
【NLP】NER数据标注中的标签一致性验证
数据标注在建立基准和确保使用正确的信息来学习NER模型方面起着至关重要的作用。要想获得准确的标签,不仅需要时间还需要专业知识。然而标签错误又几乎是无法避免的,错误的标签会导致标注数据子集(例如,训练集和测试集,或多个训练子集)之间的标签不一致。标签的不一致性是影响NER任务性能提升的因素之一,比如在被引用超过2300次的标准NER基准CoNLL03数据集中,发现测试集中有5.38%的标签错误,当对其中的错误标签进行纠正后,相比于原始测试集得到的结果更加准确和稳定。
标签的一致性验证需要解决两个关键问题:1)如何识别标注的数据子集之间的标签不一致?2)如何验证纠正后的标签一致性得到恢复?
如下表所示,三个示例是用于比较SCIERC数据集的测试集中原始标注和校正后的标注。其中前两个是具有错误的实体类型,第三个是具有错误的实体边界。像前两个示例中的实体标记,如果在标注过程中始终遵循用于标注训练数据的“codebook”,那么一定能够将前两个示例中的实体标记为“Task”,而非“Method”。
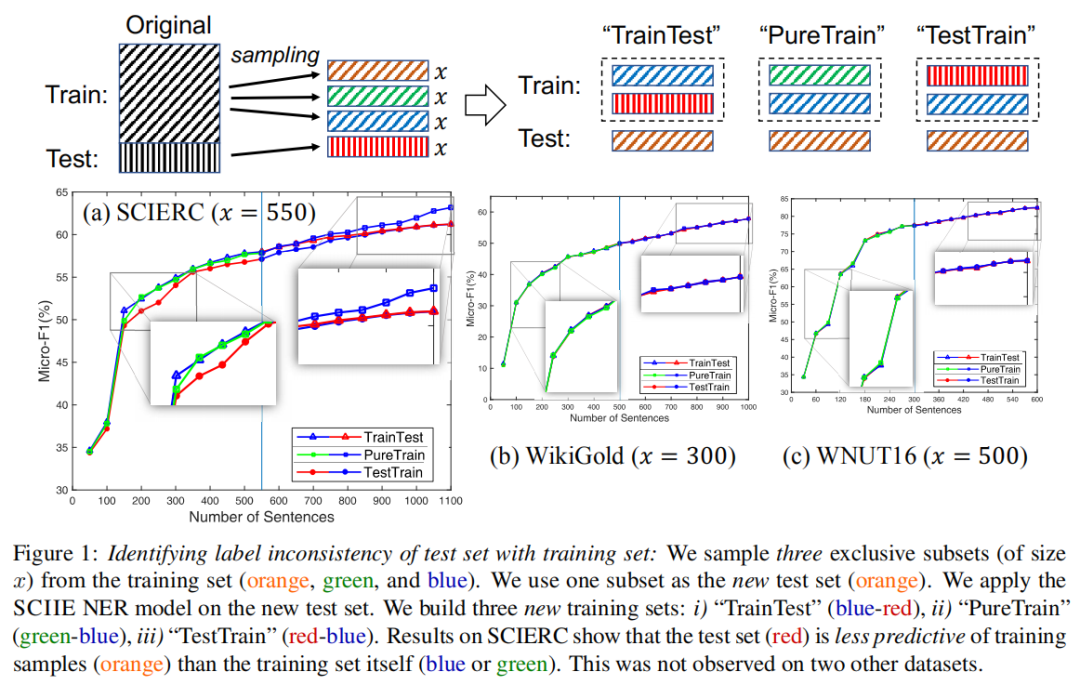
如下图所示,是识别测试集与训练集的标签不一致性。以SCIERC数据集为例,从训练集中采样三个互斥子集(大小为x),选择这三个互斥子集中的一个子集作为新的测试集,然后构建三个新的训练集,分别为:
“TrainTest”:首先提供一个训练子集,然后再提供一个原始测试集
“PureTrain”:提供两个训练子集
“TestTrain”:首先输入原始测试集,然后输入一个训练子集
然后训练NER模型以在新的测试集上执行,结果表明,“TestTrain”在早期阶段表现最差,因为原始测试集的质量不可靠。在“TrainTest”中,当开始向模型提供原始测试集时,性能不再提高。“PureTrain”表现最好。所有观察结果都得出结论,原始测试集比训练集本身对训练样本的预测性差。而在其他的两个数据集WikiGold和WNUT16上没有这样的观察结果,则这可能是由于标签不一致导致的问题。
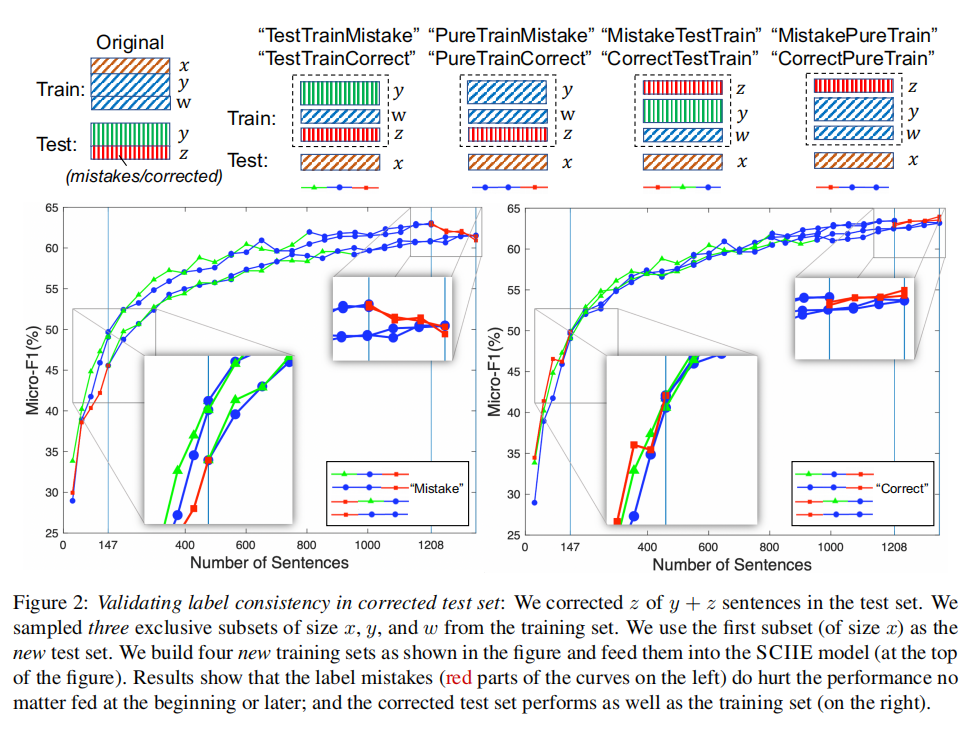
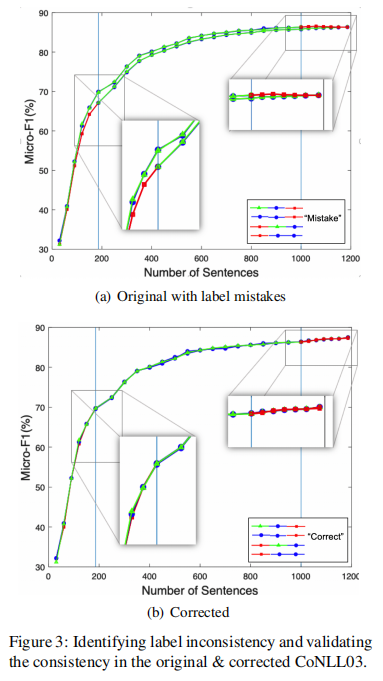
