
卷积神经网络的复杂度分析
点击左上方蓝字关注我们

1. 时间复杂度
即模型的运算次数,可用 FLOPs衡量,也就是浮点运算次数(FLoating-point OPerations)。
1.1 单个卷积层的时间复杂度
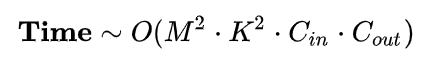
M: 每个卷积核输出特征图的边长
K: 每个卷积核的边长
Cin每个卷积核的通道数,也即输入通道数,也即上一层的输出通道数。
Cout本卷积层具有的卷积核个数,也即输出通道数。
可见,每个卷积层的时间复杂度由输出特征图面积M^2、卷积核面积 K^2 、输入 Cin和输出通道数 Cout 完全决定。
其中,输出特征图尺寸本身又由输入矩阵尺寸X、卷积核尺寸 K 、Padding、Stride 这四个参数所决定,表示如下:
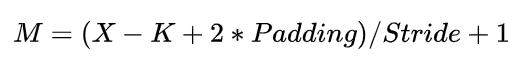
注1:为了简化表达式中的变量个数,这里统一假设输入和卷积核的形状都是正方形。
注2:严格来讲每层应该还包含 1 个 Bias 参数,这里为了简洁就省略了。
1.2 卷积神经网络整体的时间复杂度
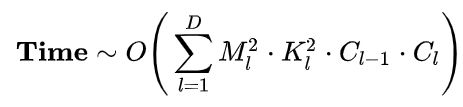
D神经网络所具有的卷积层数,也即网络的深度。
l神经网络第 l 个卷积层
Cl神经网络第 Cl 个卷积层的输出通道数 Cout ,也即该层的卷积核个数。
对于第 l 个卷积层而言,其输入通道数 Cin 就是第 l-1 个卷积层的输出通道数。
可见,CNN整体的时间复杂度并不神秘,只是所有卷积层的时间复杂度累加而已。
简而言之,层内连乘,层间累加。
示例:用 Numpy 手动简单实现二维卷积
假设 Stride = 1, Padding = 0, img 和 kernel 都是 np.ndarray.
def conv2d(img, kernel):
height, width, in_channels = img.shape
kernel_height, kernel_width, in_channels, out_channels = kernel.shape
out_height = height - kernel_height + 1
out_width = width - kernel_width + 1
feature_maps = np.zeros(shape=(out_height, out_width, out_channels))
for oc in range(out_channels): # Iterate out_channels (# of kernels)
for h in range(out_height): # Iterate out_height
for w in range(out_width): # Iterate out_width
for ic in range(in_channels): # Iterate in_channels
patch = img[h: h + kernel_height, w: w + kernel_width, ic]
