
斯坦福大学算法分析与设计课--分治算法(附小姐姐视频)
本文预计阅读时间4分钟,在读的过程中你需要带着以下问题:
分治算法的基本步骤
逆序对计数是如何使用分治算法来解决问题的
为什么MergeSort排序法可以自然的算出逆序对数目
分值策略一般步骤

把输入划分成更小的子问题。
递归的治理子问题。
把子问题的解决方案组合到一起,形成原始问题的解决方案。
应用: 逆序对数目

输入包含不同整数的数组A, 输出A中逆序对的数量,逆序是指: 如果 i < j 而 A[i] > A[j],那么 (i, j) 就是一组逆序对。
比如输入的数组是
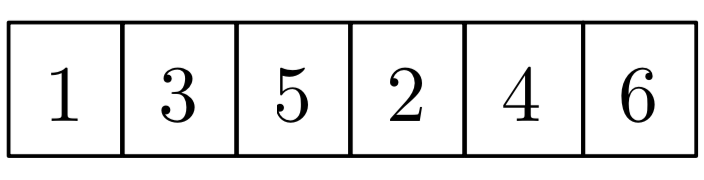
其中i = 2对应A[2] =3 ,j=4对应A[4]=2,2<4, 但是A[2] > A[4],所以这是一组逆序对。
协同筛选
为什么要对数组的逆序对计算?
一个原因是想要计算一种数值相似度,该数值的相似度用于对两个已排序列表之间的相似度进行量化。比如两个人都看过10部电影,按照从最喜欢到最不喜欢的顺序进行排列,那么怎么衡量两个人的选择是相似还是不相似的呢?解决这个问题的一种量化方法就是通过包含10个元素的数组A,A1表示读者的朋友从电影列表中选择最喜欢的电影,a2表示他喜欢第二的电影,以此类推,a10表示他最不喜欢的电影,这样如果读者最喜欢的电影是星球大战,而这部电影在读者的列表中只显示的第5位,那么a1就等于5,如果两个人的排序是相同的,这个数组就已经排序了,不存在逆序对,如果这个数组包含的逆序对越多,读者和朋友之间对电影评价的分歧就越多,对电影的偏好就不同了。
对已排序列表进行相似性测量的另一个原因就是协同筛选,这是一种任意生成推荐方案的方法,网站就怎么推出关于产品电影歌曲内容的建议呢?在协同筛选中,其思路就是寻找其他与它相似偏好的用户,然后推荐他们所喜欢的内容。因此协同筛选需要用户“相似性”的定义,而计算逆序对就可以捕捉问题的本质。
暴力解法

我们首先想到的就是暴力穷举搜索法,输入一个数组A,里面包含不同的整数,输出的是它的逆序对个数,以上就是暴力解法的伪代码。外层循环i表示从左到右的遍历数组A中的元素,内层循环j是没有与i对比过的元素,逆序了就累加。它的缺点是时间复杂度很高,O(n^2)。
分而治之思想

如果我们用分治算法来算这个问题的话,第一个步骤就是把数组A划分成更小的子问题,我们把A平均的划分成两个部分,左边和右边,这样数组规模就变小了,这样划分下就有三种情况:
第1种就是逆序对 i 和 j 都位于数组的左半部分,就是下标 i 和 j 是小于等于n/2的
第2种情况是逆序对 i 和 j 位于数组的右半部分
第3种情况是逆序对 i 位于左半部分 j 位于右半部分,以上是伪代码。
接下来我们需要解决子问题,对于情况1,2其实就是调用自身的递归,所以我们只用实现第3钟情况CountSplitInv。
MergeSort思想
在CountInv的伪代码中,需要实现CountSplitInv函数,我们之前讲的MergeSort排序算法天然的可以计算逆序对数目,而它实现的思路又是两个已排序的数组合并成一个新数组,上面的CountInv的情况3实际就是i在左边数组中,j在右边数组中,而左右两边的数组没有排序,所以我们对他两排一下序就能引用MergeSort算法。我们稍微的修改一下上面的伪代码,使得递归后除了返回逆序对数目,还要返回排序后的数组,下面是修改后的伪代码。

那么以上在处理逆序对 i, j 一个在左边一个在右边这种情况的时候,就可以用上之前的MergeSort算法,现在我们来回顾一下。

以上是MergSort的伪代码,它是输入已排序的C和D,输出是排序好的B。i,j分别控制C,D的元素,哪个元素小就把它加入到B中。那么,这里的C就是原问题中的左半部,D就是原问题的右半部分,当C[i] > D[j] 的时候,说明产生了逆序对,而C又是排序后的,所以i之后的数字都是大于D[j]的,所以对于D[j]所带来的逆序对数目就是C数组i到最后的元素个数,所以,我们可以在排序的基础上计算出逆序对个数。把这一段话翻译成伪代码就是如下。

这样就完成了分治算法对于逆序对的计算。时间复杂度是O(nlogn),比暴力搜索快很多。文章开头的问题你想通了吗?ps:开头的视频,是美女小姐姐录制的哦,记得拉上去看看!

有热门推荐?