
fastNLP工具包, 快速实现序列标注模型

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
fastNLP是一款轻量级的自然语言处理(NLP)工具包,目标是快速实现NLP任务以及构建复杂模型。
fastNLP具有如下的特性:
统一的Tabular式数据容器,简化数据预处理过程;
内置多种数据集的Loader和Pipe,省去预处理代码;
各种方便的NLP工具,例如Embedding加载(包括ELMo和BERT)、中间数据cache等;
部分数据集与预训练模型的自动下载;
提供多种神经网络组件以及复现模型(涵盖中文分词、命名实体识别、句法分析、文本分类、文本匹配、指代消解、摘要等任务);
Trainer提供多种内置Callback函数,方便实验记录、异常捕获等。
安装指南
fastNLP 依赖以下包:
numpy>=1.14.2
torch>=1.0.0
tqdm>=4.28.1
nltk>=3.4.1
requests
spacy
prettytable>=0.7.2
其中torch的安装可能与操作系统及 CUDA 的版本相关,请参见 PyTorch 官网 。在依赖包安装完成后,您可以在命令行执行如下指令完成安装
pip install fastNLP
python -m spacy download en
fastNLP教程
中文文档、教程
快速入门
0. 快速入门
详细使用教程
1. 使用DataSet预处理文本
2. 使用Vocabulary转换文本与index
3. 使用Embedding模块将文本转成向量
4. 使用Loader和Pipe加载并处理数据集
