
R语言朴素贝叶斯Naive Bayes分类Iris鸢尾花和HairEyeColor学生性别和眼睛头发颜色数据
全文链接:http://tecdat.cn/?p=31070
最近,在贝叶斯统计实验中,我们向客户演示了用R的朴素贝叶斯分类器可以提供的内容(点击文末“阅读原文”获取完整代码数据)。
这个实用的例子介绍了使用R统计环境的朴素贝叶斯模型。它不假设先验知识。
相关视频
我们的步骤是:
1.启动R
2.探索Iris鸢尾花数据集
3.构造朴素贝叶斯分类器
4.理解朴素贝叶斯
探索Iris数据集
在这个实践中,我们将探索经典的“Iris”数据集。
Iris数据集有150个数据点和5个变量。每一个数据点包含一个特定的花样本,并给出4种花的测量值。
任务是用花的特征与种类一起构建一个分类器,从4种对花的观测量中预测花的种类。
要将Iris数据集放到您的R会话中,请执行以下操作:
data(iris)
查看数据
pairs(iris[1:4],main="
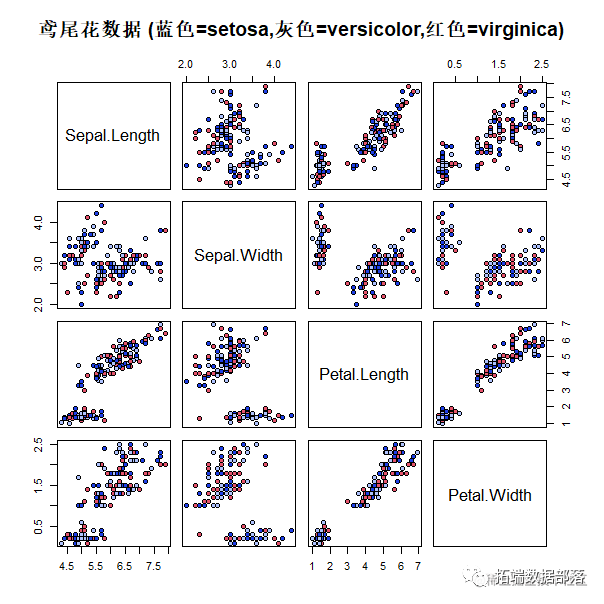
命令创建了一个散点图。类决定数据点的颜色。从中可以看出,setosa花的花瓣比其他两种都要小。
点击标题查阅往期内容


左右滑动查看更多


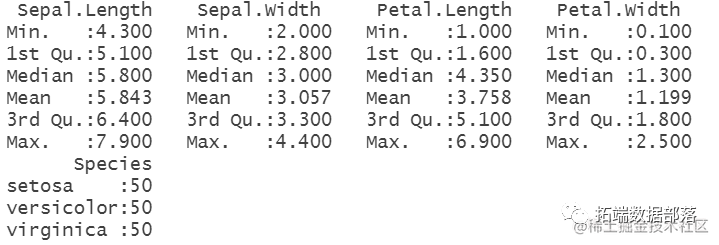
提供数据摘要
summary(iris)
构造朴素贝叶斯分类器
我们构建一个朴素的贝叶斯分类器。
(1)加载到工作区
(2)构建朴素贝叶斯分类器,
(3)对数据进行一些预测,执行以下操作:
library(e1071)
classifier<-naiveBayes(iris[,1:4], iris[,5])
table(predict(classifier, iris[,-5]), iris[,5], dnn=list('predicted','actual'))

正如你应该看到的那样,分类器在分类方面做得很好。
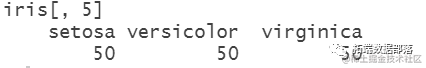
这给出了数据中的类分布:类的先验分布。(“先验”是拉丁语,表示“从前开始”)。
由于这里的预测变量都是连续的,朴素贝叶斯分类器为每个预测变量生成三个Giaussian(正态分布)分布:一个用于类变量的每个值。
您将看到3个依赖于类的高斯分布的平均值(第一列)和标准偏差(第二列):

绘制成图:
plot(function(x) dnorm, 0, 8, col=2, main="3种不同物种的花瓣长度分布")
curve(
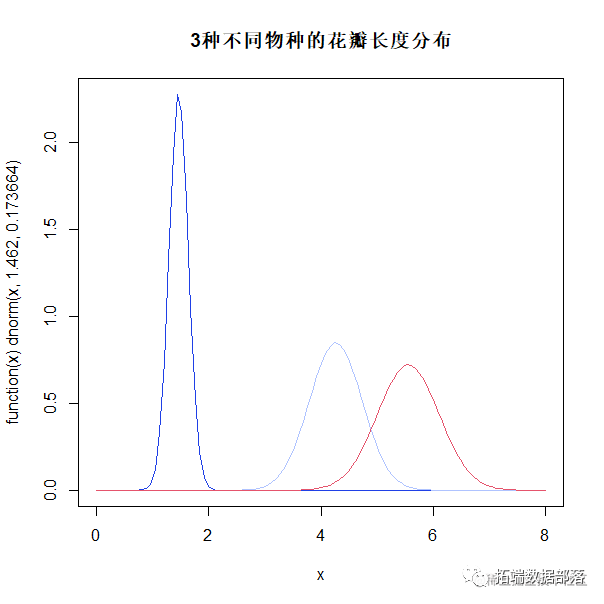
值得注意的是,setosa irises(蓝色曲线)花瓣较小(平均值=1.462),花瓣长度变化较小(唐氏偏差仅为0.1736640)。
理解朴素贝叶斯
在这个问题中,您必须计算出对于一些离散数据,朴素贝叶斯模型的参数应该是什么。
该数据集被称为HairEyeColor,有三个变量:性别、眼睛和头发,给出了某大学592名学生的这3个变量的值。首先看一下数字:
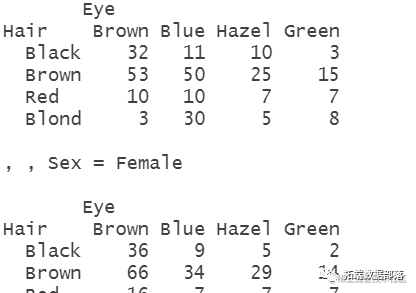
您还可以将其绘制为“马赛克”图,它使用矩形来表示数据中的数字:

你在这里的工作是为一个朴素贝叶斯分类器计算参数,它试图从另外两个变量中预测性别。参数应该使用最大似然性来估计。为了节省手工计算的繁琐时间,下面是如何使用Edge.table来获取所需的计数

naiveBayes(Sex ~
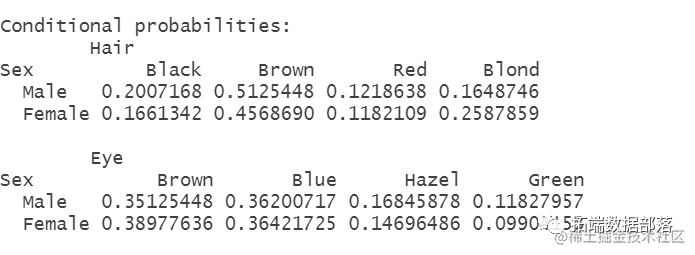
预测


点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言朴素贝叶斯Naive Bayes分类Iris鸢尾花和HairEyeColor学生性别和眼睛头发颜色数据》。
点击标题查阅往期内容

![]()