
风控ML[4] | 风控建模的KS

我们这做风控模型的时候,经常是会用KS值来衡量模型的效果,这个指标也是很多领导会直接关注的指标。今天写一篇文章来全面地剖析一下这个指标,了解当中的原理以及实现,因为这些知识是必备的基本功。我将会从下面几个方面来展开讲解一下KS:
KS的概念 KS的生成逻辑 KS的效果应用 KS的实现
01 KS的概念
KS的全称叫“Kolmogorov-Smirnov“,我知道的是苏联数学家提出来的一个检验方法,后面怎么地就用到了风控模型的区分度评估就不知道咯。不过这不影响我们去使用它,我们只需要知道在风控中是怎么实现的,并且在实际场景中怎么去使用它就可以了。就如上面我们说的,KS在风控主要是用于评估模型的好坏样本区分度高低的。什么是区分度?通俗来说,就是模型预测结果排序分桶后,每个桶的好坏样本占比的有排序性,也就是说不同的桶,坏人的识别能力都不同,我们可以通过“拒绝”坏人比较多的桶从而来实现风险控制。比较抽象?可以看下图:
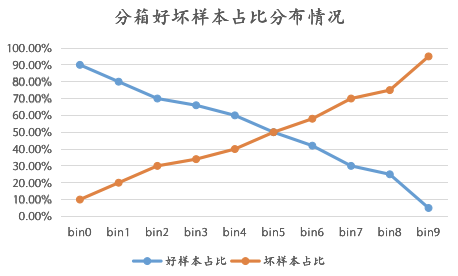
02 KS的生成逻辑
KS的生成逻辑公式也是十分简单:
在风控领域,我们在计算KS前一般会根据我们认为的“正态分布原则”进行分箱,一般来说分成了10份,然后再进行KS的计算。具体的可以看下面的Demo:

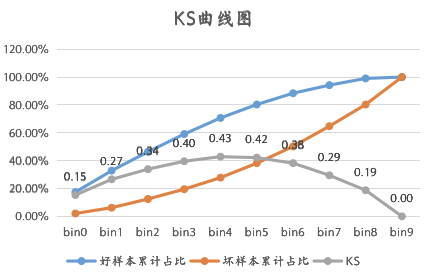
03 KS的效果应用
KS的值域在0-1之间,一般来说KS是越大越有区分度的,但在风控领域并不是越大越好,到底KS值与风控模型可用性的关系如何,可看下表:
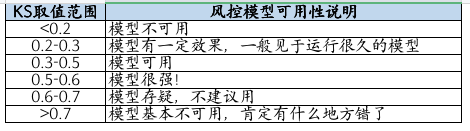
004 KS的实现
首先我们来对上面展示的例子进行Python代码实现。
import pandas as pd
import numpy as np
# test data
bin_df = pd.DataFrame([['bin0', 100, 10],
['bin1', 100, 20],
['bin2', 100, 30],
['bin3', 100, 34],
['bin4', 100, 40],
['bin5', 100, 50],
['bin6', 100, 58],
['bin7', 100, 70],
['bin8', 100, 75],
['bin9', 100, 95]]
,columns=['bins', 'bin_nums', 'bad_nums'])
bin_df['good_nums'] = bin_df.bin_nums - bin_df.bad_nums
bin_df['bad_rate'] = bin_df.bad_nums/bin_df.bin_nums
bin_df['good_rate'] = 1 - bin_df.bad_rate
bin_df['bad_cum'] = bin_df.bad_nums.cumsum()
bin_df['good_cum'] = bin_df.good_nums.cumsum()
bin_df['bad_cum_rate'] = bin_df.bad_cum/bin_df.bad_nums.sum()
bin_df['good_cum_rate'] = bin_df.good_cum/bin_df.good_nums.sum()
bin_df['cum_rate_dif'] = abs(bin_df.bad_cum_rate - bin_df.good_cum_rate)
bin_df
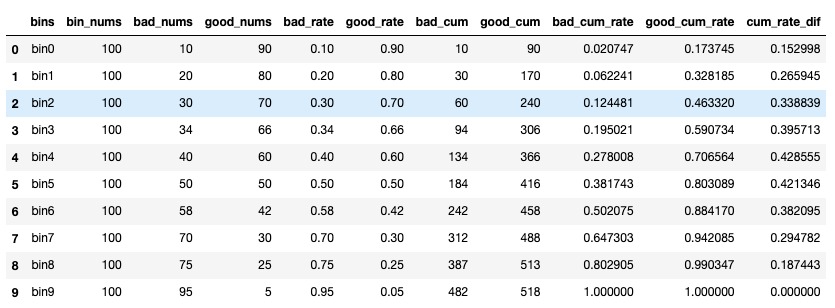
我们将数据进行一下可视化:
from matplotlib import pyplot
import matplotlib.pyplot as plt
print("KS:", bin_df.cum_rate_dif.max())
plt.plot(bin_df.bins, bin_df.bad_cum_rate, marker='o', mec='r', mfc='w', label='bad_cum_rate')
plt.plot(bin_df.bins, bin_df.good_cum_rate, marker='*', mec='r', mfc='w', label='good_cum_rate')
plt.plot(bin_df.bins, bin_df.cum_rate_dif, marker='x', mec='r', mfc='w', label='good_cum_rate')
plt.legend()

可以看到可视化的效果和我们在Excel里画出来的差不多。
以上的代码实现是基于分桶后的结果进行操作的,但是在大多数的情况下,都是不先进行分桶的,而是直接进行KS的计算,而计算KS的方式主要有两种:
# test data
y_true = np.array([1,1,0,0,0,0,0,0,0,0]) # 真实标签,0代表好人,1代表坏人
y_pred_proba = np.array([0.7,0.6,0.1,0.3,0.3,0.5,0.6,0.4,0.1,0.2]) # 模型预测概率结果,值域0-1,越大代表越解决坏人
# way1
from scipy.stats import ks_2samp
ks = ks_2samp(y_pred_proba[y_true == 1], y_pred_proba[y_true == 0]).statistic
print("#### way1 ####")
print("KS:", ks)
# way2
from sklearn import metrics
fpr, tpr, thresholds = metrics.roc_curve(y_true, y_pred_proba)
print("#### way2 ####")
print("KS:", max(tpr-fpr))
# output
#### way1 ####
KS: 0.875
#### way2 ####
KS: 0.875
05 最后说一下
光看KS值来评估模型效果其实是不足够的,就好像我们看一个人并不能光看脸,还得看身材、人品、才能等等,我们还需要看AUC、准确率、稳定性、覆盖率等等,这些后续都会陆续讲到。今天我们就先了解清楚一下KS就可以了。