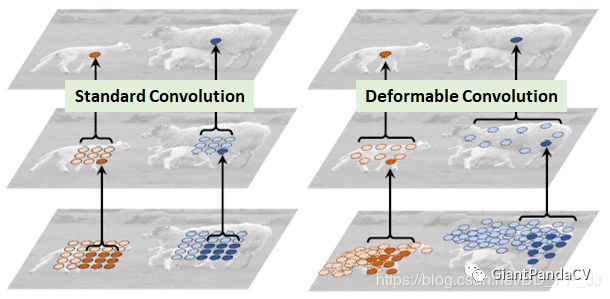
9. Deformable Convolution
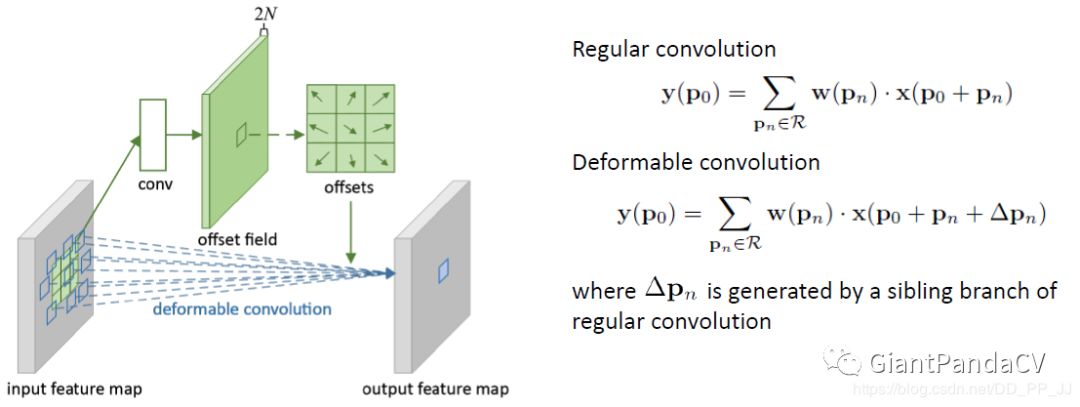
10. Attention
10.1 Squeeze and Excitation
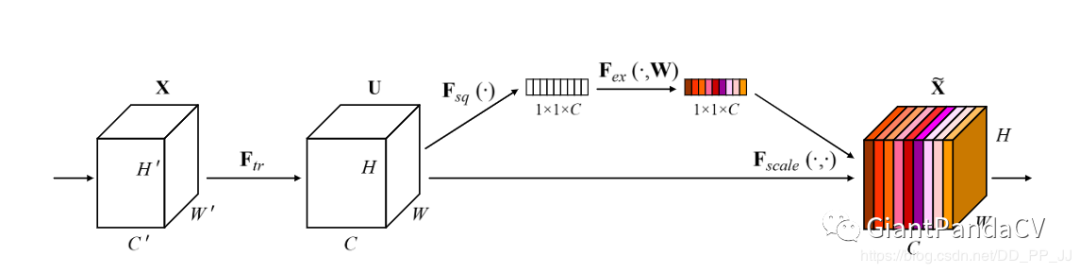
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
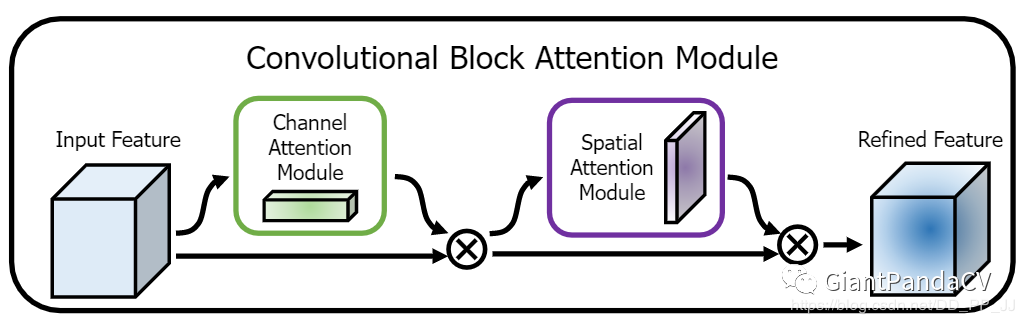
10.2 Convolutional Block Attention Module
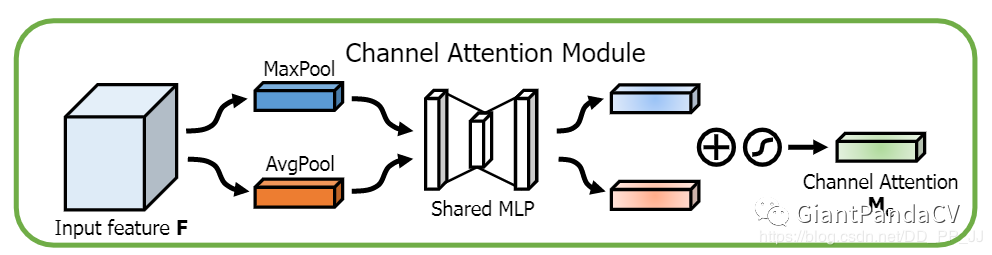
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
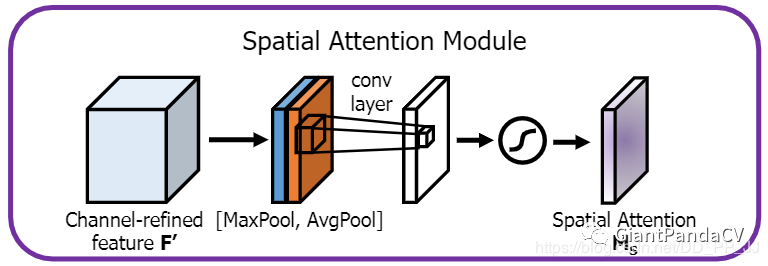
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)
11. Summary
通道和空间
Convolution 1x1 Convolution Spatial and Cross-Channel Convolutions 通道相关性(channel)
Depthwise Separable Convolutions Shuffled Grouped Convolutions Squeeze and Excitation Network Channel Attention Module in CBAM 空间相关性(HxW)
Spatially Separable Convolutions Flattened Convolutions Dilated Convolutions Deformable Convolution Spatial Attention Module in CBAM
单一尺寸卷积核用多个尺寸卷积核代替(参考Inception系列)
使用可变形卷积替代固定尺寸卷积(参考DCN)
大量加入1x1卷积或者pointwise grouped convolution来降低计算量(参考NIN、ShuffleNet)
通道加权处理(参考SENet)
用深度可分离卷积替换普通卷积(参考MobileNet)
使用分组卷积(参考ResNeXt)
分组卷积+channel shuffle(参考shuffleNet)
使用Residual连接(参考ResNet)
致谢:感谢Kunlun Bai,本文中使用了不少便于理解的图都是出自这位作者。
Reference
推荐阅读
