
实战:手把手教你用朴素贝叶斯对文档进行分类
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|视觉算法

朴素贝叶斯分类最适合的场景就是文本分类、情感分析和垃圾邮件识别。其中情感分析和垃圾邮件识别都是通过文本来进行判断。所以朴素贝叶斯也常用于自然语言处理 NLP 的工具。
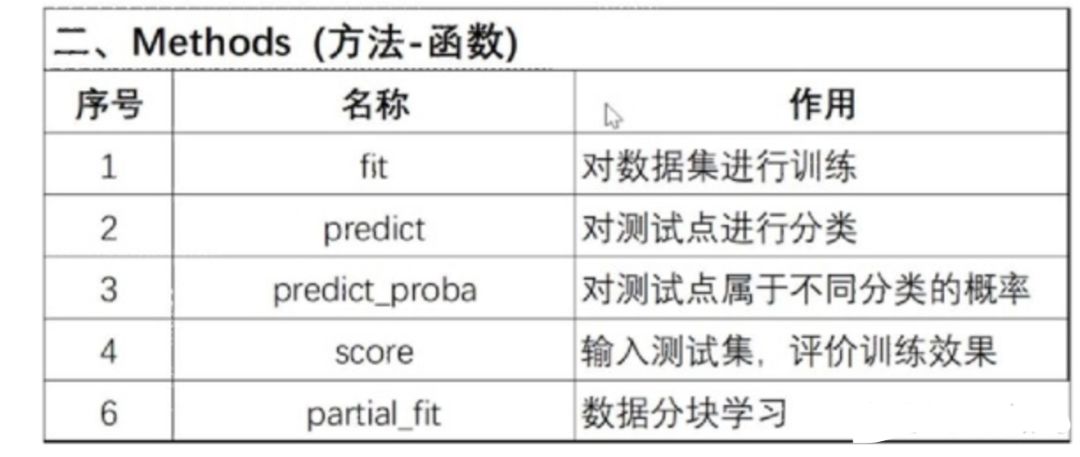
sklearn 机器学习包
sklearn 的全称叫 Scikit-learn,它给我们提供了 3 个朴素贝叶斯分类算法,分别是高斯朴素贝叶斯(GaussianNB)、多项式朴素贝叶斯MultinomialNB)和伯努利朴素贝叶斯(BernoulliNB)。
这三种算法适合应用在不同的场景下,我们应该根据特征变量的不同选择不同的算法:
高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的 TF-IDF 值等。
伯努利朴素贝叶斯:**特征变量是布尔变量,符合 0/1 分布**,在文档分类中特征是单词是否出现。
伯努利朴素贝叶斯是以文件为粒度,如果该单词在某文件中出现了即为 1,否则为 0。而多项式朴素贝叶斯是以单词为粒度,会计算在某个文件中的具体次数。
> 如身高、体重这种自然界的现象就比较适合用高斯朴素贝叶斯来处理。而文本分类是使用多项式朴素贝叶斯或者伯努利朴素贝叶斯。
什么是 TF-IDF 值呢?
TF-IDF 是一个统计方法,用来评估某个词语对于一个文件集或文档库中的其中一份文件的重要程度。
词频 TF计算了一个单词在文档中出现的次数,它认为一个单词的重要性和它在文档中出现的次数呈正比。
逆向文档频率 IDF,是指一个单词在文档中的区分度。它认为一个单词出现在的文档数越少,就越能通过这个单词把该文档和其他文档区分开。IDF 越大就代表该单词的区分度越大。
所以 TF-IDF 实际上是词频 TF 和逆向文档频率 IDF 的乘积。这样我们倾向于找到 TF 和 IDF 取值都高的单词作为区分,即这个单词在一个文档中出现的次数多,同时又很少出现在其他文档中。这样的单词适合用于分类。
TF-IDF 如何计算


些单词可能不会存在文档中,为了避免分母为 0,统一给单词出现的文档数都加 1。
举个例子
假设一个文件夹里一共有 10 篇文档,其中一篇文档有 1000 个单词,“this”这个单词出现 20 次,“bayes”出现了 5 次。“this”在所有文档中均出现过,而“bayes”只在 2 篇文档中出现过。
针对“this”,计算 TF-IDF 值:
所以 TF-IDF=0.02*(-0.0414)=-8.28e-4。
针对“bayes”,计算 TF-IDF 值:
TF-IDF=0.005*0.5229=2.61e-3。
很明显“bayes”的 TF-IDF 值要大于“this”的 TF-IDF 值。这就说明用“bayes”这个单词做区分比单词“this”要好。
如何求 TF-IDF
在 sklearn 中我们直接使用 TfidfVectorizer 类,它可以帮我们计算单词 TF-IDF 向量的值。
在这个类中,取 sklearn 计算的对数 log 时,底数是 e,不是 10。
创建 TfidfVectorizer 的方法是:
TfidfVectorizer(stop_words=stop_words, token_pattern=token_pattern)


当我们创建好 TF-IDF 向量类型时,可以用 fit_transform 帮我们计算,返回给我们文本矩阵,该矩阵表示了每个单词在每个文档中的 TF-IDF 值。

在我们进行 fit_transform 拟合模型后,我们可以得到更多的 TF-IDF 向量属性,比如,我们可以得到词汇的对应关系(字典类型)和向量的 IDF 值,当然也可以获取设置的停用词 stop_words。
现在想要计算文档里都有哪些单词,这些单词在不同文档中的 TF-IDF 值是多少呢?
首先我们创建 TfidfVectorizer 类:
from sklearn.feature_extraction.text import TfidfVectorizertfidf_vec = TfidfVectorizer()documents = ['this is the bayes document','this is the second second document','and the third one','is this the document']tfidf_matrix = tfidf_vec.fit_transform(documents)print('不重复的词:', tfidf_vec.get_feature_names())print('每个单词的 ID:', tfidf_vec.vocabulary_)#输出每个单词在每个文档中的 TF-IDF 值,向量里的顺序是按照词语的 id 顺序来的:print('每个单词的 tfidf 值:', tfidf_matrix.toarray())输出不重复的词: ['and', 'bayes', 'document', 'is', 'one', 'second', 'the', 'third', 'this']每个单词的 ID: {'this': 8, 'is': 3, 'the': 6, 'bayes': 1, 'document': 2, 'second': 5, 'and': 0, 'third': 7, 'one': 4}每个单词的 tfidf 值: [[0. 0.63314609 0.40412895 0.40412895 0. 0.0.33040189 0. 0.40412895][0. 0. 0.27230147 0.27230147 0. 0.853225740.22262429 0. 0.27230147][0.55280532 0. 0. 0. 0.55280532 0.0.28847675 0.55280532 0. ][0. 0. 0.52210862 0.52210862 0. 0.0.42685801 0. 0.52210862]]
如何对文档进行分类
1. 基于分词的数据准备,包括分词、单词权重计算、去掉停用词;
2. 应用朴素贝叶斯分类进行分类,首先通过训练集得到朴素贝叶斯分类器,然后将分类器应用于测试集,并与实际结果做对比,最终得到测试集的分类准确率。
一般来说 NTLK 包适用于英文文档,而 jieba 适用于中文文档。我们可以根据文档选择不同的包,对文档提取分词。这些分词就是贝叶斯分类中最重要的特征属性。基于这些分词,我们得到分词的权重,即特征矩阵。
在这个链接下下载数据集:github.com/cystanford/t
train_contents=[]train_labels=[]test_contents=[]test_labels=[]# 导入文件import osimport iostart=os.listdir(r'C:/Users/baihua/Desktop/text classification/train')for item in start:test_path='C:/Users/baihua/Desktop/text classification/test/'+item+'/'train_path='C:/Users/baihua/Desktop/text classification/train/'+item+'/'for file in os.listdir(test_path):with open(test_path+file,encoding="GBK") as f:test_contents.append(f.readline())#print(test_contents)test_labels.append(item)for file in os.listdir(train_path):with open(train_path+file,encoding='gb18030', errors='ignore') as f:train_contents.append(f.readline())train_labels.append(item)print(len(train_contents),len(test_contents))# 导入stop wordimport jiebafrom sklearn import metricsfrom sklearn.naive_bayes import MultinomialNB#stop_words = [line.strip() for line in io.open(r'C:/Users/baihua/Desktop/stopword.txt').readlines()]with open(r'C:/Users/baihua/Desktop/stopword.txt', 'rb') as f:stop_words = [line.strip() for line in f.readlines()]# 分词方式使用jieba,计算单词的权重tf = TfidfVectorizer(tokenizer=jieba.cut,stop_words=stop_words, max_df=0.5)##注意数据结构:stop_words是list,过滤词token_parten是正则表达式train_features = tf.fit_transform(train_contents)#该函数返回文本矩阵,表示每个单词在每个文档中的TF-IDF值print(train_features.shape)#模块 4:生成朴素贝叶斯分类器# 多项式贝叶斯分类器clf = MultinomialNB(alpha=0.001).fit(train_features, train_labels)#模块 5:使用生成的分类器做预测test_tf = TfidfVectorizer(tokenizer=jieba.cut,stop_words=stop_words, max_df=0.5, vocabulary=tf.vocabulary_)test_features=test_tf.fit_transform(test_contents)predicted_labels=clf.predict(test_features)#模块六,计算准确性from sklearn import metricsprint (metrics.accuracy_score(test_labels, predicted_labels))#print(test_features.shape)#print(metrics.accuracy_score(test_labels, predicted_labels))

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~