
10万亿!达摩院发布全球最大AI预训练模型,能耗仅为GPT-3的1%

大数据文摘作品
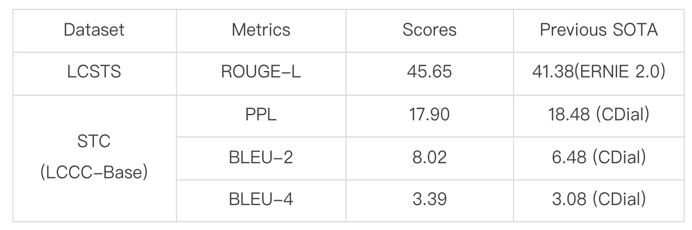
11月8日,阿里巴巴达摩院公布多模态大模型M6最新进展,其参数已从万亿跃迁至10万亿,规模远超谷歌、微软此前发布的万亿级模型,成为全球最大的AI预训练模型。同时,M6做到了业内极致的低碳高效,使用512 GPU在10天内即训练出具有可用水平的10万亿模型。相比去年发布的大模型GPT-3,M6实现同等参数规模,能耗仅为其1%。
与传统AI相比,大模型拥有成百上千倍“神经元”数量,且预先学习过海量知识,表现出像人类一样“举一反三”的学习能力。因此,大模型被普遍认为是未来的“基础模型”,将成下一代AI基础设施。然而,其算力成本相当高昂,训练1750亿参数语言大模型GPT-3所需能耗,相当于汽车行驶地月往返距离。
今年5月,通过专家并行策略及优化技术,达摩院M6团队将万亿模型能耗降低超八成、效率提升近11倍。10月,M6再次突破业界极限,通过更细粒度的CPU offload、共享-解除算法等创新技术,让收敛效率进一步提升7倍,这使得模型规模扩大10倍的情况下,能耗未显著增加。这一系列突破极大降低了大模型研究门槛,让一台机器训练出一个千亿模型成为可能。
一、背景介绍
二、十万亿M6技术实现
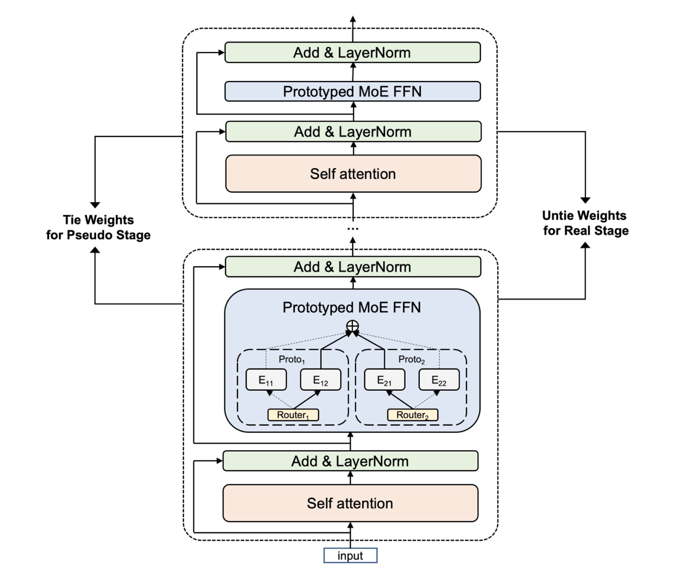
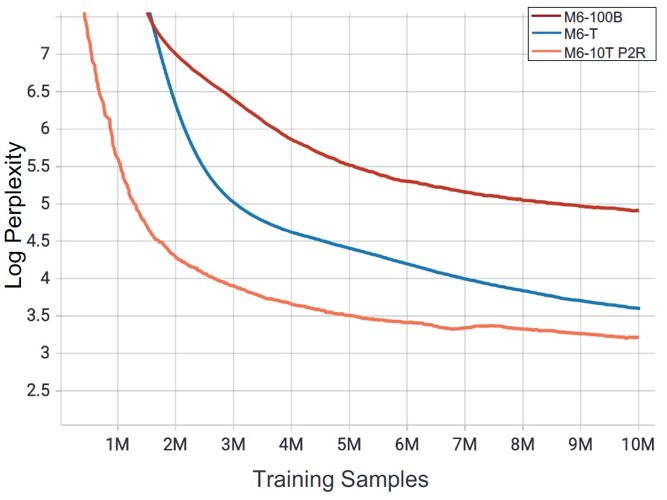
相比此前的万亿参数M6,M6-10T的参数量是原先的10倍没有显著的资源增加(480 vs 512 GPU); 相比万亿参数M6,M6-10T在样本量的维度上具有更快的收敛速度; 提出的共享解除机制将十万亿参数模型的训练速度提升7倍以上,并可广泛应用于其他同类大模型的训练。
三、M6能力再升级






四、M6服务化平台发布

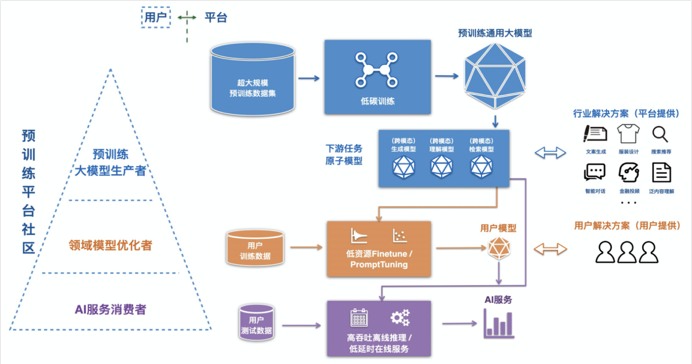
任务形式覆盖广:平台可以覆盖多模态(图文)输入输出的常见任务。 高性能 & 简单易用:用户快速试用只需要准备数据和简单修改参数,无需关注底层细节;平台底层实现集成系列优化提升效率,其中包括自研MoE分组策略等。 下游任务内源 + 支持自定义模型改造:用户可以编写自定义模型,只需开发少量接口。
五、大规模中文多模态评测基准MUGE发布

六、潜在科学应用方向
总结
评论