feature_maps[h, w, oc] += np.sum(patch * kernel[:, :, ic, oc])
return feature_maps
2. 空间复杂度
空间复杂度(访存量),严格来讲包括两部分:总参数量 + 各层输出特征图。
参数量:模型所有带参数的层的权重参数总量(即模型体积,下式第一个求和表达式)
特征图:模型在实时运行过程中每层所计算出的输出特征图大小(下式第二个求和表达式)
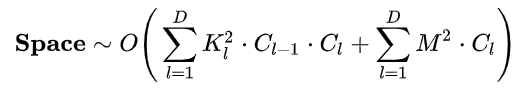
总参数量只与卷积核的尺寸 K 、通道数 C 、层数 D 相关,而与输入数据的大小无关。
输出特征图的空间占用比较容易,就是其空间尺寸 M^2 和通道数 C 的连乘。
注:实际上有些层(例如 ReLU)其实是可以通过原位运算完成的,此时就不用统计输出特征图这一项了。
3. 复杂度对模型的影响
时间复杂度决定了模型的训练/预测时间。如果复杂度过高,则会导致模型训练和预测耗费大量时间,既无法快速的验证想法和改善模型,也无法做到快速的预测。
空间复杂度决定了模型的参数数量。由于维度诅咒的限制,模型的参数越多,训练模型所需的数据量就越大,而现实生活中的数据集通常不会太大,这会导致模型的训练更容易过拟合。
当我们需要裁剪模型时,由于卷积核的空间尺寸通常已经很小(3x3),而网络的深度又与模型的表征能力紧密相关,不宜过多削减,因此模型裁剪通常最先下手的地方就是通道数。
4. Inception系列模型是如何优化复杂度的
通过五个小例子说明模型的演进过程中是如何优化复杂度的。
4.1 InceptionV1 中的 1X1 卷积降维同时优化时间复杂度和空间复杂度
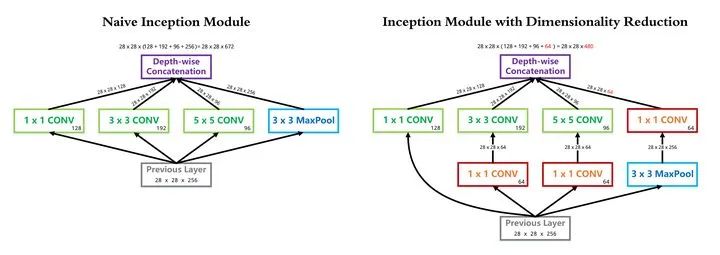
InceptionV1 借鉴了 Network in Network 的思想,在一个 Inception Module 中构造了四个并行的不同尺寸的卷积/池化模块(上图左),有效的提升了网络的宽度。但是这么做也造成了网络的时间和空间复杂度的激增。对策就是添加 1 x 1 卷积(上图右红色模块)将输入通道数先降到一个较低的值,再进行真正的卷积。
以 InceptionV1 论文中的 (3b) 模块为例(可以点击上图看超级精美的大图),输入尺寸为 28x28x256, 1x1 卷积核 128 个, 3x3 卷积核 192 个, 5x5 卷积核 96 个,卷积核一律采用 Same Padding 确保输出不改变尺寸。
在 3x3 卷积分支上加入 64 个 1x1 卷积前后的时间复杂度对比如下式:
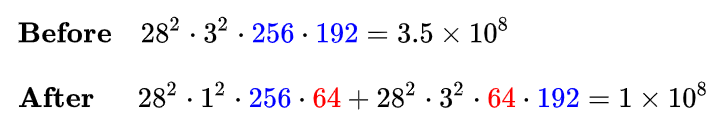
同理,在 5x5 卷积分支上加入 64 个 1x1 卷积前后的时间复杂度对比如下式:
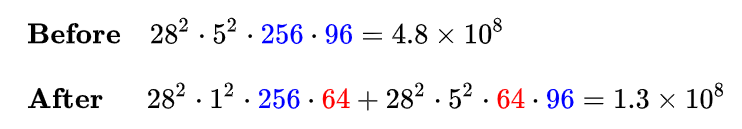
可见,使用 1x1 卷积降维可以降低时间复杂度3倍以上。该层完整的运算量可以在论文中查到,为 300 M,即 3x10^8 。
另一方面,我们同样可以简单分析一下这一层参数量在使用 1 x 1 卷积前后的变化。可以看到,由于 1 x 1 卷积的添加,3 x 3 和 5 x 5 卷积核的参数量得以降低 4 倍,因此本层的参数量从 1000 K 降低到 300 K 左右。
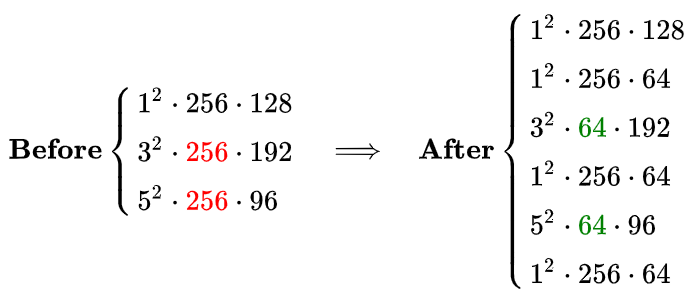
4.2 InceptionV1 中使用GAP代替 Flatten
全连接层可以视为一种特殊的卷积层,其卷积核尺寸 K 与输入矩阵尺寸 X 一模一样。每个卷积核的输出特征图是一个标量点,即 M = 1 。复杂度分析如下:
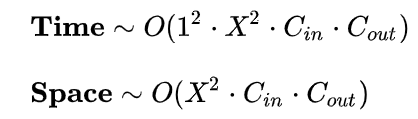
可见,与真正的卷积层不同,全连接层的空间复杂度与输入数据的尺寸密切相关。因此如果输入图像尺寸越大,模型的体积也就会越大,这显然是不可接受的。例如早期的VGG系列模型,其 90% 的参数都耗费在全连接层上。
InceptionV1 中使用的全局平均池化 GAP 改善了这个问题。由于每个卷积核输出的特征图在经过全局平均池化后都会直接精炼成一个标量点,因此全连接层的复杂度不再与输入图像尺寸有关,运算量和参数数量都得以大规模削减。复杂度分析如下:

4.3 InceptionV2 中使用两个 3x3 卷积级联替代 5x5 卷积分支
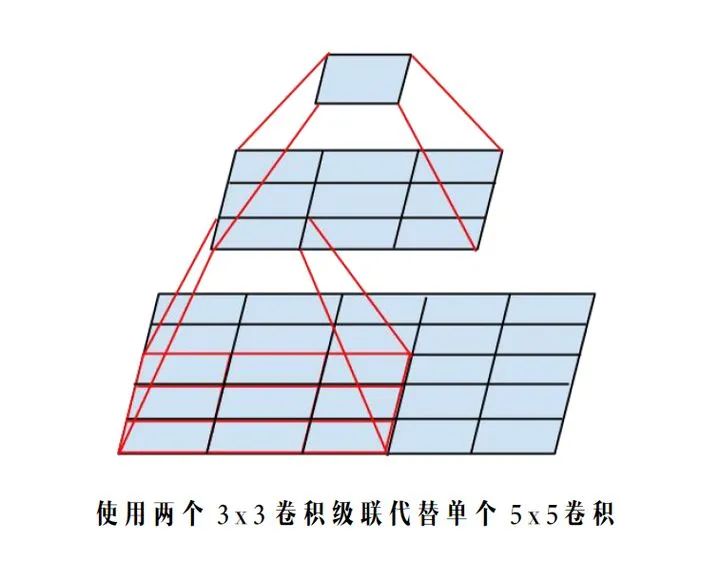
根据上面提到的二维卷积输入输出尺寸关系公式,可知:对于同一个输入尺寸,单个 5x5 卷积的输出与两个 3x3 卷积级联输出的尺寸完全一样,即感受野相同。
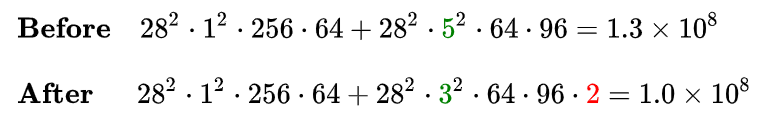
4.4 InceptionV3 中使用 1xN 与 Nx1 卷积级联替代 NxN 卷积
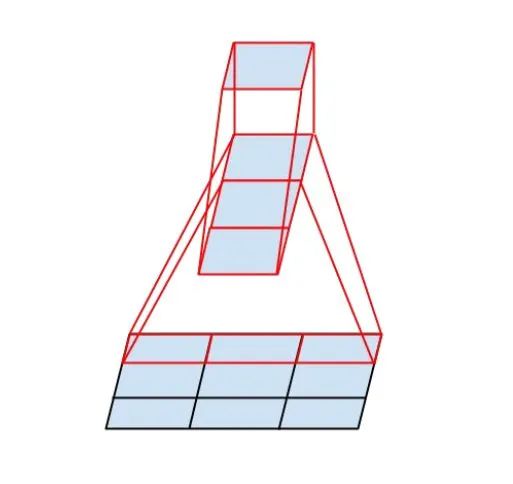
InceptionV3 中提出了卷积的 Factorization,在确保感受野不变的前提下进一步简化。
复杂度的改善同理可得,不再赘述。
4.5 Xception 中使用 Depth-wise Separable Convolution
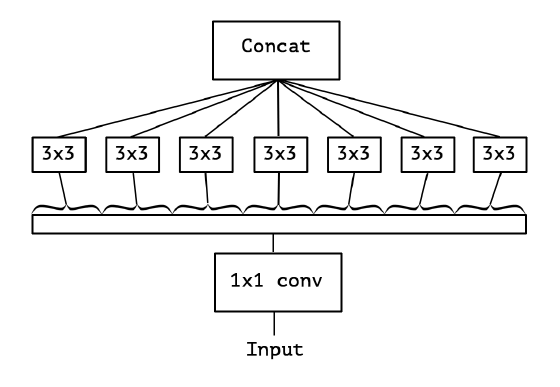
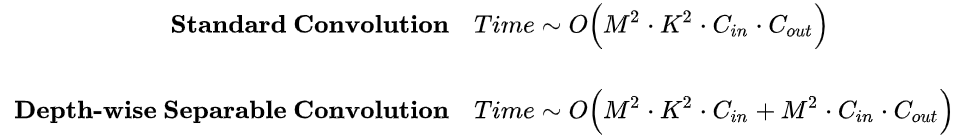
5. 总结
参考论文
Convolutional Neural Networks at Constrained Time Cost
Going Deeper with Convolutions
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Rethinking the Inception Architecture for Computer Vision
Xception: Deep Learning with Depthwise Separable Convolutions
END
点赞三连,支持一下吧↓