5. 动手实现一个文本分类器I-使用Trainer和Tester快速训练和测试
6. 动手实现一个文本分类器II-使用DataSetIter实现自定义训练过程
7. 使用Metric快速评测你的模型
8. 使用Modules和Models快速搭建自定义模型
9. 快速实现序列标注模型
10. 使用Callback自定义你的训练过程
扩展教程
Extend-1. BertEmbedding的各种用法
Extend-2. 分布式训练简介
Extend-3. 使用fitlog 辅助 fastNLP 进行科研
内置组件
大部分用于的 NLP 任务神经网络都可以看做由词嵌入(embeddings)和两种模块:编码器(encoder)、解码器(decoder)组成。
以文本分类任务为例,下图展示了一个BiLSTM+Attention实现文本分类器的模型流程图:
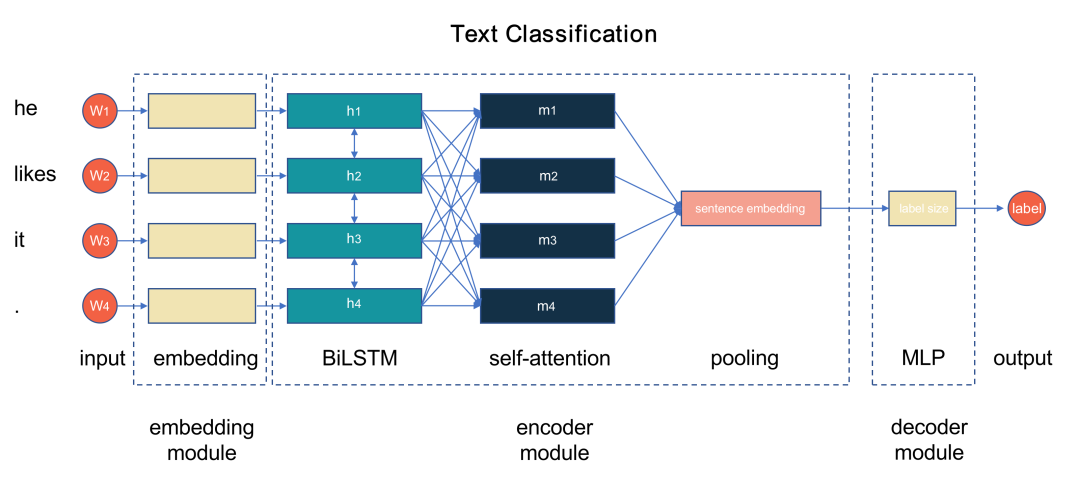
fastNLP 在 embeddings 模块中内置了几种不同的embedding:静态embedding(GloVe、word2vec)、上下文相关embedding (ELMo、BERT)、字符embedding(基于CNN或者LSTM的CharEmbedding)
与此同时,fastNLP 在 modules 模块中内置了两种模块的诸多组件,可以帮助用户快速搭建自己所需的网络。两种模块的功能和常见组件如下:
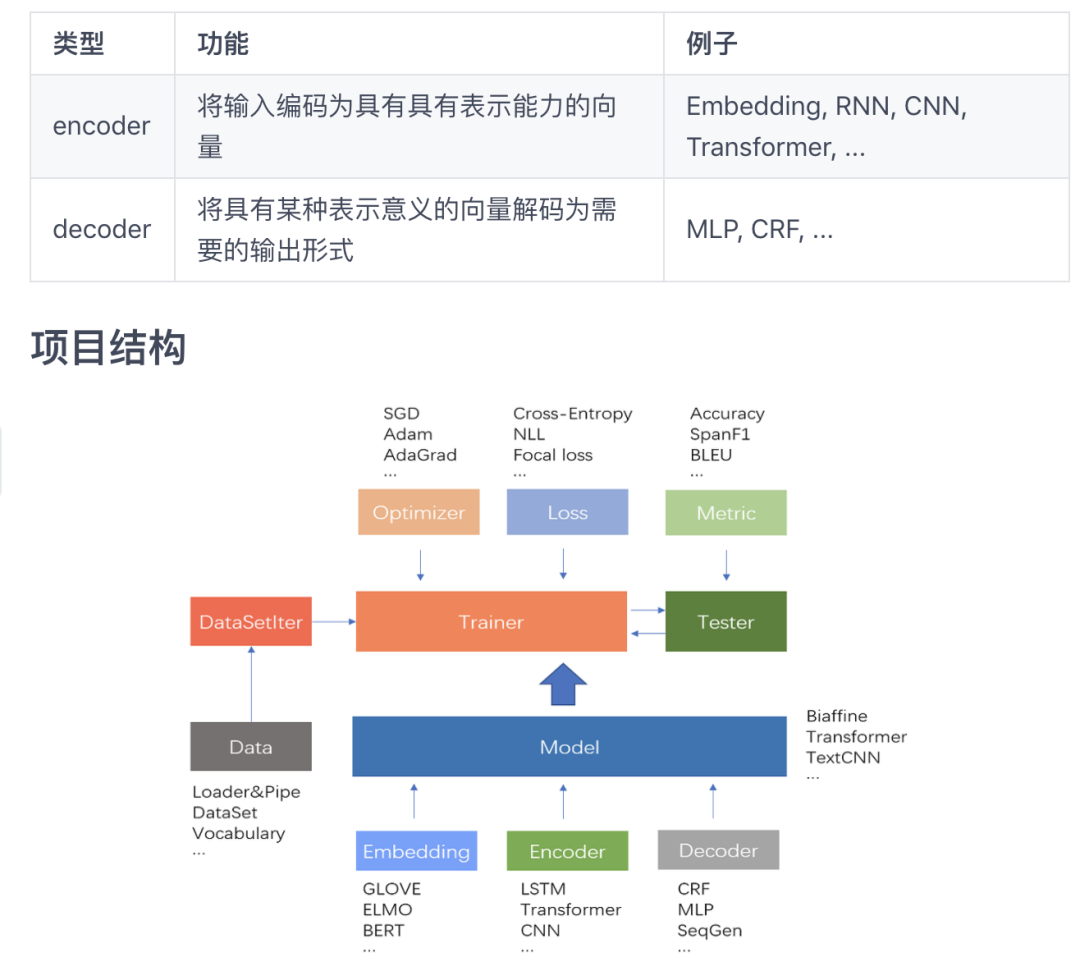
fastNLP的大致工作流程如上图所示,而项目结构如下:
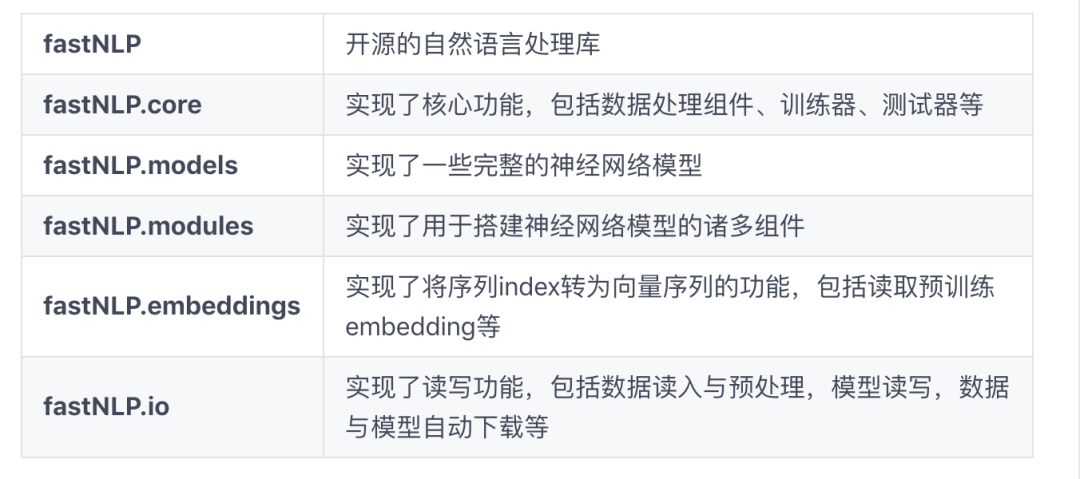
代码 获取方式:
分享本文到朋友圈
关注微信公众号 datayx 然后回复 NLP 即可获取。
AI项目体验地址 https://loveai.tech
单肩包/双肩包/斜挎包/手提包/胸包/旅行包/上课书包 /个性布袋等各式包饰挑选
https://shop585613237.taobao.com/
序列标注
这一部分的内容主要展示如何使用fastNLP实现序列标注(Sequence labeling)任务。您可以使用fastNLP的各个组件快捷,方便地完成序列标注任务,达到出色的效果。在阅读这篇教程前,希望您已经熟悉了fastNLP的基础使用,尤其是数据的载入以及模型的构建。通过这个小任务,能让您进一步熟悉fastNLP的使用。
命名实体识别(name entity recognition, NER)
命名实体识别任务是从文本中抽取出具有特殊意义或者指代性非常强的实体,通常包括人名、地名、机构名和时间等。如下面的例子中
我来自复旦大学。
其中“复旦大学”就是一个机构名,命名实体识别就是要从中识别出“复旦大学”这四个字是一个整体,且属于机构名这个类别。这个问题在实际做的时候会被 转换为序列标注问题
针对"我来自复旦大学"这句话,我们的预测目标将是[O, O, O, B-ORG, I-ORG, I-ORG, I-ORG],其中O表示out,即不是一个实体,B-ORG是ORG( organization的缩写)这个类别的开头(Begin),I-ORG是ORG类别的中间(Inside)。
在本tutorial中我们将通过fastNLP尝试写出一个能够执行以上任务的模型。
载入数据
fastNLP的数据载入主要是由Loader与Pipe两个基类衔接完成的,您可以通过 使用Loader和Pipe处理数据 了解如何使用fastNLP提供的数据加载函数。下面我们以微博命名实体任务来演示一下在fastNLP进行序列标注任务。
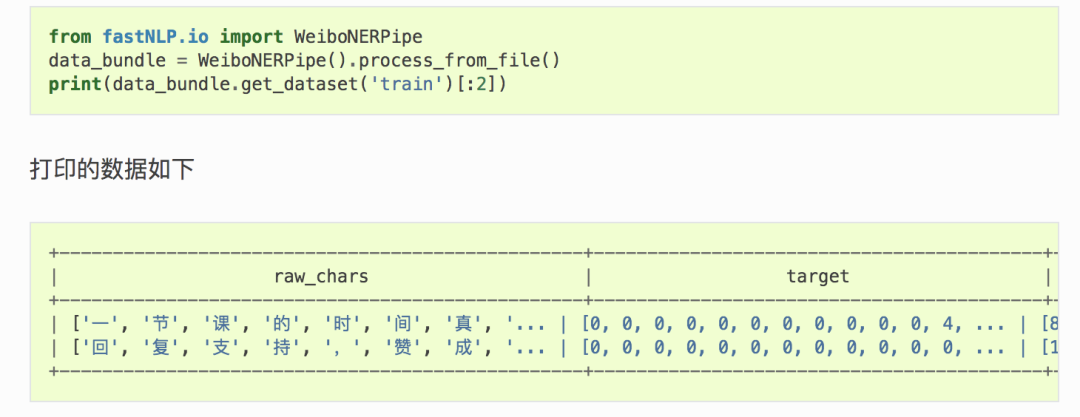
模型构建
首先选择需要使用的Embedding类型。关于Embedding的相关说明可以参见 使用Embedding模块将文本转成向量 。在这里我们使用通过word2vec预训练的中文汉字embedding。

进行训练
下面我们选择用来评估模型的metric,以及优化用到的优化函数。

进行测试
训练结束之后过,可以通过 Tester 测试其在测试集上的性能
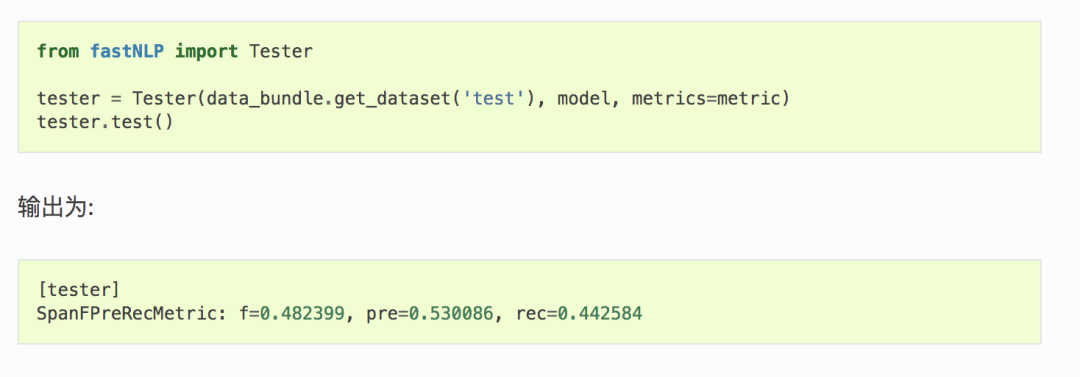
使用更强的Bert做序列标注
在fastNLP使用Bert进行任务,您只需要把 fastNLP.embeddings.StaticEmbedding 切换为 fastNLP.embeddings.BertEmbedding (可修改 device 选择显卡)。

输出为:
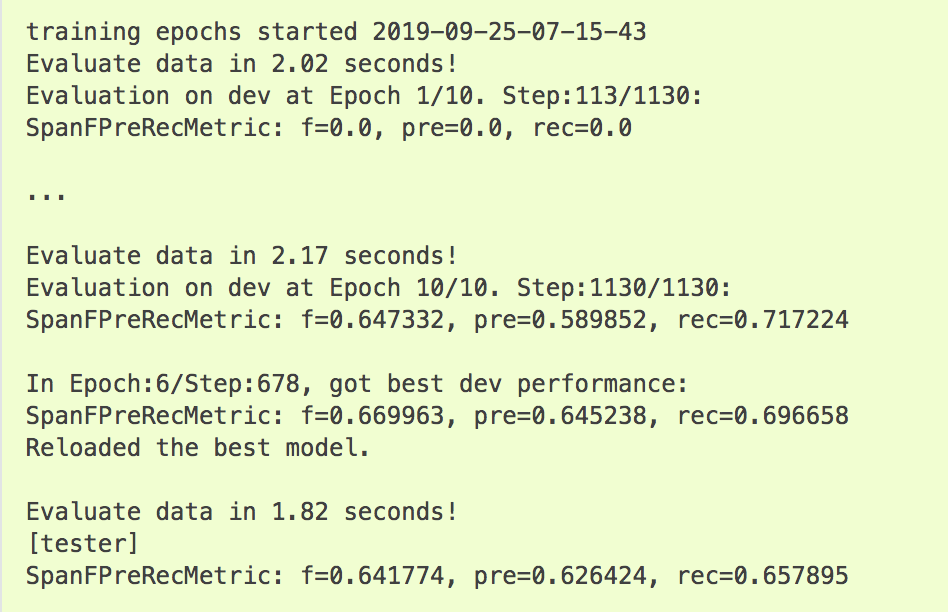
可以看出通过使用Bert,效果有明显的提升,从48.2提升到了64.1。
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
机大数据技术与机器学习工程
搜索公众号添加: datanlp
长按图片,识别二维码