
风控ML[3] | 风控建模的WOE与IV


「风控ML」系列文章,主要是分享一下自己多年以来做金融风控的一些事一些情,当然也包括风控建模、机器学习、大数据风控等相关技术分享,欢迎同行交流与新同学的加入,共同学习,进步!

第一次接触这两个名词是在做风控模型的时候,老师教我们可以用IV去做变量筛选,IV(Information Value),中文名是信息值,简单来说这个指标的作用就是来衡量变量的预测能力强弱的,然后IV又是WOE算出来的。姑且先不管原理哈,我们先给出来一下结论。| IV范围 | 变量预测力 |
|---|---|
| <0.02 | 无预测力😯 |
| 0.02~0.10 | 弱👎 |
| 0.10~0.30 | 中等😊 |
| `> 0.30 | 强👍 |
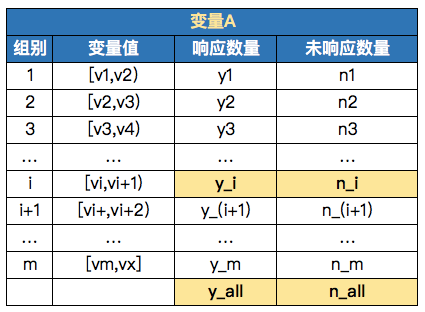
01 WOE的原理
WOE是weight of evidence的缩写,是一种编码形式,首先我们要知道WOE是针对类别变量而言的,所以连续性变量需要提前做好分组(这里也是一个很好的考点,也有会说分箱、离散化的,变量优化也可以从这个角度出发)。
先给出数学计算公式,对于第i组的WOE可以这么计算:
从公式上可以看出,第i组的WOE值等于这个组的响应客户占所有响应客户的比例与未响应客户占所有未响应客户的比例的比值取对数。对于上面的公式我们还可以 简单做一下转化:
所以,WOE主要就是体现组内的好坏占比与整体的差异化程度大小,WOE越大,差异越大。
02 IV的原理
上面我们介绍了如何计算一个分组的WOE值,那么我们就可以把变量所有分组的WOE值给算出来了,对应地,每个分组也有一个IV值,我们叫 ,其中:
计算这个变量的IV值就是这样子就可以了,把每个分组的IV值给加起来。
03 实际案例
好了,上面的理论也讲了一些了,还是拿一个实际的变量来计算一下。
我们来假设一个场景,我们需要卖茶叶,然后我们不知道从哪里拿来了一份1000人的营销名单(手机号码),然后就批量添加微信好友,最后有500个手机号码可以成功搜索到微信号的,进而进行了好友添加,最终有100人成功添加到好友了。
我们这份名单上,有客户的年龄字段,那么我们可以拿来计算一下这个字段对于是否成功添加好友(响应)有多大的预测能力,我们在Excel中进行实现:
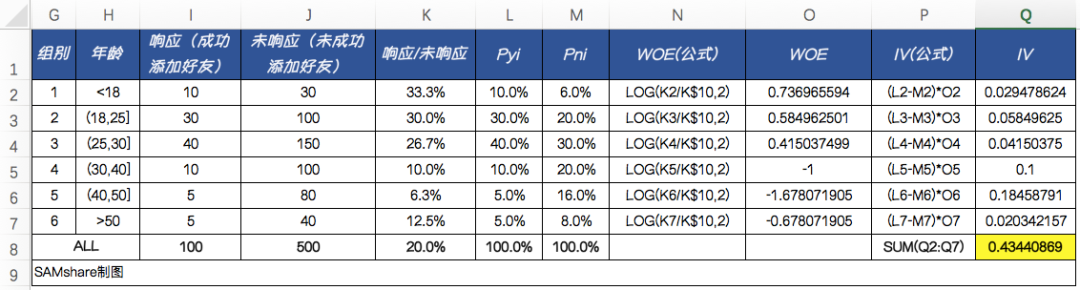
可以看出来,这个变量对于我们是否可以成功加到客户微信好友有着很强的预测能力。
04 Python实现
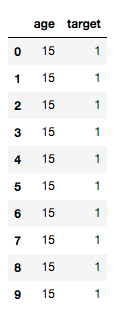
我们知道,针对连续型变量,是需要先转换为类别变量才可以进行IV值的计算的,现在我们把数据导入到Python中,原始变量是连续型变量,那么我们如何在Python里实现IV值的计算呢?如下图:(其中target=1代表响应,target=0代表未响应)
核心代码就是下面的:
def iv_count(data_bad, data_good):
'''计算iv值'''
value_list = set(data_bad.unique()) | set(data_good.unique())
iv = 0
len_bad = len(data_bad)
len_good = len(data_good)
for value in value_list:
# 判断是否某类是否为0,避免出现无穷小值和无穷大值
if sum(data_bad == value) == 0:
bad_rate = 1 / len_bad
else:
bad_rate = sum(data_bad == value) / len_bad
if sum(data_good == value) == 0:
good_rate = 1 / len_good
else:
good_rate = sum(data_good == value) / len_good
iv += (good_rate - bad_rate) * math.log(good_rate / bad_rate,2)
print(value,iv)
return iv
那么我们如何使用呢,一步一步来:
Step1:导入数据
测试数据集可以后台回复 'age' 进行获取。
data = pd.read_csv('./data/age.csv')
# 定义必要的参数
feature = data.loc[:,['age']]
labels = data['target']
keep_cols = ['age']
cut_bin_dict = {'age':[0,18,25,30,40,50,100]}
Step2:按照指定阈值分箱
按照我们之前Excel相同的分箱逻辑进行分箱:
cut_bin = cut_bin_dict['age']
# 按照分箱阈值分箱,并将缺失值替换成Blank,区分好坏样本
data_bad = pd.cut(feature['age'], cut_bin, right=False).cat.add_categories(['Blank']).fillna('Blank')[labels == 1]
data_good = pd.cut(feature['age'], cut_bin, right=False
).cat.add_categories(['Blank']).fillna('Blank')[labels == 0]
value_list = set(data_bad.unique()) | set(data_good.unique())
value_list

