
语言模型将了解视觉世界?OpenAI 120亿参数图像版GPT-3发布
↑ 点击蓝字 关注极市平台
作者丨贾伟 梦佳来源丨智源社区编辑丨极市平台
极市导读
OpenAI的联合创始人IIya Sutskever 曾在吴恩达编辑的 《The Batch周刊 - 2020年终特刊》上撰文称“2021年,语言模型将开始了解视觉世界”。元旦之后,OpenAI 立马为这个说法提供了佐证。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
- DALL·E:一个利用文本-图像数据集,有着120亿参数的“GPT-3”,可以根据文本生成各种各样的图像;
- CLIP:可以通过自然语言的监督来有效学习视觉概念,只需要提供要识别的视觉类别名称,利用CLIP便能够做任意的视觉分类,类似于GPT-2和GPT-3的 “Zero-shot”功能。
这两项工作的突破性是无疑的,但同时作为前奏,也让人更加期待 OpenAI 接下来的 GPT-4了。
 输入:鳄梨形状的扶手椅输出:
输入:鳄梨形状的扶手椅输出:  输入:写着“ OpenAI”的店面输出:
输入:写着“ OpenAI”的店面输出:  GPT-3 给人们带来的深刻印象是,大模型可以执行各种文本生成任务。在ICML 2020 上的一篇论文“Image GPT”中,作者表明相同类型的神经网络也可以用于生成高保真度的图像。作为对比,DALL·E 的研究说明了,通过自然语言便可以直接做各种图像生成任务。 与 GPT-3一样,DALL·E 是一个transformer 语言模型,它同时接收文本和图像作为一个单一数据流,其中包含1280个tokens(256个文本,1024个图像),并利用最大似然训练并生成所有的 tokens。模型中的 64 个 self-attention层,每一个都有attention mask,这能够使每个image token都可以参与到 text token。DALL·E 对 text tokens 使用标准的因果掩码,对行、列或卷积注意力模式的image token使用稀疏注意力,具体这取决于每一层的情况。 与利用 GAN来做文本到图像的生成不同,DALL·E能够为大量五花八门的句子创造出似是而非的意象,这些句子很多时候本身就是对语言结构的探索。在生成之后,DALL·E采用 CLIP进行排序,从中选取最优结果,整个过程不需要进行任何筛选。 OpenAI的研究人员对DALL·E的结果进行了探索,包括:
GPT-3 给人们带来的深刻印象是,大模型可以执行各种文本生成任务。在ICML 2020 上的一篇论文“Image GPT”中,作者表明相同类型的神经网络也可以用于生成高保真度的图像。作为对比,DALL·E 的研究说明了,通过自然语言便可以直接做各种图像生成任务。 与 GPT-3一样,DALL·E 是一个transformer 语言模型,它同时接收文本和图像作为一个单一数据流,其中包含1280个tokens(256个文本,1024个图像),并利用最大似然训练并生成所有的 tokens。