
风控ML[16] | 风控建模中怎么做拒绝推断

00 Index
01 什么是拒绝推断?
02 为什么要做拒绝推断?
03 什么时候做拒绝推断?
04 做拒绝推断都有哪些方法?
05 验证拒绝推断效果的方式
06 总结一下
🎲 01 什么是拒绝推断
拒绝推断要解决的问题就是去推断那些被拒绝的客户,如果放贷的话,后续的贷后表现是什么样子,是好样本,还是坏样本?并把推断的结果,加入到建模样本中用于丰富样本的多样性,缩小与总体分布之间的差异。
🎲 02 为什么要做拒绝推断
在我们的生活中,有很多关于幸存者偏差的例子,比如我们身边的同事月收入都是过万,就误以为大多数人都是这样子,身边的人都是本科毕业,就以为大多数人都上过大学。同样的,在金融建模领域也会有这种现象,那就是很多坏客户可能被我们拒绝准入了,所以长期以往库内的客户,都基本上算是不那么差的客户,那么如果我们直接拿这些数据来统计建模,就会出现了偏差,也就是用局部样本代替了全局样本,从而可能会得到不太能代表真实分布的模型,出现了线下回溯效果好,但上生产实际去跑之后的表现却不尽人意。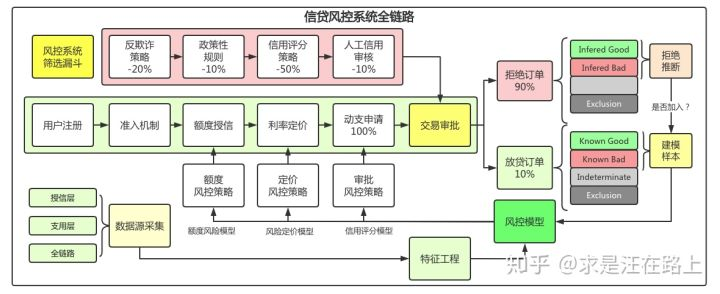 图:来自于https://zhuanlan.zhihu.com/p/8862498
图:来自于https://zhuanlan.zhihu.com/p/8862498
这就是我们为什么要做拒绝推断的主要原因,我们需要加入一些“坏客户”,从而让我们的抽样能够尽可能描述总体的情况,避免出现上述情况。
🎲 03 什么时候做拒绝推断
一般情况下都不太需要去做拒绝推断的,但如果很多次模型部署上线后的效果都不太好并且找不到原因的话,那可以考虑走这一步了。当然,如果条件不允许拿线上来随便迭代测试,也可以在建模前,做好库内样本的分布统计,并且拿着与预授信环节(或者是营销环节)的客群分布来对比下模型主要的特征分布,看看两者是否有比较明显的差异,如果是的话,有很大概率也是因为有了较大的偏差了,这个需要也需要我们去做拒绝推断。
但是有些场景,其实也没有太大的做拒绝推断的必要。比如说,审批通过率很高的场景,这样子其实贷后样本基本上与真实的客群分布相差无几;相反地,另一个极端,比如审批通过率很低的场景,由于拒绝推断与真实贷后表现之间会存在比较大的差异,加入拒绝样本不太好去控制模型的收敛,或者说模型性能会很难有较好的提升。
🎲 04 做拒绝推断都有哪些方法
这里的方法介绍,我在知乎上看到汪哥的相关文章,写得真的是太棒了!我比较难超越了,就把他的原文链接🔗贴过来,大家可以去看看哦。
《风控建模中的样本偏差与拒绝推断》https://zhuanlan.zhihu.com/p/88624987
不过我也还是把他文章里的分类体系在这里重点再次分享一下。 其中,数据法中提到的3种方式都是比较好理解的。
其中,数据法中提到的3种方式都是比较好理解的。
方法一:简单说就是把模型应该拒绝的客户,按照一定规则(比如不那么坏的客户)给予审批通过的决策,后续观察其贷后表现,给未来的模型提供更丰富的数据; 方法二:指的是从其他机构或者类似产品中获得客户的贷后表现数据,从而来捞回一些拒绝的客户,给予这些客户好坏的标签,用于后续的建模; 方法三:从人工审核的流程中找到具体的拒绝原因,根据描述,人工给予拒绝客户好坏标签。
而对于推断法就会相对比较复杂一点,这里就不一一展开来说了,就讲一个比较经典的展开法(Augmentation)。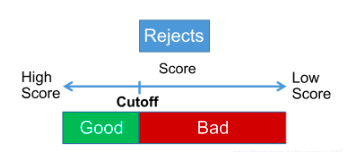
展开法的实施步骤主要是:
1、拿到贷后的样本,按照一定的好坏样本定义规则打上Y值,接着就是常规操作,得到 评分卡模型A;
2、拿着评分卡模型A,去对全量样本(包含拒绝的)进行打分,得到每个样本的模型分P(good);
3、将拒绝样本的模型分P进行降序,设置cutoff。cutoff一般按照业务经验来设置,就是拒绝样本中被赋予通过的样本,其badrate水平,是正常放款样本中的badrate水平的2~4倍;
4、根据步骤3设置的cutoff,高于这个阈值的赋予good标签,低于阈值则赋予bad标签;
5、最后利用全量样本(包括拒绝的)进行建模,得到新的评分卡模型B。
以上的5个步骤,就是实施拒绝推断中推断法之一的展开法。
🎲 05 验证拒绝推断效果的方式
最直接的方法就是使用AB Test,将部分订单使用原模型,部分订单使用加入拒绝样本建立的模型,cutoff设置一样的badrate,然后线上实际运行进行效果评估。如果加入拒绝推断后的模型可以带来更好的效果(比如放款率高且坏账率低),则代表模型有效!
但是,如果我们并没有这么多时间或者成本来做测试,也可以通过统计单变量的IV值来辅助判断,因为经验得知,做了拒绝推断后加入拒绝样本,可以让变量IV值带来提升。
🎲 06 总结一下
本文算是一个对拒绝推断的入门介绍了,让初涉风控模型的同学有一个相对来说比较清晰的全局认识,这里面涉及到的很多算法模型上的细节并没有展开来讲,因为我觉得这也会让阅读带来比较大的负担,公众号的文章还是要控制在几分钟内读完比较合适。不过,我也把相关其他博主这块算法模型写得比较清晰易懂的文章,分享给大家,感兴趣的同学可以抽空到电脑上细细研究拜读嘻嘻,我觉得这十分值得我们花时间去理解去吸收!
📚 Reference
[1] 异常检测算法分类及经典模型概览
https://blog.csdn.net/cyan_soul/article/details/101702066
[2] 风控建模中的样本偏差与拒绝推断
https://zhuanlan.zhihu.com/p/88624987
[3] 【模型迭代】拒绝推断(RI)
https://blog.csdn.net/sunyaowu315/article/details/94830732