
PointPillar:利用伪图像高效实现3D目标检测
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
文章导读
计算机视觉任务中,2D卷积神经网络得益于极其出色的性能不断刷新着各大视觉任务的榜单,可谓是YYDS。随着人工智能算法的不断推进,更多的研究者将目光聚焦到了3D任务,那么在3D视觉任务中,2D卷积神经网络的神话能否延续呢?答案是肯定的!今天小编将分享一篇3D点云检测论文—Pointpillars,看看作者如何巧妙的只使用2D卷积,却实现了高效的3D目标检测。1
3D点云检测的现状如何
最近几年点云的三维目标检测一直很火,从早期的PointNet、PointNet++,到体素网格的VoxelNet,后来大家觉得三维卷积过于耗时,又推出了Complex-yolo等模型把点云投影到二维平面,用图像的方法做目标检测,从而加速网络推理。
所以在点云上实现3D目标检测通常就是这三种做法:3D卷积、投影到前视图或者鸟瞰图(Bev)。
3D卷积的缺点是计算量较大,导致网络的推理速度较慢。投影的方式受到点云的稀疏性的限制,使得卷积无法较好的提取特征,效率低下。而后来研究热点转向了采用鸟瞰图(Bev)的方式,但存在的明显的缺点就是需要手动提取特征,不利于推广到其他的雷达上使用。
拨开那些花里胡哨的网络,有什么更靠谱的模型能够权衡速度和精度做三维目标检测呢?
2
横空杀出的PointPillars
这是一篇前两年的点云目标检测网络,为什么重温它是因为小编在学习百度Apollo 6.0时发现它被集成进去作为激光雷达的检测模型了。在这里给大家解析一下该网络模型,看看有啥特点!
Pointpillars的创新点在于:提出了一种新的编码方式,利用柱状物的方式生成伪图像。
Pointpillars由三大部分组成:
利用pillars的方式将点云转化为稀疏伪图像;
使用2D网络进行特征的学习;
使用SSD检测头进行Bbox的回归。
如下图所示:
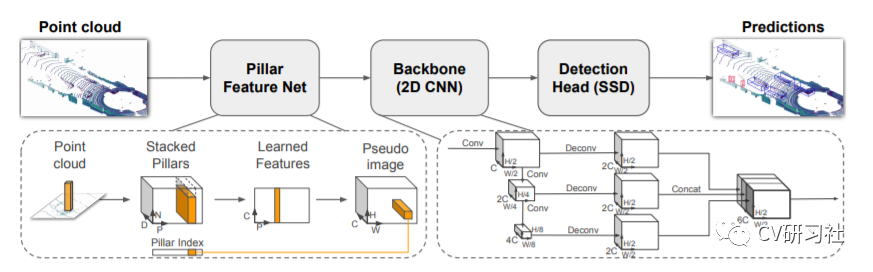
网络结构
Pointpillars的性能表现:具有明显的速度优势,最高也可达到105Hz,且对比仅使用点云作为输入的3D目标检测的方法有精度上的提升。
3
PointPillars的详细分析
想要学习一个网络模型,不管是图像还是点云的检测:
首先需要看看它是怎么做数据处理的?
然后了解它的特征提取模块是怎么搭建的?
接下来了解它的检测头选用的是什么?
模型搭建完毕后需要分析损失函数如何权衡?
最后当然是看看实验的仿真效果如何?