模型中的 64 个 self-attention层,每一个都有attention mask,这能够使每个image token都可以参与到 text token。DALL·E 对 text tokens 使用标准的因果掩码,对行、列或卷积注意力模式的image token使用稀疏注意力,具体这取决于每一层的情况。 与利用 GAN来做文本到图像的生成不同,DALL·E能够为大量五花八门的句子创造出似是而非的意象,这些句子很多时候本身就是对语言结构的探索。在生成之后,DALL·E采用 CLIP进行排序,从中选取最优结果,整个过程不需要进行任何筛选。 OpenAI的研究人员对DALL·E的结果进行了探索,包括:1、控制同一个对象的不同属性
输入:一个五角形的绿色钟输出:
2、同时控制多个对象以及它们的属性和空间关系
输入:一个小企鹅的表情,身着蓝帽子,红手套,绿衬衫,黄裤子输出: 从上面生成的例子看,虽然大多数情况生成的图片是符合要求的,但也有少量错误的案例。 虽然 DALL·E可以提供对少量对象属性和位置的某种程度的可控性,但成功率似乎取决于文本的措辞。从上面几个例子来看,随着引入对象的增多,DALL·E 越来越容易混淆对象和颜色之间的关联,成功率也急剧下降。 作者提到,DALL·E对文本的措辞非常脆弱,有时候用语义上等价的标题替代,会产生非常错误的结果。
从上面生成的例子看,虽然大多数情况生成的图片是符合要求的,但也有少量错误的案例。 虽然 DALL·E可以提供对少量对象属性和位置的某种程度的可控性,但成功率似乎取决于文本的措辞。从上面几个例子来看,随着引入对象的增多,DALL·E 越来越容易混淆对象和颜色之间的关联,成功率也急剧下降。 作者提到,DALL·E对文本的措辞非常脆弱,有时候用语义上等价的标题替代,会产生非常错误的结果。 3、视觉透视与立体:控制场景的视点,并渲染场景的 3D风格
输入:一只用体素做成的水豚坐在田野里输出:
4、内部/外部结构可视化
输入:核桃的横截面图输出:
5、推断背景细节
将文本翻译成图像的任务具有不唯一性:给出一个文本,通常会有“无限多”中可能的图像。例如,“日出时分,一只水豚坐在田野上”,根据水豚的方向,可能需要画一个阴影,尽管这个细节在文本中并没有被明确地提及。 输入:日出时分,一只水豚坐在田野上输出: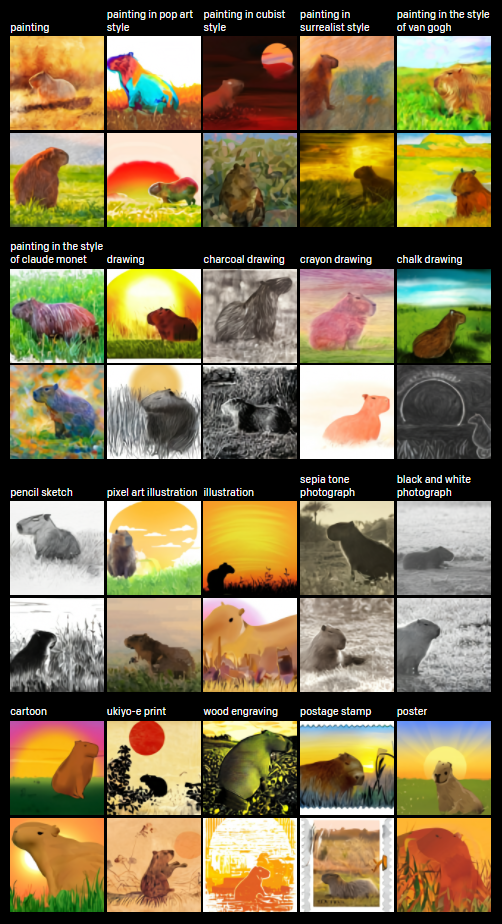
6、时装设计、室内设计
输入:一个穿着黑色皮夹克和金色百褶裙的女性模特输出: 输入:起居室里有两把白色扶手椅和一幅斗兽场的油画,油画被安装在一个现代壁炉上方输出:
输入:起居室里有两把白色扶手椅和一幅斗兽场的油画,油画被安装在一个现代壁炉上方输出:
7、将不相关的概念进行结合
语言的组合特性使我们能够把完全不相关的概念放在一起,从而来描述真实的或想象的事物。利用DALL·E,可以将语言的这种特性快速地转移到图像上。 输入:一只竖琴做的蜗牛输出:
8、动物插图
除了真实世界中不相关概念之间结合外,在艺术创作里面,有大量的可探索空间: 输入:一只长颈鹿和乌龟嵌合体输出:
