
【NLP】NLP重铸篇之Fasttext

论文标题:Bag of Tricks for Efficient Text Classification
论文链接:https://arxiv.org/pdf/1607.01759.pdf
代码地址:https://github.com/facebookresearch/fastText
复现代码地址:https://github.com/wellinxu/nlp_store/blob/master/papers/fasttext.py

论文标题:Enriching Word Vectors with Subword Information
论文链接:https://arxiv.org/pdf/1607.04606.pdf
代码地址:https://github.com/facebookresearch/fastText
复现代码地址:https://github.com/wellinxu/nlp_store/blob/master/papers/fasttext.py
fasttext主要有两个模型,一个是【Bag of Tricks for Efficient Text Classification】提出的文本分类模型,一个是【Enriching Word Vectors with Subword Information】提出的文本表示模型,其结构跟word2vec非常相似,最大区别是,分类模型添加了词粒度的ngram特征,表示模型添加了字符粒度的ngram特征(subword特征)。本文会分别介绍fasttext的分类与表示模型,并复现相关代码,具体可查看https://github.com/wellinxu/nlp_store。
fasttext 文本分类 模型结构 ngram特征 论文结果 文本表示 模型结构 subword特征 论文结果 fasttext与word2vec结果比较 参考
fasttext
fasttext是facebook在2016年左右提出的模型,在相关代码里面,主要包含了两个模型:文本分类模型和文本表示模型,因为两个模型都在同一个代码包里,所以都被大家称为fasttext模型。根据原始论文来看,fasttext的文本分类模型就是word2vec中的cbow+huffman树的结构,区别在于添加了词级别的ngram特征(并对ngram特征做了hash处理)并且预测的标签是具体的类别;而fasttext的文本表示模型就是word2vec中的skip-gram+负采样的结构,区别在于添加了字符级别的ngram特征(即subword,也进行了hash处理)。因为fasttext与word2vec模型非常相似,所以建议先看【NLP重铸篇之Word2vec】。
文本分类
【Bag of Tricks for Efficient Text Classification】论文中提出了一种文本分类模型fasttext,可以作为一种高效的文本分类基准,其精度较高,且速度飞快,使用标准的多核CPU,可以在10分钟内训练包含10亿词的文本,在一分钟内可以对包含30多万类别的500万句文本进行分类(复现代码的速度则远远不如,原代码在工程上做了很多优化)。
模型结构

如上图所示,与word2vec的CBOW结构类似,特征输入模型后,直接进行求和(或平均)然后就输出预测模型,为了提高运算速度,当类别比较多的时候,fasttext文本分类模型也采用了层次softmax的方法,具体的也是使用的huffman树的形式。更多关于COBW结构与huffman树的loss计算可参考【NLP重铸篇之Word2vec】,这边给出前向传播相关代码:
def call(self, inputs, training=None, mask=None):
# x:[context_len]
# huffman_label: [label_size, code_len]
# huffman_index: [label_size, code_len]
# y : [label_size]
# negative_index: [negatuve_num]
x, huffman_label, huffman_index, y, negative_index = inputs
x = self.embedding(x) # [context_len, emb_dim]
x = tf.reduce_sum(x, axis=-2) # [emb_dim]
loss = 0
# huffman树loss计算
if self.is_huffman:
for tem_label, tem_index in zip(huffman_label, huffman_index):
# 获取huffman树编码上的各个结点参数
huffman_param = self.huffman_params(tem_index) # [code_len, emb_dim]
# 各结点参数与x点积
huffman_x = tf.einsum("ab,b->a", huffman_param, x) # [code_len]
# 获取每个结点是左结点还是右结点
tem_label = tf.squeeze(self.huffman_choice(tem_label), axis=-1) # [code_len]
# 左结点:sigmoid(-WX),右结点sigmoid(WX)
l = tf.sigmoid(tf.einsum("a,a->a", huffman_x, tem_label)) # [code_len]
l = tf.math.log(l)
loss -= tf.reduce_sum(l)
当使用模型对文本进行分类的时候,层次softmax也有其优点。
其中表示结点,是的父结点。
如上计算公式,每个结点的概率,都是根结点到当前结点路径上所有结点的概率乘积,这也就导致了每个结点的概率,一定小于其父结点的概率,那选择最优类别的时候,通过深度优先遍历,计算叶子结点概率,并保存最大概率,在遍历过程中可以丢弃概率小于当前最大概率的分支。基于此,模型的预测代码为:
def predict_one(self, x, huffman_tree: HuffmanTree):
x = self.embedding(x) # [context_len, emb_dim]
x = tf.reduce_sum(x, axis=-2) # [emb_dim]
# 使用huffman树做分类
ps = {}
ps[0] = 1.0
maxp, resultw = 0, 0
