
NLP系列之NER/RE:序列标注/层叠指针网络/Multi-head Selection/Deep Biaffine Attn
作者简介
作者:ZHOU-JC (广州云迪科技有限公司 NLP算法工程师)
原文:https://zhuanlan.zhihu.com/p/381894616
前言
上一篇博客提到用BERT+CRF幸运地拿到天池比赛的亚军,但还想进一步探究其它模型架构。一方面,比赛不存在实体嵌套问题,故用BERT+CRF也能取得不俗的成绩,另一方面,这几年陆续诞生了很多实体识别/关系抽取的SOTA模型,掌握它们,再根据自己遇到的业务场景设计方案是十分重要的。
本博文主要探究关系抽取,但很多方法对于NER任务来说也是通用的。目前常见的做关系抽取的框架可以参考这篇博文,

博文里提到的序列标注、指针标注、多头标注、片段排列都是目前比较常见的框架。
关系抽取:Pipeline vs Joint
关系抽取就是实体识别以及判断实体之间的关系,有两种方式:
pipeline:第一步使用序列标注模型抽取实体,第二步使用关系分类模型得到实体pair的关系;
joint联合抽取:使用同一个模型来完成实体抽取和关系分类,也即意味着这一个模型的部分参数对于实体识别、关系分类来说是共享的。
pipeline
优点
灵活,解耦,在一个公司里可以一组人做实体识别、一组人做关系抽取,各自优化各自的部分。
缺点
error propagation,误差传播:实体抽取错误的,会影响后续的关系分类;
忽略了实体识别和关系分类之间的关系,看下图,《》围住的可能是书名或歌名,对应的关系是作者和歌手。假如关系识别出是作者,那《》围住的大概率就是书名,也即关系识别对实体识别是有启示作用的,同理,实体识别对关系分类也有启示作用,把它们解耦无法让它们产生交互;

3. 计算资源占用大。如第一步抽取出n个实体,那第二步我们要把  个实体pairs传到关系分类模型,而实际上,大部分pair是没关系的,造成大量的计算资源浪费。
个实体pairs传到关系分类模型,而实际上,大部分pair是没关系的,造成大量的计算资源浪费。
joint联合抽取
优点:
pipeline的缺点反过来就是joint的优点。
缺点
虽然在训练时是用joint的方式,共享部分模型参数,这部分参数通过实体抽取和关系分类共同更新,但在predict解码时,大部分joint架构用的还是先抽取实体,再把这部分信息作为关系分类输入的一部分。这种解码方法本质上和pipeline无区别,一样会造成误差传播,暴露偏差的问题,当然目前也有类似TPLinker这种联合解码的方法解决暴露偏差的问题。
如何平衡实体识别以及关系抽取的关系。就像多任务学习一样,怎么平衡它们之间的损失是要考虑的问题。
方法实验细节及代码复现
任务描述
这里用百度2021语言与智能技术竞赛的多形态信息抽取任务中的关系抽取赛道作为实验
比赛链接:

任务就是常见的SPO三元组抽取,根据预先定义的schema集合,抽取出所有满足schema约束的SPO三元组。有些特殊的是,比赛里有43个简单知识,即O是一个单一的文本片段,如「海拔」关系的schema定义为:
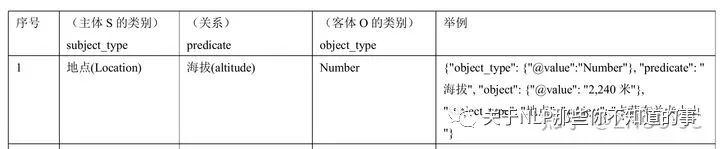
也有5个复杂知识,即O是一个结构体,由多个语义明确的文本片段共同组成,多个文本片段对应了结构体中的多个槽位 (slot)。例如,「饰演」关系中O值有两个槽位@value和inWork,分别表示「饰演的角色是什么」以及「在哪部影视作品中发生的饰演关系」,其schema定义为:
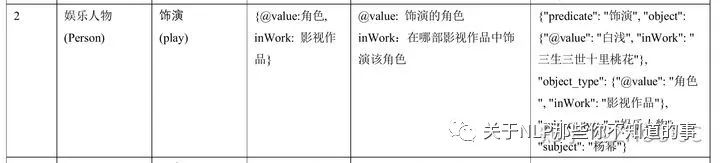
比赛提供约17+万训练数据,2万+条验证数据。由于比赛已经结果,无法得到测试集结果,以下实验的分数均为模型在验证集上最佳表现。
一:序列标注(官方baseline)
详细的可以看百度官方对提供的baseline的解读

官方提供的baseline核心就是利用序列标注BIO的方式来一起做实体抽取和关系分类。
简单地描述一下就是,schema有43个简单知识,这部分实体类别一共有43*2=86个(因为每一个知识,有subject和object两个实体),如对上面提到的「海拔」关系,我们可以定义以下两个实体:

对5个复杂知识,这部分实体一共有4*2*2+4*2= 24个实体(有4个复杂知识的object_type有2个,有一个复杂知识的object_type有4个),如上面提到的「饰演」关系,我们需要定义以下四个实体:
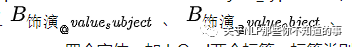
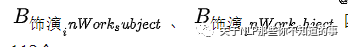
加上O、I两个标签,标签类别一共有112个。
序列标注框架有很多,如BertTokenClassification、Bert+Crf等等。由于本案例存在实体嵌套问题,所以每个token的输出不作softmax,而是转化为sigmoid二分类问题,即最后得到的矩阵维度应该是【B,L,112】,每个元素做的是sigmoid二分类。这样,每个token可以有多个标签,从而解决实体嵌套问题。
解码时,首先得到每个token的标签,再根据schema表组织成相应的关系,不过看官方的代码,感觉解码时会有问题。例如看下图,假如抽取出 主演(subject) 有【逃学威龙、精武英雄】、主演(object) 有【周星驰、李连杰】,组合关系的时候,怎么知道逃学威龙对应的是周星驰,而不是李连杰?
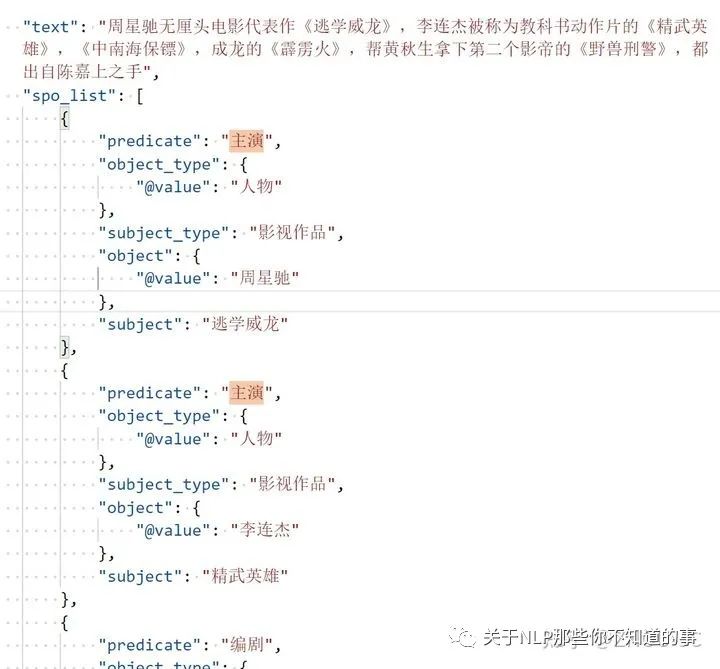
官网提供的baseline的好处就是快,以及解决暴露偏差问题。坏处就是效果有效,在实体分类时,有112个二分类,另外就是解码时的问题。
二:层叠式指针网络(基于主语感知)
源自苏神的这两篇文章:

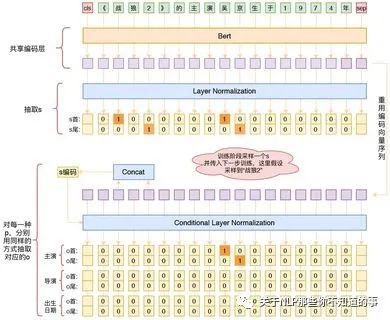
,也可以看20年关系抽取赛道获奖冠军队伍分享视频,苏神他们就是利用这个架构取得20年该赛道的冠军。
核心思路就是先抽取subject,再抽取谓语predict和宾语object。
具体的,用指针网络的方式抽取subject,指针网络为【B, L, 2】的矩阵,由于一个样本中有多个subject,所以矩阵的每个元素做的是sigmoid,而不是softmax(这种方式称为“半指针-半标注”),注意这里没有引入实体标签信息。
抽取完subjects后,分别把每个subject,引入Conditiaonal LayerNorm,这一步相当于预测PO时,告诉模型,S是什么,使得模型学习到PO的预测是依赖于S的。注意的是,这一步要预测一个【B, L, R_num, 2】,这里R_num是关系类别数,同样是一个半指针-半序列的问题,把O和P同时预测出来。
三:Multi-head Selection
源自两篇论文:
多头标注核心在于最后要构造一个 【B, L, L, R_num】矩阵。
首先采用半指针-半标注抽取subject和object,这里得到的矩阵为【B, L, 2, E_num】,这里E_num是实体标签的类别数,这里同上面提到的层叠式指针网络不同在于,一方面,层叠式指针网络抽subject的时候,只需要把subject抽取出来,而无需知道它的标签信息,而这里,不仅要把实体抽取出来,通过扩展一个长度为E_num的维度,把实体标签也抽取出来,另一方面,这里不仅要抽取subject,还要同时把object抽取出来。
上一步得到实体标签的目的在于接下来把实体标签embedding和Bert的输出拼接在一起,然后再接后面的全连接层,最后得到一个【B, L,L, R_num】的矩阵。这个矩阵就是关键的核心,怎么理解这个矩阵呢?举个例子,假如这个矩阵的【0, m, n, r】元素大于0.5,即第一个样本,结尾index为m的实体作为subject,和结尾index为n的实体作为object,它们之间的关系是id为r的关系。
四:Deep Biaffine Attention
源自两篇论文:
Deep Biaffine Attention最后也是为了得到一个【B, L, L, R_num】矩阵,不同于Multi-head Selection中是通过多个线性分类器加激活函数得到的多头矩阵,Deep Biaffine Attention思想是通过一个Biaffine Attention矩阵得到多头矩阵。
这里 h(s) 理解成subject矩阵,它是通过把实体标签embedding和Bert输出拼接后接全连接层得到的,h(o) 理解成object矩阵,它也是通过把实体标签embedding和Bert输出拼接后接全连接层得到的,这两个矩阵是不同的,一个代表subject,一个代表object。
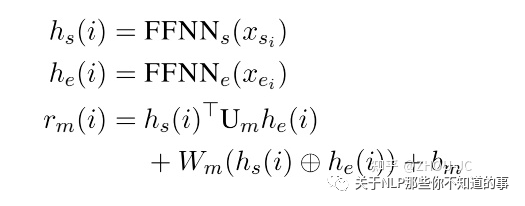
最后得到的 r(m) 其实就是多头矩阵的【某一个样本, s, e, :】,判断两个位置的实体是否存在关系。其中 Um 、Wm 、b(m) 的shape及其意义如下:
Um:shape为【H, R_num, H】,对h(s) 为subject和 h(o) 为object的实体类别后验概率建模;
Wm :shape为【2*H, R_num】,对 h(s) 为subject或h(o) 为object的实体类别的后验概率分别建模;
b(m) :shape为【R_num】,对实体类别的先验概率建模。
把它们加在一起,就是以h(s) 为subject, h(o) 为object,分别在R_num个关系类别的概率。
为何叫做biaffine?个人理解就是因为引入了一个先验概率,把 b(m) 也放到 Wm 中,这样
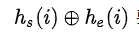
要拓展多一列,全是【1, 1, 1, 1, ...】,这一行和 Wm 中的 b(m) 就得到 b(m) 。
把 Deep Biaffine Attention 和 Multi-head Selection 做比较,虽然它们最后得到的都是【B, L, L, R_num】矩阵,只不过Deep Biaffine Attention是通过一个 Um 矩阵让subject信息和object发生交互,而Multi-head Selection中subject和object其实是没有发生这种耦合交互的。
实验结果对比
由于资源有效,BERT用的是哈工大讯飞联合实验室发布的三层BERT。
| F1值 | |
|---|---|
| 官方baseline | 64.69 |
| 层叠式指针网络(基于主语感知) | 61.22 |
| Multi-head Selection | 67.90 |
| Deep Biaffine Attention | 68.45 |
感觉层叠式指针网络的复现感觉有点问题,按理说,不至于比baseline效果要差,具体的原因可能是采样问题,也有可能是解码问题,具体原来要再检查一下代码。
效果比较:
Deep Biaffine Attention > Multi-head Selection > 官方baseline > 层叠式指针网络(基于主语感知)。
计算效率比较:
官方baseline > 层叠式指针网络(基于主语感知)> Multi-head Selection > Deep Biaffine Attention。
个人思考及总结
本文介绍了关系抽取的四种方法,在实际应用场景中,我们要根据具体任务灵活运用。对于关系抽取来说,更重要的是掌握一些常用框架,如开头提到的序列标注、指针网络、多头标准、片段排列,上面的四种方法其实都是这四个框架的组合,再经过一些设计的微调罢了。
另外要注意计算效率和空间利用率的问题。baseline虽然简单,但它是计算最快,参数最小的,很多场景下baseline不失为一种好的解决方案,其次,Deep biaffine Attention效果最好,但是计算最慢,参数最多。
本博文主要讨论框架,但在实际业务中,关系抽取还有很多现实问题,如
假阴性,这是由于大部分关系抽取的标注都是通过远程监督的方法,导致很多漏标,这样训练出来的模型召回率会比准确率低;
标签不平衡,上面提到的很多方法,如指针网络、多头矩阵最后得到的大部分标签都是0,只有小部分是1,怎么平衡0和1之间的关系。
有机会再跟大家分享关系抽取落地的难点。
主要参考:
科学空间:《基于DGCNN和概率图的轻量级信息抽取模型
科学空间:《用bert4keras做三元组抽取》
JayJay:《刷爆3路榜单,信息抽取冠军方案分享:嵌套NER+关系抽取+实体标准化》
《信息抽取(二)花了一个星期走了无数条弯路终于用TF复现了苏神的《Bert三元关系抽取模型》,我到底悟到了什么?》
《信息抽取(四)【NLP论文复现】Multi-head Selection和Deep Biaffine Attention在关系抽取中的实现和效果》
Joint entity recognition and relation extraction as a multi-head selection problem
BERT-Based Multi-Head Selection for Joint Entity-Relation Extraction
Deep Biaffine Attention for Neural Dependency Parsing
Named Entity Recognition as Dependency Parsing