Step3:调用函数计算IV
iv_series['age'] = iv_count(data_bad, data_good)
iv_series
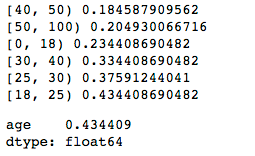
可以看得出,和我们Excel计算的结果完全一致!
05 “我要打10个”版本
嗯,上面针对单个的变量IV计算是会了,那么如果有一堆需要你计算IV的变量,可以如何处理呢?其实,原理很简单,就是写个循环,这里呢已经写好了一个,大家可以参考一下的。这边有一些细节的东西需要说明一下的。
1)注意区分变量类型,数值型变量和类别型变量要区分对待。
2)注意分组后是否出现某组内的响应(未响应)数量为零的情况,如果为零需要处理一下。
代码放上,大家可以试着运行一下:
def get_iv_series(feature, labels, keep_cols=None, cut_bin_dict=None):
'''
计算各变量最大的iv值,get_iv_series方法出入参如下:
------------------------------------------------------------
入参结果如下:
feature: 数据集的特征空间
labels: 数据集的输出空间
keep_cols: 需计算iv值的变量列表
cut_bin_dict: 数值型变量要进行分箱的阈值字典,格式为{'col1':[value1,value2,...], 'col2':[value1,value2,...], ...}
------------------------------------------------------------
入参结果如下:
iv_series: 各变量最大的IV值
'''
def iv_count(data_bad, data_good):
'''计算iv值'''
value_list = set(data_bad.unique()) | set(data_good.unique())
iv = 0
len_bad = len(data_bad)
len_good = len(data_good)
for value in value_list:
# 判断是否某类是否为0,避免出现无穷小值和无穷大值
if sum(data_bad == value) == 0:
bad_rate = 1 / len_bad
else:
bad_rate = sum(data_bad == value) / len_bad
if sum(data_good == value) == 0:
good_rate = 1 / len_good
else:
good_rate = sum(data_good == value) / len_good
iv += (good_rate - bad_rate) * math.log(good_rate / bad_rate,2)
return iv
if keep_cols is None:
keep_cols = sorted(list(feature.columns))
col_types = feature[keep_cols].dtypes
categorical_feature = list(col_types[col_types == 'object'].index)
numerical_feature = list(col_types[col_types != 'object'].index)
iv_series = pd.Series()
# 遍历数值变量计算iv值
for col in numerical_feature:
cut_bin = cut_bin_dict[col]
# 按照分箱阈值分箱,并将缺失值替换成Blank,区分好坏样本
data_bad = pd.cut(feature[col], cut_bin, right=False).cat.add_categories(['Blank']).fillna('Blank')[labels == 1]
data_good = pd.cut(feature[col], cut_bin, right=False
).cat.add_categories(['Blank']).fillna('Blank')[labels == 0]
iv_series[col] = iv_count(data_bad, data_good)
# 遍历类别变量计算iv值
for col in categorical_feature:
# 将缺失值替换成Blank,区分好坏样本
data_bad = feature[col].fillna('Blank')[labels == 1]
data_good = feature[col].fillna('Blank')[labels == 0]
iv_series[col] = iv_count(data_bad, data_good)
return iv_series
调用demo:
iv_series = get_iv_series(feature, labels, keep_cols, cut_bin_dict=cut_bin_dict)
iv_series
# age 0.434409
06 总结一下
记住IV值的预测能力映射:
| IV范围 | 变量预测力 |
|---|---|
| <0.02 | 无预测力😯 |
| 0.02~0.10 | 弱👎 |
| 0.10~0.30 | 中等😊 |
| `> 0.30 | 强👍 |
如果想复现代码,可以从我的公号后台输出 'age' 去获取测试集吧,或者拿自己目前的数据集来玩玩也可以,不过得注意一些细节,转换数据格式。