这是对纠正错误标签后的标签一致性进行验证,同样将训练数据中的子集作为新的测试集,以评估原始错误测试子集、更正后的测试子集以及其余训练子集的可预测性。以SCIERC数据集为例,假设在测试集中纠正了y+z个句子中的z个,原始的错误测试子集("Mistake")和校正后的测试子集(“Correct”)的大小均为z(z=147),在训练集中采样三个互斥子集,分别为x、y、w,使用训练集中第一个子集x作为新的测试集,然后建立四个新的训练集(每个新的训练集都有y+w+z=1355个句子)如下:
“TestTrainMistake”/“TestTrainCorrect”:原始的良好测试子集,第三个采样的训练子集和原始的错误测试子集(或校正后的测试子集)
“PureTrainMistake”/“PureTrainCorrect”:第二个和第三个采样的训练子集以及原始错误的测试子集(或校正后的测试子集)
“MistakeTestTrain”/“CorrectTestTrain”:原始错误的测试子集(或更正的测试子集),原始的良好测试子集和第三个采样的训练子集
“MistakePureTrain”/“CorrectPureTrain”:原始错误的测试子集(或更正的测试子集)以及第二个和第三个采样的训练子集。
然后训练NER模型,结果表明,标签错误(即原始错误的测试子集)在开始或最后被输入时都会损害模型性能。校正后的测试子集可提供与原始良好测试子集和训练子集相当的性能。这证明了校正后的测试集与训练集的标签一致性。
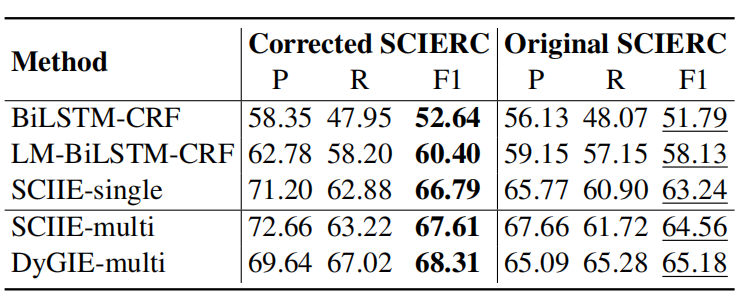
基于SCIERC数据集,部署五个NER模型,研究它们在校正后的SCIERC数据集上的性能。如下图所示,所有NER模型在校正后的SCIERC上都要比原始数据集提供更好的性能。
如下图a所示,在原始测试集中以错误的标签开头会使性能比从训练集或良好的测试子集开始的性能差。如下图b所示,在标签校正之后,此问题得到修复。
参考资料:
[1]https://arxiv.org/pdf/2101.08698v1.pdf
- END -
往期精彩回顾
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: