
机器学习基础:类别不平衡问题处理方法汇总及实际案例解析
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
作者:GC_AIDM
原文:https://www.cnblogs.com/shenggang/p/12133016.html
一、什么是类不平衡
在分类中经常会遇到:某些类别数据特别多,某类或者几类数据特别少。如二分类中,一种类别(反例)数据特别多,另一种类别(正例)数据少的可怜。如银行欺诈问题,客户流失问题,电力盗窃以及罕见疾病识别等都存在着数据类别不均衡的情况。
二、为什么要对类不平衡进行特殊处理
传统的分类算法旨在最小化分类过程中产生的错误数量。它们假设假阳性(实际是反例,但是错分成正例)和假阴性(实际是正例,但是错分为反例)错误的成本是相等的,因此不适合于类不平衡的数据。
有研究表明,在某些应用下,1∶35的比例就会使某些分类方法无效,甚至1∶10的比例也会使某些分类方法无效。如果数据存在严重的不平衡,预测得出的结论往往也是有偏的,即分类结果会偏向于较多观测的类。
三、提升不平衡类分类准确率的方法
提升不平衡类分类准确率的方法有三大类:采样、阈值移动、调整代价或权重。
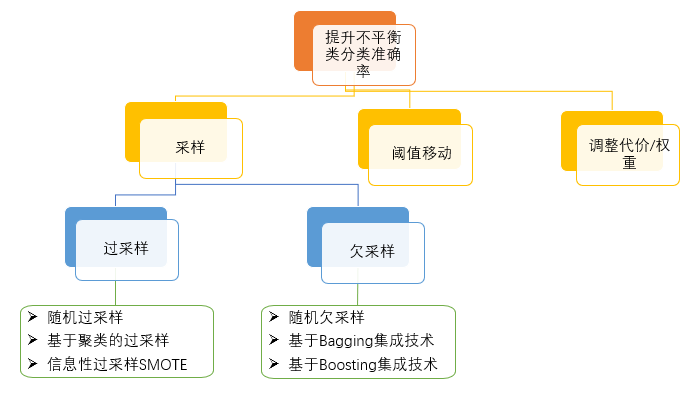
1、采样
1.1 过采样
过采样基本思想就是通过改变训练数据的分布来消除或减小数据的不平衡。过采样有随机过采样、基于聚类的过采样、信息性过采样(SMOTE)三大类方法。随机过采样:通过增加少数类样本来提高少数类的分类性能 ,最简单的办法是随机复制少数类样本。
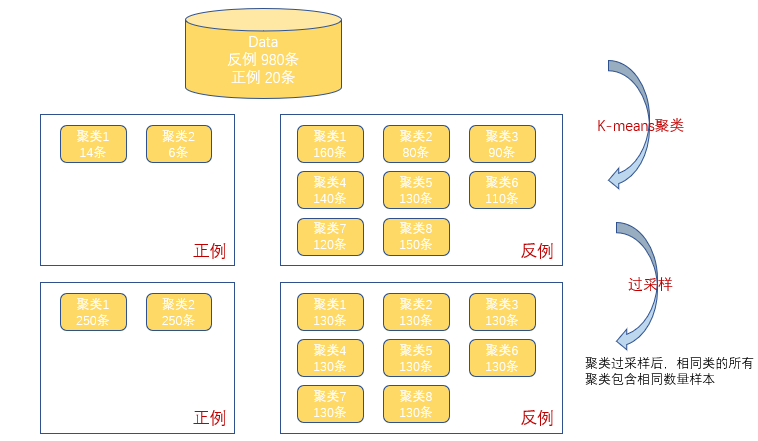
基于聚类的过采样:K-Means聚类算法独立地被用于少数和多数类实例,之后,每个聚类都过采样使得相同类的所有聚类有着同样的实例数量。
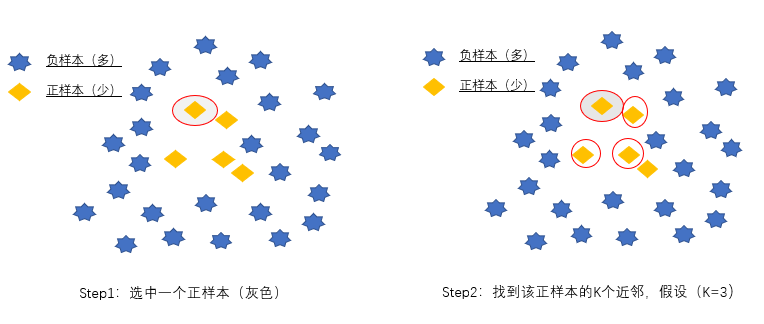
**信息性过采样--SMOTE **
利用KNN技术,对于少数类样本a, 随机选择一个最近邻的样本b, 然后从a与b的连线上随机选取一个点c作为新的少数类样本。
SMOTE有时能提升分类准确率,有时不能,甚至可能因为构建数据时放大了噪声数据导致分类结果变差,这要视具体情况而定。
1.2 欠采样
欠采样方法通过减少多数类样本来提高少数类的分类性能。随机欠采样:通过随机地去掉一些多数类样本来减小多数类的规模。
集成技术:欠采样中的算法集成技术是利用集成学习机制,将反例划分为若干个集合供不同学习器使用,这样对每个学习器来看都进行了欠采样,但在全局来看却不会丢失重要信息,一般适用于数据集足够大的情况。这里的集成技术可以分为基于Bagging的方法和基于Boosting的方法。
2、 阈值移动法
许多模型的输出类别是基于阈值的,例如逻辑回归中小于0.5的为反例,大于则为正例。在数据不平衡时,默认的阈值会导致模型输出倾向于类别数据多的类别。阈值移动是通过改变决策阈值来偏重少数类。
3 、调整代价或权重法
通过调整不同类类的代价或权重来偏重少数类以改进分类性能。
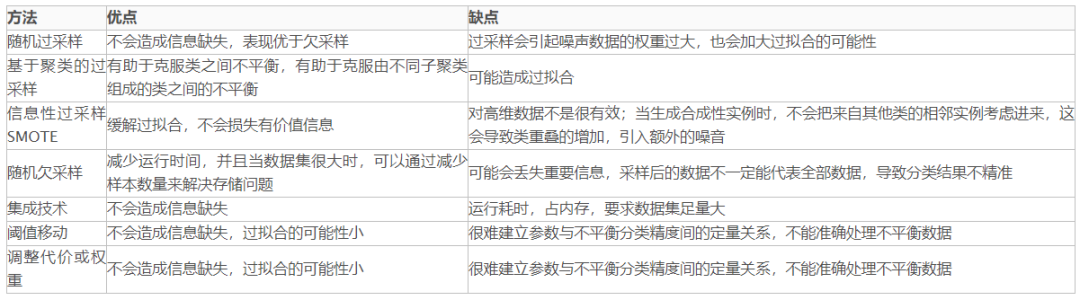
四、方法评价
五、实际案例
案例:信用卡欺诈
案列介绍:数据集由欧洲持卡人于2013年9月使用信用卡进行交易的数据。此数据集显示两天内发生的交易,其中284,807笔交易中有492笔被盗刷。数据集非常不平衡,被盗刷占所有交易的0.172%。
由于保密问题,数据只包含作为PCA转换结果的数字输入变量V1,V2,... V28,没有用PCA转换的唯一特征是“时间”和“量”。特征'时间'包含数据集中每个事务和第一个事务之间经过的秒数,特征“金额”是交易金额,特征'类'是响应变量,如果发生被盗刷,则取值1,否则为0。
尝试了多种方法,以此数据案例结果来看,法二XGboost模型比较好,当然最优结果不止局限于此,大家可以尝试其它方法优化结果法一:SMOTE算法、LR模型以及阈值移动的方法
import pandas as pdimport numpy as npfrom sklearn.metrics import recall_score,confusion_matrixfrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import KFoldimport itertoolsimport warningswarnings.filterwarnings("ignore")#读取信用卡数据data = pd.read_csv("creditcard.csv",encoding='utf-8')# 数据归一化from sklearn.preprocessing import StandardScalerdata['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))#数据划分成LABEL列和特征列X_data = data.drop(['Class','Time','Amount'],axis = 1) #删除LABEL及其它非特征列y = data.Class#查看样本类别分布from collections import Counterprint(Counter(y))#更直观地,可以绘制饼图import matplotlib.pyplot as pltplt.axes(aspect='equal')counts = data.Class.value_counts() #统计LABEL中各类别的频数plt.pie(x = counts, #绘制数据labels = pd.Series(counts.index).map({0:'normal',1:'cheat'}), #添加文字标签autopct='%.2f%%' #设置百分比的格式,这里保留两位小数)plt.show() #显示图形#数据划分成训练集和测试集from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(X_data,y,test_size=0.3)#==================解决类别不均衡问题,SMOTE算法==========================from imblearn.over_sampling import SMOTEsm = SMOTE(random_state=123)X_train_sm, y_train_sm = sm.fit_sample(X_train, y_train)#查看过采样之后的类别分布print(Counter(y_train_sm))#========================逻辑回归模型=====================================X_train_sm = pd.DataFrame(X_train_sm)y_train_sm = pd.DataFrame(y_train_sm)# 指定不同的惩罚系数,利用交叉验证找到最合适的参数,打印每个结果def printing_Kfold_scores(X_train_data,Y_train_data):fold = KFold(5,shuffle=False)print(fold)c_param_range = [0.01,0.1,1,10,100]results_table = pd.DataFrame(index=range(len(c_param_range),2),columns=['C_Parameter','Mean recall score'])results_table['C_Parameter'] = c_param_rangej=0for c_param in c_param_range:print('c_param:',c_param)recall_accs = []for iteration,indices in enumerate(fold.split(X_train_data)):lr = LogisticRegression(C = c_param, penalty = 'l1')lr.fit(X_train_data.iloc[indices[0],:],Y_train_data.iloc[indices[0],:].values.ravel())Y_pred = lr.predict(X_train_data.iloc[indices[1],:].values)recall_acc = recall_score(Y_train_data.iloc[indices[1],:].values,Y_pred)recall_accs.append(recall_acc)print ('Iteration:',iteration,'recall_acc:',recall_acc)print ('Mean recall score',np.mean(recall_accs))results_table.loc[j,'Mean recall score'] = np.mean(recall_accs)print('----------')j+=1print(type(results_table['Mean recall score']))print(results_table['Mean recall score'])results_table['Mean recall score'] = results_table['Mean recall score'].astype('float64')best_c = results_table.loc[results_table['Mean recall score'].idxmax()]['C_Parameter']print ('best_c is :',best_c)return best_c#绘制混淆矩阵图def plot_confusion_matrix(cm, classes,title='Confusion matrix',cmap=plt.cm.Blues):plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=0)plt.yticks(tick_marks, classes)thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.tight_layout()plt.ylabel('True label')plt.xlabel('Predicted label')best_c = printing_Kfold_scores(X_train_sm,y_train_sm)lr = LogisticRegression(C = best_c, penalty = 'l2')lr.fit(X_train_sm,y_train_sm.values.ravel())y_pred = lr.predict_proba(X_test.values)#==============================阈值移动方法=========================#默认阈值一般为0.5thresholds = [0.5,0.6,0.7,0.8,0.9]plt.figure(figsize=(10,10))m = 1for i in thresholds:y_test_predictions_high_recall = y_pred[:,1] > iplt.subplot(3,3,m)m += 1cnf_matrix = confusion_matrix(y_test,y_test_predictions_high_recall)np.set_printoptions(precision=2)print ("Recall:{}".format(cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1])))class_names = [0,1]plot_confusion_matrix(cnf_matrix, classes=class_names, title='Threshold >= %s'%i)混淆矩阵如下所示
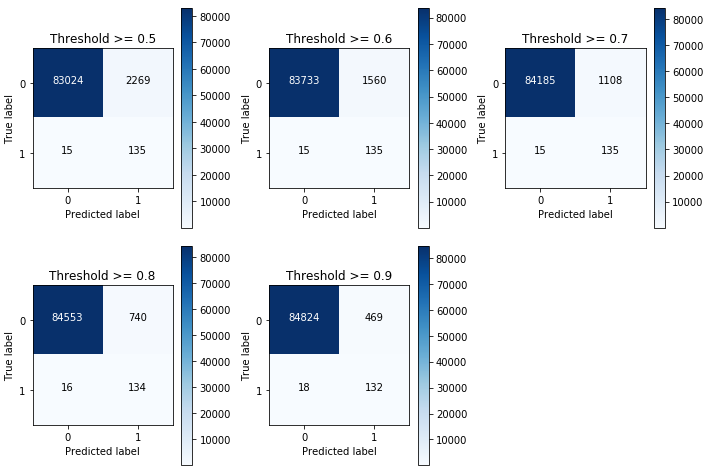
法二:算法集成技术XGBoost
import pandas as pdimport numpy as npfrom sklearn.metrics import accuracy_score,classification_report,roc_curve,auc,confusion_matriximport itertoolsimport matplotlib.pyplot as pltimport warningswarnings.filterwarnings("ignore")#读取信用卡数据data = pd.read_csv("creditcard.csv",encoding='utf-8') #文末附有数据# 数据归一化from sklearn.preprocessing import StandardScalerdata['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))data = data.drop(['Time','Amount'],axis = 1)#数据划分成LABEL列和特征列X_data = data.drop(['Class'],axis = 1) #删除LABEL及其它非特征列y = data.Class#查看样本类别分布from collections import Counterprint(Counter(y))# Counter({0: 37027, 1: 227})#更直观地,可以绘制饼图plt.axes(aspect='equal')counts = data.Class.value_counts() #统计LABEL中各类别的频数plt.pie(x = counts, #绘制数据labels = pd.Series(counts.index).map({0:'normal',1:'cheat'}), #添加文字标签autopct='%.2f%%' #设置百分比的格式,这里保留两位小数)plt.show() #显示图形from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(X_data,y,test_size=0.3,random_state=123)Train,Test = train_test_split(data,test_size=0.3,random_state=123)#=========================XGBoost模型分类======================import xgboostxgb = xgboost.XGBClassifier() #添加系数scale_pos_weight=10或100即为调整类别的权重,与阈值移动效果类似# 使用非平衡的训练数据集拟合模型xgb.fit(X_train,y_train)# 基于拟合的模型对测试数据集进行预测y_pred = xgb.predict(X_test)# 返回模型的预测效果print('模型的准确率为:\n',accuracy_score(y_test, y_pred))print('模型的评估报告:\n',classification_report(y_test, y_pred))# 计算用户流失的概率值y_score = xgb.predict_proba(X_test)[:,1]fpr,tpr,threshold = roc_curve(y_test, y_score)# 计算AUC的值roc_auc = auc(fpr,tpr)print('ROC curve (area = %0.2f)' % roc_auc)y_pred_proba = xgb.predict_proba(X_test) #之后阈值移动要用到#绘制混淆矩阵图def plot_confusion_matrix(cm, classes,title='Confusion matrix',cmap=plt.cm.Blues):plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=0)plt.yticks(tick_marks, classes)thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.tight_layout()plt.ylabel('True label')plt.xlabel('Predicted label')#==============================阈值移动方法===================================#默认阈值一般为0.5thresholds = [0.45,0.47,0.49,0.51,0.53,0.55]plt.figure(figsize=(10,10))m = 1for i in thresholds:y_test_predictions_high_recall = y_pred_proba[:,1] > iplt.subplot(3,3,m)m += 1cnf_matrix = confusion_matrix(y_test,y_test_predictions_high_recall)np.set_printoptions(precision=2)print ("Recall:{}".format(cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1])))class_names = [0,1]plot_confusion_matrix(cnf_matrix, classes=class_names, title='Threshold >= %s'%i)
混淆矩阵如下所示
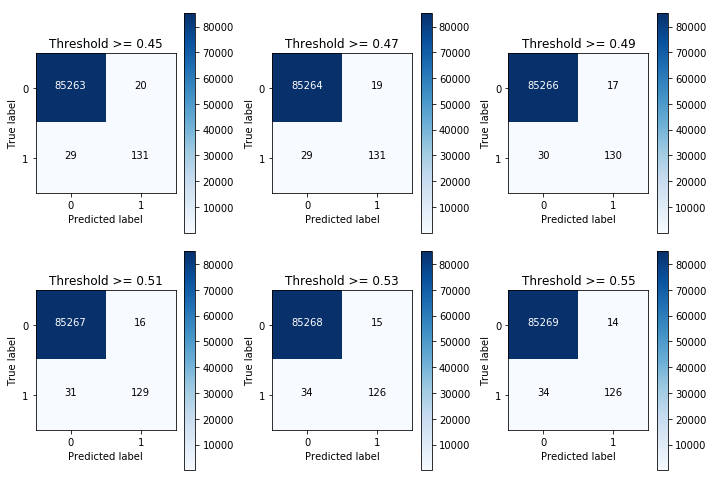
参考资料:
https://github.com/wangjiang0624/Note/blob/master/MachineLearning/分类类别不平衡.md
https://www.jiqizhixin.com/articles/2017-03-20-8
https://www.kaggle.com/mlg-ulb/creditcardfraud
—END— 如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「hych666」,欢迎添加我的微信,更多精彩,尽在我的朋友圈。 ↓扫描二维码添加好友↓ 推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