for w, code in huffman_tree.word_code_map.items():
index, curp = 0, 1.0
for c in code:
left_index = huffman_tree.nodes_list[index]
if left_index not in ps.keys():
param = tf.squeeze(self.huffman_params(np.array([index])))
p = tf.sigmoid(tf.einsum("a,a->", param, x))
p = p.numpy()
ps[left_index] = 1 - p
ps[left_index + 1] = p
index = left_index + c
curp *= ps[index]
if curp < maxp: break
if curp > maxp:
maxp = curp
resultw = w
return resultw, maxp
ngram特征
fasttext分类模型与CBOW最大的不同,则是使用了ngram特征,CBOW丢弃了词序特征,但如果精确地使用词序特征会让计算复杂度提高很多,所以fasttext中使用ngram特征作为附加特征来获取局部词序特征信息。具体的,分类中的ngram特征是将连续n个词作为一个特征添加到模型中,但是ngram的数量巨大,为了减少内存消耗,模型使用hash技巧,将具有同样hash值的ngram视为同一个特征。在复现过程中,为了简单,直接使用的python自带的hash函数,相关ngram特征获取方式以及hash方式如下:
def _get_ngram(self, alist, is_train=True):
# 获取alist中包含的ngram特征
result, l = set(), len(alist)
for n in self.ngram:
for i in range(l - n + 1):
w = "".join(alist[i:i + n])
result.add(w)
if is_train:
# 如果是训练阶段,则将ngram特征添加到相应map中
if self.is_embedding:
self.ngram_num_map[w] = self.ngram_num_map.get(w, 0) + self.word_num_map[alist[1:-1]]
else:
self.ngram_num_map[w] = self.ngram_num_map.get(w, 0) + 1
return result
def reduce_ngram_num_by_hash(self):
# 如果ngram特征数量大于制定数量,则让具有同样hash值的ngram特征指向同一个表示向量
for w, v in self.ngram_num_map.items():
if v >= self.min and w not in self.ngram2id_map.keys():
self.ngram2id_map[w] = len(self.ngram2id_map) + self.voc_size
if len(self.ngram2id_map) > self.ngram_num:
idmap = {}
for w in self.ngram2id_map.keys():
h = abs(hash(w))
h = h % self.ngram_num # 用hash值的最后几位作为新hash值
if h not in idmap.keys():
idmap[h] = len(idmap) + self.voc_size
self.ngram2id_map[w] = idmap[h]
论文结果
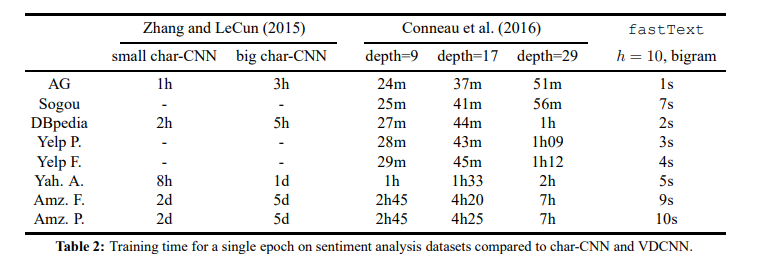
如下面两图所示,fasttext在许多文本分类任务上,都有不错的精度,且速度上会比其他模型快很多很多。下图只显示了添加了2gram特征的情况,论文中也有实验,在Sogou等数据集上,使用3gram特征可以进一步提高准确性;同样的,论文也实验了不同维度(下图中特征是10维)对文本分类效果的影响,一般来说,维度越大效果越好(论文中比较了200维跟50维的效果)。
文本表示
【Enriching Word Vectors with Subword Information】论文提出了一种文本表示模型fasttext。类似wod2vec等模型,在学习词表示的时候都忽略了词的形态特征(如词由哪些结构组成),这就对那些词汇量大和生僻词多的语言不友好,也难以处理oov的词语。而论文中提出的fasttext模型,则使用了subword特征(字符级别的ngram),每一个subword都会学一个表示,最终的词向量,由该词所有的subword向量的和来表示。
模型结构
fasttext文本表示模型,是基于word2vec的skip-gram进行扩展,添加了subword特征。为了提高训练速度,模型也使用了负采样的方式,根据之前文章【NLP重铸篇之Word2vec】,负采样的loss如下:
这是skip-gram结构的负采样loss,其中表示输入向量,表示正样本索引,表示负采样的索引,表示索引为i的词向量,表示索引为i的输出参数向量,s是得分函数。
同样的,更多关于skip-gram结构与负采样内容,可参考【NLP重铸篇之Word2vec】,下面给出前向传播的代码:
def call(self, inputs, training=None, mask=None):
# x:[context_len]
# huffman_label: [label_size, code_len]
# huffman_index: [label_size, code_len]
# y : [label_size]
# negative_index: [negatuve_num]
x, huffman_label, huffman_index, y, negative_index = inputs
x = self.embedding(x) # [context_len, emb_dim]
x = tf.reduce_sum(x, axis=-2) # [emb_dim]
loss = 0
# 负采样loss计算
if self.is_negative:
y_param = self.negative_params(y) # [label_size, emb_dim]
negative_param = self.negative_params(negative_index) # [negative_num, emb_dim]
