
【机器学习基础】机器学习中类别变量的编码方法总结
Author:louwill
Machine Learning Lab
from sklearn import preprocessingle = preprocessing.LabelEncoder()le.fit(['undergraduate', 'master', 'PhD', 'Postdoc'])le.transform(['undergraduate', 'master', 'PhD', 'Postdoc'])
array([3, 2, 0, 1], dtype=int64)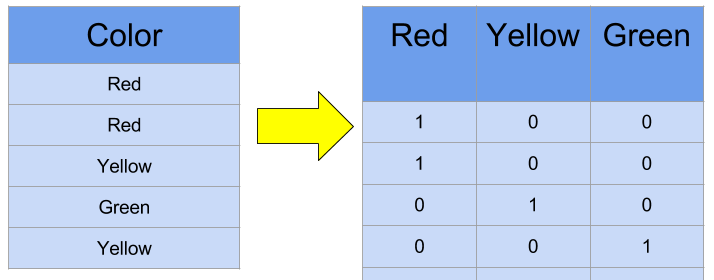
import pandas as pddf = pd.DataFrame({'f1':['A','B','C'],'f2':['Male','Female','Male']})df = pd.get_dummies(df, columns=['f1', 'f2'])df
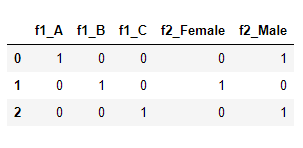
from sklearn.preprocessing import OneHotEncoderenc = OneHotEncoder(handle_unknown='ignore')X = [['Male', 1], ['Female', 3], ['Female', 2]]enc.fit(X)enc.transform([['Female', 1], ['Male', 4]]).toarray()
array([[1., 0., 1., 0., 0.],[0., 1., 0., 0., 0.]])
### 该代码来自知乎专栏:### https://zhuanlan.zhihu.com/p/40231966from sklearn.model_selection import KFoldn_folds = 20n_inner_folds = 10likelihood_encoded = pd.Series()likelihood_coding_map = {}# global prior meanoof_default_mean = train[target].mean()kf = KFold(n_splits=n_folds, shuffle=True)oof_mean_cv = pd.DataFrame()split = 0for infold, oof in kf.split(train[feature]):print ('==============level 1 encoding..., fold %s ============' % split)inner_kf = KFold(n_splits=n_inner_folds, shuffle=True)inner_oof_default_mean = train.iloc[infold][target].mean()inner_split = 0inner_oof_mean_cv = pd.DataFrame()likelihood_encoded_cv = pd.Series()for inner_infold, inner_oof in inner_kf.split(train.iloc[infold]):print ('==============level 2 encoding..., inner fold %s ============' % inner_split)# inner out of fold meanoof_mean = train.iloc[inner_infold].groupby(by=feature)[target].mean()# assign oof_mean to the infoldlikelihood_encoded_cv = likelihood_encoded_cv.append(train.iloc[infold].apply(lambda x : oof_mean[x[feature]]if x[feature] in oof_mean.indexelse inner_oof_default_mean, axis = 1))inner_oof_mean_cv = inner_oof_mean_cv.join(pd.DataFrame(oof_mean), rsuffix=inner_split, how='outer')inplace=True)inner_split += 1oof_mean_cv = oof_mean_cv.join(pd.DataFrame(inner_oof_mean_cv), rsuffix=split, how='outer')=oof_default_mean, inplace=True)split += 1print ('============final mapping...===========')likelihood_encoded = likelihood_encoded.append(train.iloc[oof].apply(lambda x: np.mean(inner_oof_mean_cv.loc[x[feature]].values)if x[feature] in inner_oof_mean_cv.index=1))
lgb_train = lgb.Dataset(train2[features], train2['total_cost'],categorical_feature=['sex'])
Label Encoding
类别特征内部有序
One-hot Encoding
类别特征内部无序
类别数值<5
Target Encoding
类别特征内部无序
类别数值>5
模型自动编码
LightGBM
CatBoost
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群704220115。
加入微信群请扫码进群(如果是博士或者准备读博士请说明):
评论