数据处理环节:
Pointpillar设计了一套编码方式将激光雷达输出的三维坐标转换到网络输入的形式,操作如下:
通常从激光雷达中获取的点云表现形式一般是x,y,z和反射强度i。
将点云离散到x-y平面的均匀间隔的网格中,从而创建一组柱状集P ,具有| P | = B,z轴不需要参数进行控制。
将每个支柱中的点增加xc,yc,zc,xp和yp(其中c下标表示到支柱中所有点的算术平均值的距离,p下标表示从支柱x,y中心的偏移量)。激光雷达中的每个点就具有了九维的特征。
对每个样本的非空支柱数(P)和每个支柱中的点数(N)施加限制,来创建大小为(D,P,N)的张量张量。如柱状体中的数据太多,则进行随机采样,如数据太少,则用0进行填充。
简化版本的PointNet对张量化的点云数据进行处理和特征提取(即对每个点都运用线性层+BN层+ReLU层),来生成一个(C,P,N)的张量,再对于通道上使用最大池化操作,输出一个(C,P)的张量。
编码后特征散布回原始的支柱位置,创建大小为(C,H,W)的伪图像。
(D, P, N)--> (C, P, N) --> (C, P) --> (C, H, W)
上述的转换流程流程如图所示:
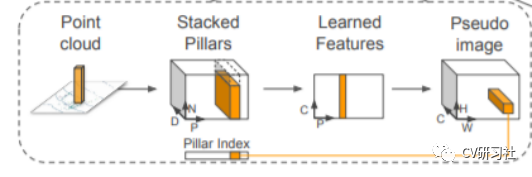
生成伪图像的过程
特征提取环节:
本文中的编码器的输出特征维度C=64,除了第1个Block中汽车的步幅S=2,行人和骑自行车的人的步幅为1,第2和第3个block中采用了相同的步幅。并对3个块进行上采样,最后将3个上采样的块进行通道拼接,可以为检测头提供6C维度的特征。
数据流在下采样和上采样的过程中并不复杂:
下采样:Block1(S,4,C),Block2(2S,6,2C),和Block3(4S,6,4C)
上采样:Up1(S,S,2C),Up2(2S,S,2C)和Up3(4S,S,2C)。
如下图所示:
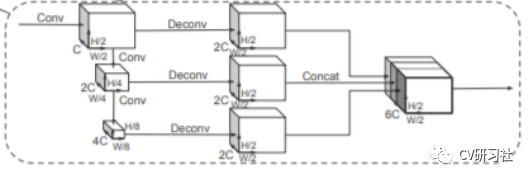
特征层结构
检测头模块
论文中作者使用SSD进行3D目标检测。与SSD相似,使用了2D联合截面(IoU)将先验盒和地面的真实情况进行匹配。Bbox的高度和高程没有用于匹配,取而代之的是2D匹配,高度和高程成为附加的回归目标。
损失函数部分
检测网络的损失函数一般都是有分类和回归两部分组成,分类损失用于给出目标的类别,回归损失用于给出目标的位置,而三维目标检测相比图像的二维检测多了3个参数。
3D Box由(x,y,z,w,h,l,0)进行定义:
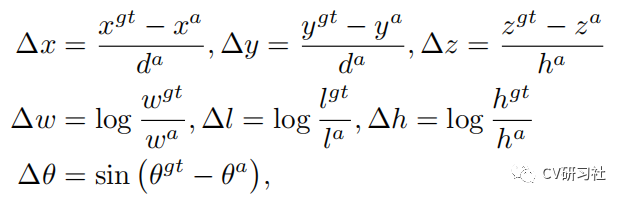
其中分类损失:
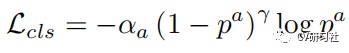
回归损失:
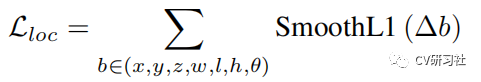
通过加权和的方式得到总的损失函数:
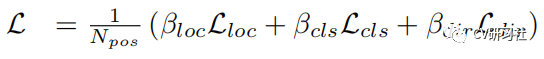
实验仿真结果
最后我们看一下文章给出的仿真结果:
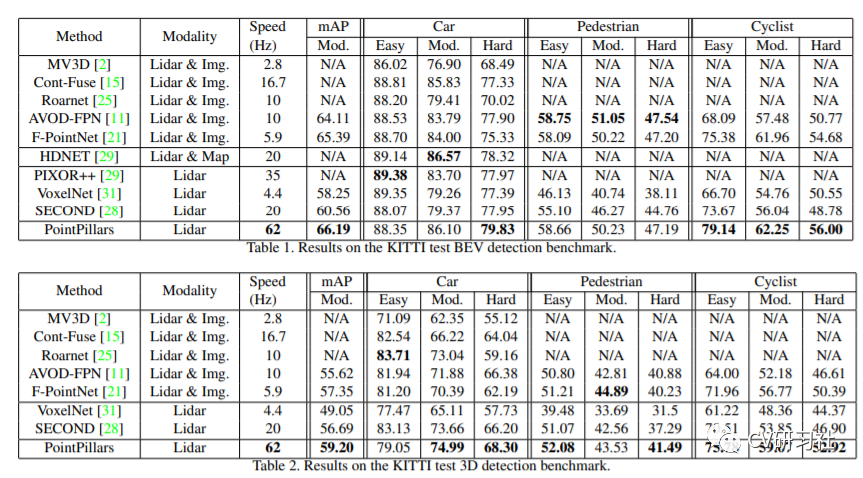
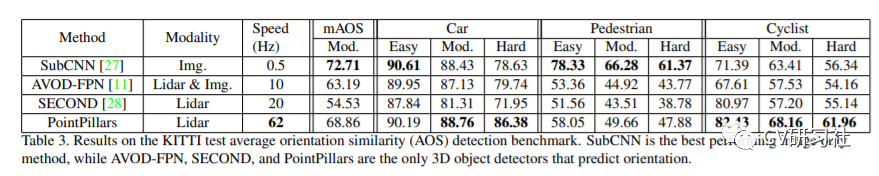
不管从速度上还是精度上相比于几种经典模型还是有一定程度的提高,但其实我们可以发现在行人等检测仍然徘徊在50%左右,和图像的目标检测动仄80%~90%的mAP还有很大的提升空间。
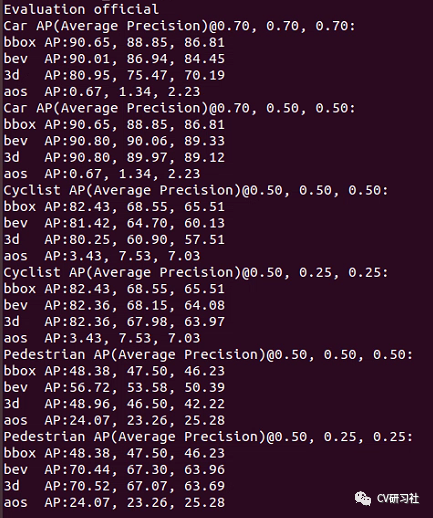
这里是运行源码的一份评估报告,不过源码中将车辆和行人等分开到两份配置中训练,估计是因为大小特征不一,怕合起来影响刷榜精度吧。
4
PointPillars的优缺点在哪里?
梳理一遍这个检测网络后,我们回顾对比一下其他方法,不难发现它的优势不外乎以下几点:
提出了一种新的点云编码器,不依靠固定编码器进行学习特征,可以利用点云的所有信息。
在柱状体而非体素(voxel)上进行操作,无需手动调整垂直方向的分箱。
网络中只使用2D卷积,不使用3D卷积,计算量小运行高效。
不适用手工特征,而是让网络自动的学习特征,因此无需手动的调整点云的配置,即可推广到其他的激光雷达中使用。
该网络侧重于三维数据形式的转换编码,所以在后续几个环节仍然有不少优化的空间,比如:
特征融合部分采用的FPN是否可以换成PAN
检测头采用的SSD是否可以换成更新的检测器
回归损失函数是否可以将角度和BBox紧耦合
通过阅读开源工程,发现它提供了一个效果展现的可视化工具,和小编以前做的联合标注工具很相似,如下图所示,针对同步后的激光雷达和摄像头数据,在可视化三维点云空间的同时,将感知的结果投影到图像的透视投影视角上以及点云的鸟瞰图视角中。

最主要的是这个工具可以用于其他的检测模型,只要在右侧的配置栏提供输入输出信息即可,强烈推荐!
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!