y_dot = tf.einsum("ab,b->a", y_param, x) # [label_size]
y_p = tf.math.log(tf.sigmoid(y_dot)) # [label_size]
negative_dot = tf.einsum("ab,b->a", negative_param, x) # [negative_num]
negative_p = tf.math.log(tf.sigmoid(-negative_dot)) # [negative_num]
l = tf.reduce_sum(y_p) + tf.reduce_sum(negative_p)
loss -= l
return loss
subword特征
每一个词都可以被表示为一组字符级别的ngram集合,为了区分词的开头和结尾,会在词的前后添加"<"和">"两个字符,同时也会将整个词添加到ngram集合中去。举个例子,如果词为“自然语言”,n为3,此时字符ngram为:<自然、自然语、然语言、语言>、<自然语言>。需要注意的事,“<自然语言>”跟“自然语言”是两个不同的token,前面是一个整词,后面是一个词中的4gram特征。添加了subword特征,改变了skip-gram的输入(从一个变成多个),那得分函数也有所改变,如下:
其中表示词w的字符ngram的索引集合,表示索引为g的向量表示,表示索引为c的输出参数向量。跟分类模型类似,这里也会使用hash函数,将具有同样hash值的ngram特征用同一个向量表示。在训练完成后,每个词的词向量,则由该词的所有ngram特征向量之和来表示,对于oov的词,类似的也用该词存在的ngram向量之和表示。论文中,ngram的范围是3-6。
subword的获取方式以及hash方式与上面ngram一致,fasttext词向量尤其是某些oov词语向量的获取方式如下:
# 获取词向量(模型训练完之后)
if self.is_embedding:
self.embeddings = self.model.embedding.embeddings.numpy()
self.word_embeddings = []
self.ngram_embeddings = {v: self.embeddings[v] for v in self.ngram2id_map.values()}
for k, v in self.word_map.items():
ngrams = self.w2ngram_map[k]
ngrams.append(v)
nemb = [self.embeddings[n] for n in ngrams]
emb = np.mean(nemb, axis=0)
self.word_embeddings.append(emb)
self.word_embeddings = np.array(self.word_embeddings)
norm = np.expand_dims(np.linalg.norm(self.word_embeddings, axis=1), axis=1)
self.word_embeddings /= norm # 归一化
def get_word_emb(self, words):
# 获取词向量,当词不存在时用该词的ngram之和表示
word_emb = [] # [word_len, embedding]
for w in words:
if w in self.word_map.keys():
word_emb.append(self.word_embeddings[self.word_map[w]])
else:
ngrams = self._get_ngram("<" + w + ">", False)
indexs = [self.ngram2id_map[n] for n in ngrams if n in self.ngram2id_map.keys()]
tem_emb = [self.ngram_embeddings[i] for i in indexs]
emb = np.mean(tem_emb, axis=0)
norm = np.linalg.norm(emb)
emb /= norm
word_emb.append(emb)
return word_emb
论文结果

如上图所示,论文对比了word2vec跟fasttext模型在各种语言上,人类判断跟模型计算的相似度得分的相关性,其中sg与cbow分别表示word2vec中的skip-gram与CBOW结构的模型,sisg-与sisg都是fasttext模型,sisg-在处理oov词的时候直接使用null的向量表示,sisg则使用该词的ngram向量之和来表示,可看出sisg的结果基本都优于其他结果,侧面证明了subword带来的有效信息。 上图的结果,则显示了词向量在不同语言上语义跟句法任务的准确性,可以看出fasttext对大部分语言的句法任务都有显著提升。
上图的结果,则显示了词向量在不同语言上语义跟句法任务的准确性,可以看出fasttext对大部分语言的句法任务都有显著提升。
fasttext与word2vec结果比较
根据本文复现的fasttext文本表示模型,以及【NLP重铸篇之Word2vec】中复现的word2vec模型,基于THUCNews文本分类验证数据集cnews.val.txt的5000条文本进行训练,得到的词向量部分展示结果如下图所示:
从上图可以看出,fasttext的结果会偏向于具有相似的subword的词,比如基金跟政策两个词的相似词,fasttext的结果会偏向包含词本身的结果,word2vec则不是;另外对于出现频率较低的词,但这个词的subword出现频率不低,则fasttext的效果略好,如上海大学这个词;而对于oov的词,word2vec是给不出结果的,fasttext则能给出相对还可以的结果,如南京大学这个词。
参考
【1】基于tf2的word2vec模型复现:https://github.com/wellinxu/nlp_store/blob/master/papers/word2vec.py
【2】基于tf2的fasttext模型复现:https://github.com/wellinxu/nlp_store/blob/master/papers/fasttext.py
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: