
金融风控评分卡建模全流程!
知乎丨https://zhuanlan.zhihu.com/p/148102950
本文摘要
本文将带领读者一起进行完整的建模全流程,了解银行风控是如何做的。并提供kaggle代码。首先讲述评分卡的分类、优缺点。接下来,结合完整的可以马上运行的代码,中间穿插理论,来讲解评分卡的开发流程。最后,把方法论再梳理一次,让读者在了解全流程后,在概念上理解再加深。
本文还提供了完整的全流程代码,读者打开https://www.kaggle.com/orange90/credit-scorecard-example,结合代码来读本文,会理解更深。
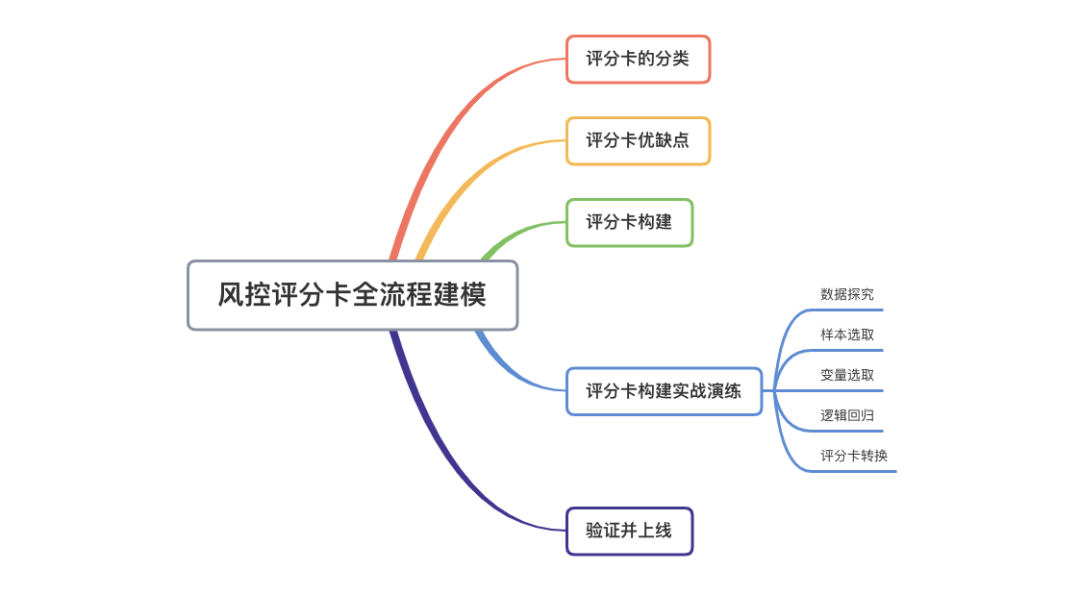
一、评分卡的分类
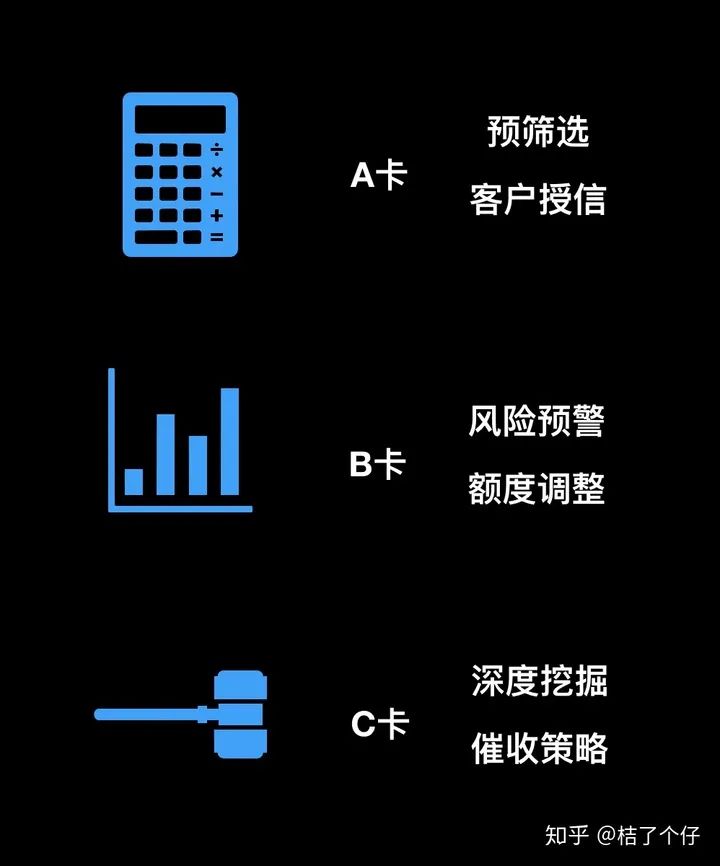
在金融风控领域,无人不晓的应该是评分卡(scorecard), 无论信用卡还是贷款,都有”前中后“三个阶段。根据风控时间点的”前中后”,一般风评分卡可以分为下面三类:
A卡(Application score card)。目的在于预测申请时(申请信用卡、申请贷款)对申请人进行量化评估。 B卡(Behavior score card)。目的在于预测使用时点(获得贷款、信用卡的使用期间)未来一定时间内逾期的概率。 C卡(Collection score card)。目的在于预测已经逾期并进入催收阶段后未来一定时间内还款的概率。
美国fico公司算是评分卡的始祖,始于 20世纪六十年代。Fico的评分卡的示例如下(这是个贷前评分卡,也就是A卡):
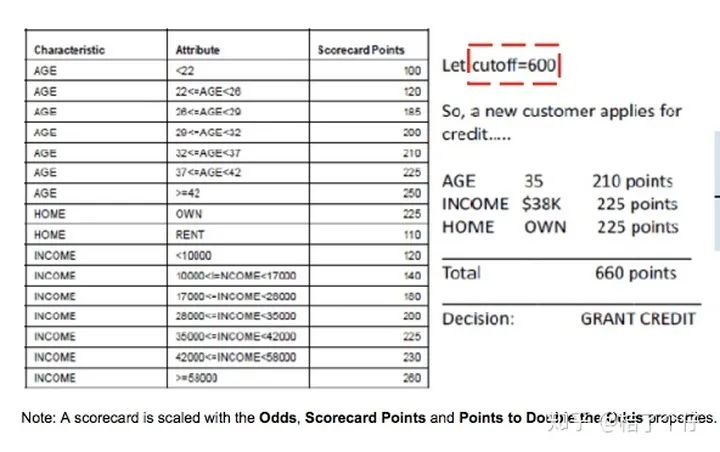 可以看到,这里有三个因素,第一个是年龄AGE,第二个是收入段INCOME,第三个是住宅HOME是租的还是买的。当总分超过600分,就给与授信额度。这种评分卡,操作简单,就算是个小学生都能算出风险值。
可以看到,这里有三个因素,第一个是年龄AGE,第二个是收入段INCOME,第三个是住宅HOME是租的还是买的。当总分超过600分,就给与授信额度。这种评分卡,操作简单,就算是个小学生都能算出风险值。
二、评分卡优缺点
评分卡的好处还是很明显的:
易于使用。业务人员在操作时,只需要按照评分卡每样打分然后算个总分就能操作,不需要接受太多专业训练 直观透明。客户和审核人员都能知道看到结果,以及结果是如何产生的。 应用范围广。我们最熟悉的,莫过于支付宝的芝麻信用分,又或者知乎盐值(虽然知乎盐值不是评估金融风险的,但也算是评分卡的应用之一)
但是,随着信贷业务规模不断扩大,对风控工作准确率的要求也逐渐提升。这时候静态评分卡的弱点就暴露了:
利润的信息维度不高。简单是优点,但在日益增长的数据前,就变成缺点。有着大量数据资源却使用有限,造成数据资源的浪费。 当信息维度高时,评分卡建模会变得非常困难。(你看,本文的评分卡只涉及十个特征,就这么长一篇了) 某些不重要的特征,在另一些时刻会变得重要。例如在疫情期间,和收入相关的特征重要度会上升。
当然,以上的缺点主要限于静态评分卡,就算拿纸打勾计算分数那种,例如上面那个FICO的评分卡。有些积分,由于背后支撑的模型可以动态调整相关参数的权重,这时候就生成一个动态评分卡。但这种情况可以看成对机器学习模型做的可解释性解析。
三、评分卡构建
那么评分卡是如何构建的呢?一般包含下面六个步骤
数据探究。研究数据都包含哪些信息。 样本选取。选取一定时间周期内该平台上的信贷样本数据,划分训练集和测试集。 变量选取。也就是特征筛选。需要一定的业务理解。一般这部分费时较久 逻辑回归。根据筛选后的特征,构建逻辑回归模型。 评分卡转换。根据一定的公式转换。 验证并上线。验证评分卡效果,并上线持续监测
是不是看起来有点抽象呢?真正的干货马上来,赶紧去上个厕所,冲好咖啡,因为下面的干货太满了!
四、评分卡构建实战演练
看上面抽象的表述看累了?实际操作马上来了。
我们用的数据是每个搞风控的人都熟悉的“Give Me Some Credit"数据集。本节会按照列出的六个步骤带你领略评分卡实际构建过程。
数据集地址:https://link.zhihu.com/?target=https%3A//www.kaggle.com/c/GiveMeSomeCredit/overview
最终示例代码:https://link.zhihu.com/?target=https%3A//www.kaggle.com/orange90/credit-scorecard-example
4.1 数据探究
我们加载kaggle提供的数据集,先看看dataframe长啥样:
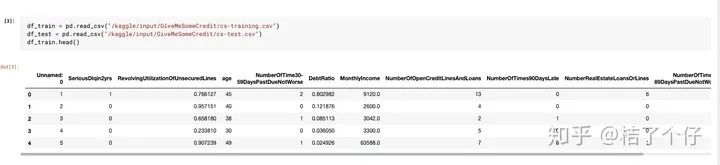
太长了,不容易看,我们看看摘要好了。
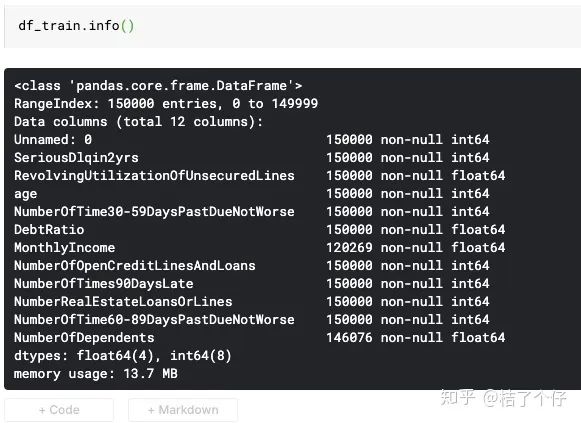
可以看到有些column里面是有null value的。我们看看有多少null value:
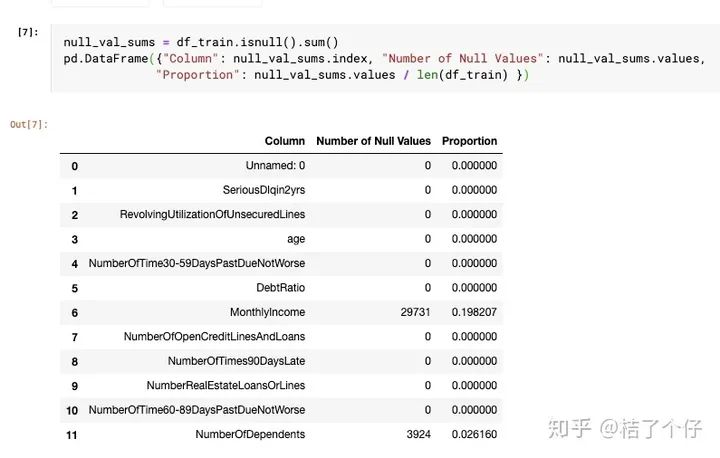
可以看到MonthlyIncome和NumberOfDependents有一些空值。在建模前我们需要对其进行处理。
对null值处理有很多策略,例如填中位数,填平均数,甚至拿个模型去预测都行。由于收入差距可能很大,MonthlyIncome填中位数相对合理。NumberOfDependents也可以填中位数,或者平均数,但平均数会变成小数,所以还是取中位数。
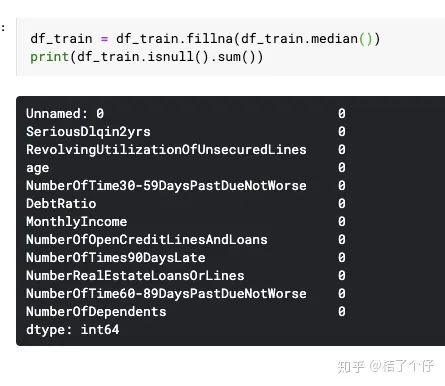
可以看到,fillna后就没问题了。
其中,变量SeriousDlqin2yrs是我们模型的label。我们可以说1为坏,0为好。这个变量是意思是Serious Delinquent in 2 year,也就是2年内发生严重逾期,其中”严重“定义为逾期超过90天。也就是说。例如你2018年1月1号开卡,每个月1号是还款日。例如你2019年4月1号是你的还款日,然后你在7月1号前都没还钱,那这时候逾期就超过90天了,你的数据标签就为1。
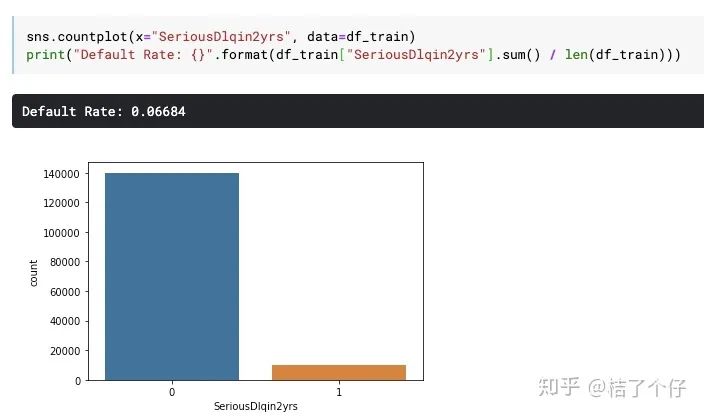
可以看到bad rate是0.06684。意味着我们在建模前,也许需要对数据做一个平衡(balancing)。
除此之外,其他列的定义如下(定义来自原数据集的Data Dictionary.xls)

为了方便阅读,关于其他变量我就不在本文一一探索了,感兴趣的读者可以到https://www.kaggle.com/orange90/credit-scorecard-example里慢慢看,这里有详细的EDA。
4.2 样本选取
对于金融机构内部,我们需要将连续的数据分为训练集和测试集。例如我目前有2017-01-01到2019-12-31的数据,我可以把2017年1月,2月和2019年11月,12月作为测试集,2017-03-01到2019-10-31作为训练集。这么做的话,可以检测模型跨时间的稳健性。

上面仅为个人经验,不构成本节实操的一部分。由于cs-test.csv并不包含标签,所以没法拿来当验证,我们从cs-training中将提取70%作为训练集,另外30%作为验证集。这个分割会在第四步——逻辑回归前进行。

4.3 变量选取
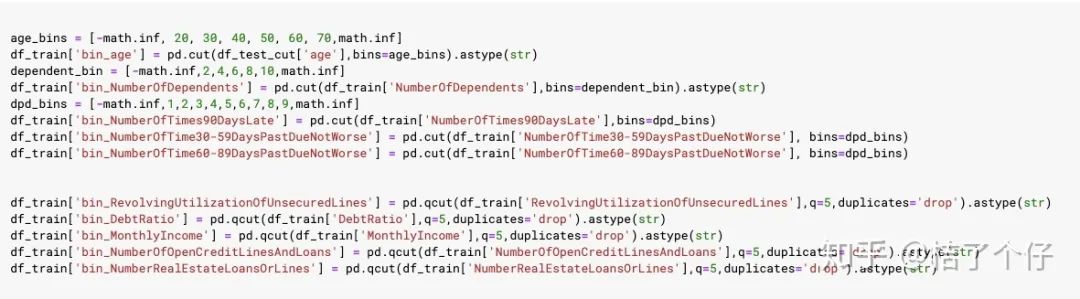
评分卡里叫变量,在建模时,我们叫特征。但在评分卡里,我们需要对变量进行分箱(binning),效果如图二的fico评分卡。分箱怎么做的呢?
我有空会做一个专题。这里先简单搞个分箱策略,值比较多的用pandas.qcut,值比较少的用pandas.cut。qcut和cut的区别是,qcut是根据这些值的频率来选择箱子的间隔,以实现尽量每个分箱里的样本一样多。而cut是手动给定分箱阈值。
我们定义需要 qcut的变量:
RevolvingUtilizationOfUnsecuredLines DebtRatio MonthlyIncome NumberOfOpenCreditLinesAndLoans NumberRealEstateLoansOrLines
需要cut的变量,至于cut 的阈值,我就随便给好了:
age NumberOfDependents NumberOfTime30-59DaysPastDueNotWorse NumberOfTimes90DaysLate NumberOfTime60-89DaysPastDueNotWorse
qcut和cut的方法及阈值如下:
在做特征筛选时,我们怎么判断哪些特征有用,哪些特征没啥用呢?特征筛选有多种方法,其中一种是,我们可以计算IV(Information Value)来判断特征对结果的重要度。计算公式如下:
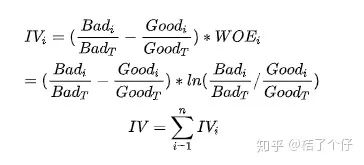
其中WOE(Weight of Evidence) 定义为:
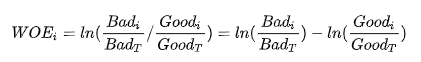
我们写一个计算IV值的函数:

在业界实践中,我们把IV<0.02的看作无效特征,0.02<0.1的为弱效果特征,>0.5为强特征,如下表所示。
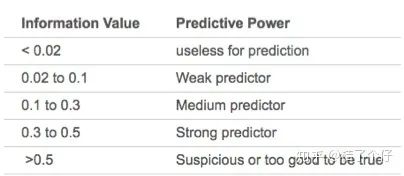
那我们只选择IV值大于0.1的变量吧。计算每个变量的IV值:
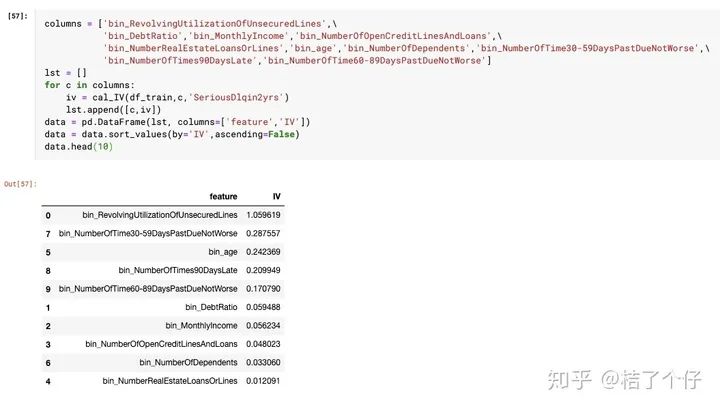
不同分箱会导致IV值不同,但本文是一个baseline模型,所以未对分箱策略做优化。
我们只选择忽略week predictor和unless for prediction的特征,只选择IV值0.1以上的,最后这五个入选
'bin_RevolvingUtilizationOfUnsecuredLines'
'bin_NumberOfTime30-59DaysPastDueNotWorse'
'bin_age'
'bin_NumberOfTimes90DaysLate'
'bin_NumberOfTime60-89DaysPastDueNotWorse'
4.4 逻辑回归
虽然用神经网络或者xgboost等模型效果更好,但多数情况下,银行做评分卡时还是喜欢用逻辑回归,因为:
模型直观,可解释性强,易于理解,变量系数可以与业内知识做交叉验证,更容易让人信服。 易于发现问题。当模型效果衰减的时候,logistic模型能更好的查找原因。
我们定义一个函数cal_WOE,用以把分箱转成WOE值。
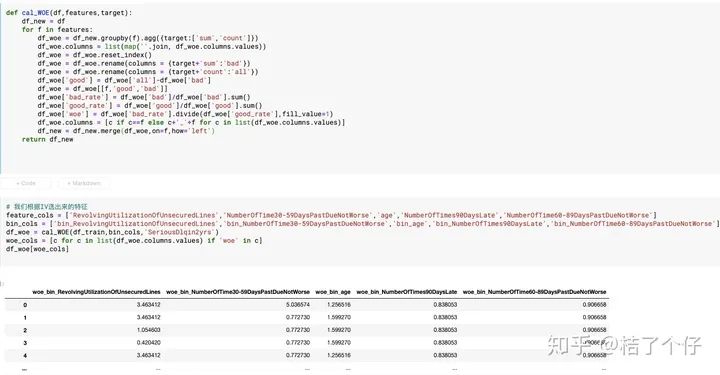
看起来数据应该是可以用了。那现在我们开始用逻辑回归建模吧。
由于数据集的测试样本是没有标签的,所以我们需要从训练集里分一些验证集出来。用train_test_split函数把数据分成70/30两部分

然后跑模型,模型训练非常快,一下子就完了。
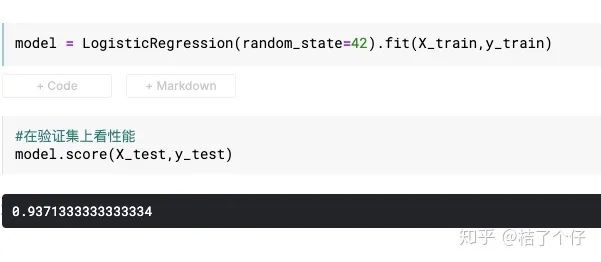
我们来看模型的AUC。业内的经验是,0.80以上就算是可以投入产品线使用的模型。
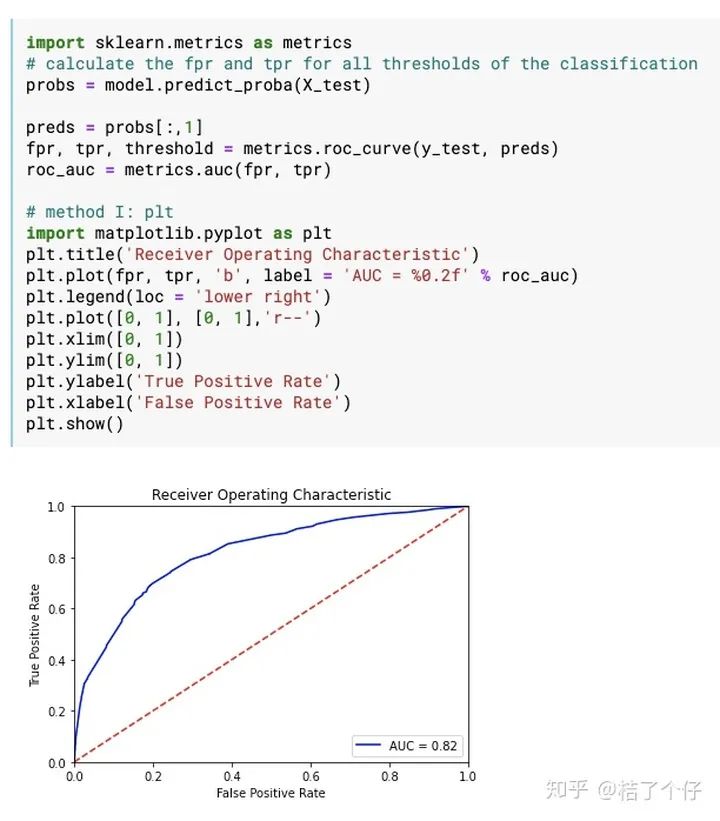
模型的AUC达到还不错的0.82。由于这里使用数据集的sanity比较好,所以也容易出效果。这里插个题外话来讲讲我的工作经验。根据我的开发经验,在客户真实数据上要取得这个AUC还是要花很长时间的,尤其是数据清洗与特征提取就要花90%的时间。
逻辑回归模型这步很简单吧。下面就要讲到评分卡转换了,这一步标志着你的模型要从实验室走向产品线了。
4.5 评分卡转换
这一节的内容是知乎很多文章都没讲清楚的,我首先先讲理论,理论讲完后,我就开始结合案例来讲。
模型训练好后,我们需要把对每个变量的每个分箱(也就是数值段)转换成具体的分值。在讲计算过程前,先来讲点前置知识。
评分卡中不直接用客户违约率p,而是用违约概率与正常概率的比值,称为Odds,即
评分卡会把odds映射成score。为啥不用p直接映射,而用odds?听我道来。
根据逻辑回归原理:
把上述公式变化一下,有
咦,是不是有点思路了?这不就是我们刚才提到的odds吗?现在你懂了吧,因为计算odds可以和逻辑回归无缝结合。所以上面还可以变成
$$ln(odds)=\theta^Tx \tag{5$$
评分卡的背后逻辑是Odds的变动与评分变动的映射(把Odds映射为评分)。我们可以设计这个一个公式
其中A与B是常数,B前面取负号的原因,是让违约概率越低,得分越高。因为实际业务里,分数也高风险越低,当然你也可以设计个风险越低分数越低的评分卡,但风控里还是默认高分高信用低风险。
计算出A、B的方法如下,首先设定两个假设:
基准分。基准分 为某个比率时的得分 。业界某些风控策略基准分都设置为500/600/650。基准分为 PDO(point of double),比率翻番时分数的变动值。假设我们设置为当odds翻倍时,分值减少30。
设置好 后,就能算出A和B。怎么算?首先把 代入公式,有
根据PDO的定义,我们有下面等式:
上面两个式子组成了我们小学就能解的二元一次方程组,把公式(7)的右边替换掉公式(8)左边,可以算出B,从而可以算得A的解。最后A、B的解分别为:,
记住这两个公式,等下实例开始时就会用到。迫不及待想进入实例训练了?稍安勿躁,还有最后一步,就是把分箱映射为分数。
还记得前面举的评分卡例子吗?评分卡里每一个变量的每一个分箱有一个对应分值。前面的 是一个矩阵计算,展开后我们有:
其中变量 等等是出现在最终模型的入模变量。由于所有的入模变量都进行了WOE编码,可以将这些自变量中的每一个都写 的形式,其中 为第 i 个特征的第j 个分箱的WOE值, 是0,1逻辑变量,当 时,代表自特征i 取第 j 个分箱,当 时代表特征i不取第j 个分箱。最终得到评分卡模型:
公式有点抽象?换成图片表示
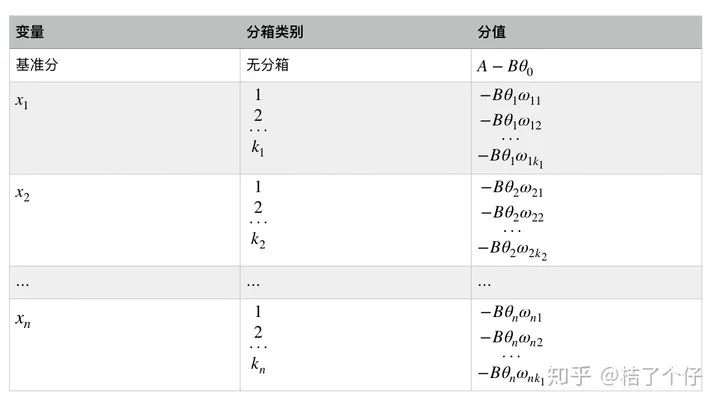
好了,评分卡转换的理论讲完了,现在要开始令人振奋的实例了。
我们定义 为1:1(你也可以试试其他值),基准分为650,PDO为50,代入公式(9)和(10),有
记住这两个值,我会把这两个值代入实例里计算。
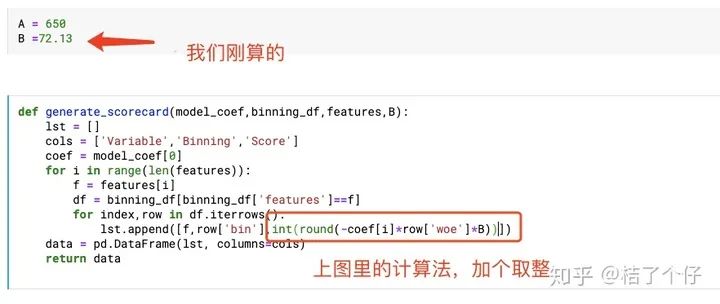
然后评分卡就轻轻松松得到了:
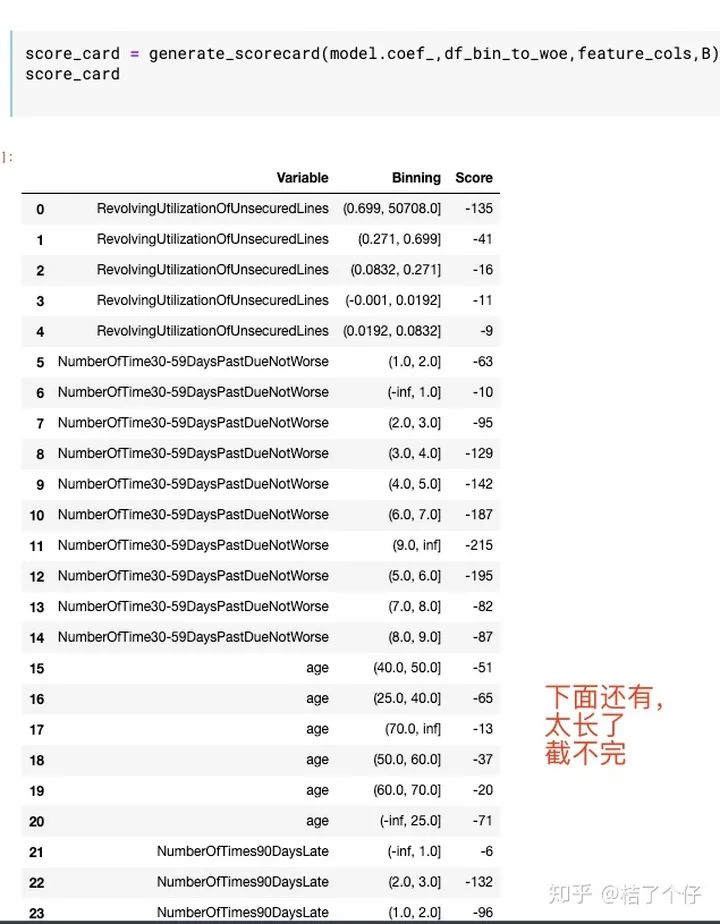
可以看到,总体来说评分符合预期,例如RevolvingUtilizationOfUnsecuredLines越高,给的分数越低。
不过也有的评分并不是完全符合预期,例如NumberOfTime60-89DaysPastDueNotWorse在(8.0, 9.0]段的分数竟然是0,这完全没道理啊!这个问题的出现,和训练集在这个分数段的样本量有关,可能是这个段的数据太少了。解决方法是重新设计分箱策略,不过本文的目的是解释整个流程,做个baseline,这里就不优化了,读者有兴趣的话可以自己研究下如何优化。
五、验证并上线
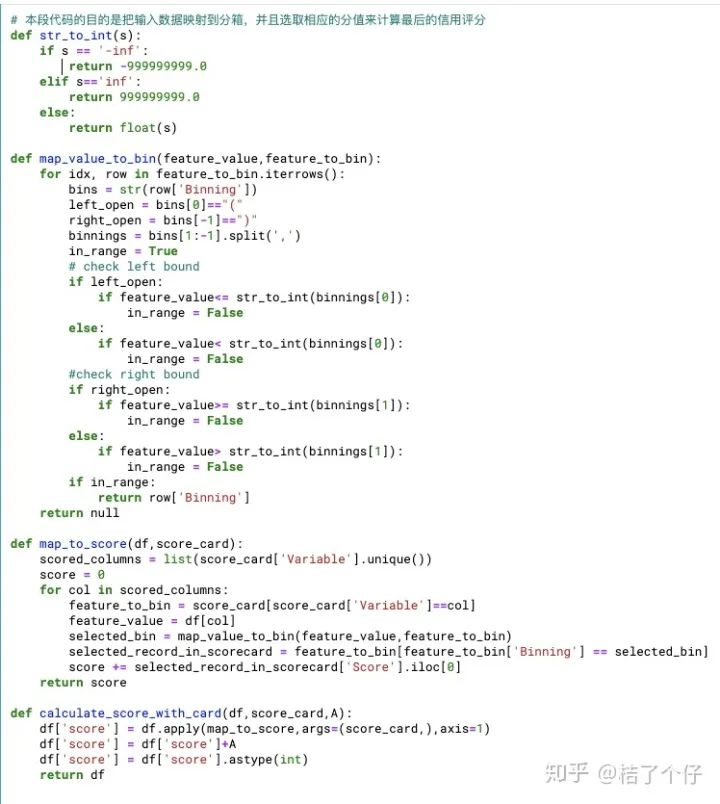
我们写个函数把原始特征的值转换成评分卡里的值。函数名是calculate_score_with_card,也就是下图里的最后一个函数,其他三个函数是辅助函数。
我们随机选取五个好的样本和五个坏的样本,来验证下他们的效果。

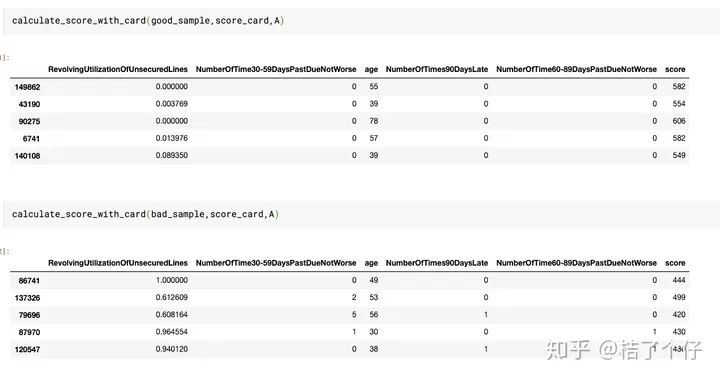
可以看到,好的样本分数评分都比坏样本分数低,说明了评分卡的有效性。例如上面的例子,好的样本分数都是500以上,坏的样本都在500以下。虽然换些样本会发现未必完全准确,但总体来说能识别较多的坏客户。
最后上线后,我们要需要设计个策略,告诉审核员,哪些分数的客户直接拒绝,那些分数的客户可以直接接受,哪些分数的客户需要人工审核。策略大概如下表所示。(下图的分值只是大概写些数字举例,实际还需要计算得出最佳决策方案)
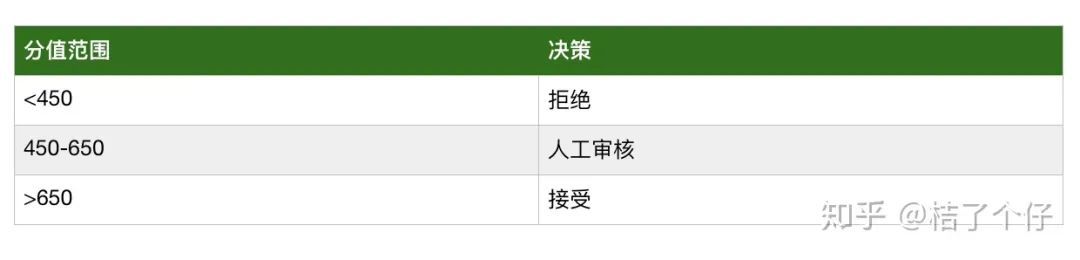
至此,一个效果还不错的评分卡就产出了。
总结
本文首先讲述了评分卡的分类、优缺点。接下来,结合了完整的可以马上运行的代码,中间穿插理论,讲解了评分卡的开发流程。完整的代码在https://www.kaggle.com/orange90/credit-scorecard-example。
最后,把方法论再梳理一次,加深大家理解,大家可以把下面这段复制到自己的笔记上,以后工作时随时用到。
0. 数据探究
观测有没null值
观察数据分布
1. 样本选取
可以用前后各取样的方法来选择验证集
或者随机抽样30%作为验证集
2. 变量选取
分箱
通过IV值选取有效特征
把特征变成WOE表现形式
3. 逻辑回归
观测验证集的AUC
4. 评分卡转换
根据逻辑回归的公式转换
设置PDO,基准分等
5. 验证并上线
验证结果
设计策略