9、零样本视觉推理
GPT-3可以执行多种任务,根据描述和提示来生成答案,而不需要任何额外的培训。例如,当提示语“ here is the sentence‘ a person walking his dog in the park’ translated into French: ”时,GPT-3回答“ un homme qui promène son chien dans le parc. ”这种能力称为零样本推理。DALL·E 可以将这种能力扩展到视觉领域,并且能够以正确的方式提示执行图像到图像的转换任务。 输入:和上面的真猫一模一样的猫的草图输出:
 输入:和上面第一列完全相同的茶壶,上面写着“ gpt”输出:
输入:和上面第一列完全相同的茶壶,上面写着“ gpt”输出:  输入:一系列的几何图形列表输出:
输入:一系列的几何图形列表输出: 
10、地理概念
作者发现 DALL·E 已经习得了地理知识、地标和社区等概念。它对这些概念的了解在某些方面呈现出惊人的精确,而在其他方面又有一定缺陷。 输入:一张中国菜的照片输出:(有些食物看起来怪怪的)

11、时间概念
除了探索 DALL·E 对于不同空间的认知,作者也探索了其对时间变化的认知。 输入:20年代电话的照片
2 CLIP:零样本学习神器 与DALL·E 一同发布的还有神经网络CLIP(对比式语言-图像预训练,Contrastive Language–Image Pre-training)。 简单来说,它可以从自然语言监督中有效地学习视觉概念。CLIP 可适用于任何视觉分类基准,只需提供要识别的视觉类别的名称,类似于 GPT-2和 GPT-3 的“零样本学习”(zero-shot)能力。

1、方法
如下图所示,是CLIP的结构图: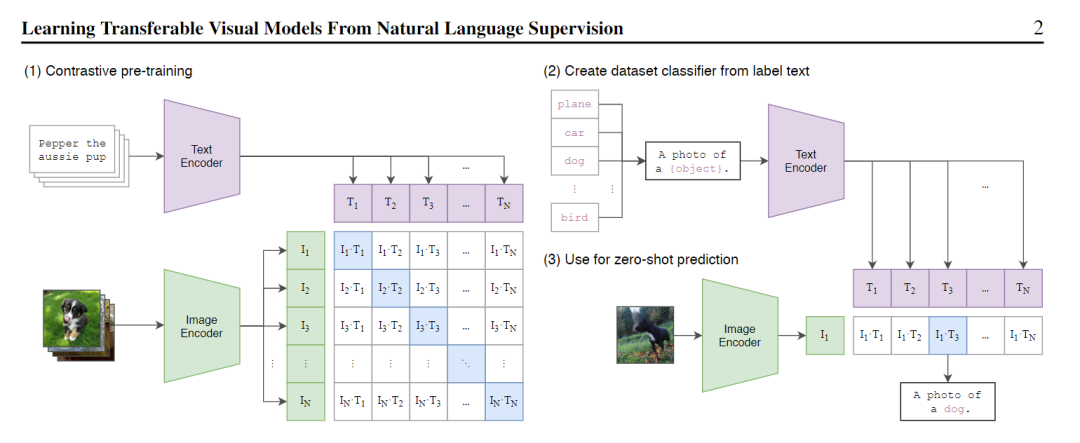 标准的图像模型,联合训练图像特征提取器和线性分类器,预测一些标签。CLIP再联合训练图像编码器和文本编码器,从而预测一批(图像,文本)对。在测试时,学习的文本编码器通过嵌入目标数据集类别的名称或描述,来合成zero-shot线性分类器。 具体来说,作者使用了大量可用的监管资源,包括文本和在网上能够找到的图像配对。利用这些数据,CLIP可以训练出一个proxy,当给定一张图片时,便能预测在32768个随机采样的文本片段集中哪个片段更匹配。这里的方案是,CLIP模型将学习识别图像中的多种视觉概念,然后将它们与图像名字进行关联。 这种方式的结果是,CLIP模型在随后可以应用到几乎任意的视觉分类任务当中。 例如,如果数据集的任务是对“狗”和“猫”的图像进行分类,那么便可以针对每个图像进行检查,确认CLIP模型是否会预测响应的文本“狗的照片”、“猫的照片”来与之配对。
标准的图像模型,联合训练图像特征提取器和线性分类器,预测一些标签。CLIP再联合训练图像编码器和文本编码器,从而预测一批(图像,文本)对。在测试时,学习的文本编码器通过嵌入目标数据集类别的名称或描述,来合成zero-shot线性分类器。 具体来说,作者使用了大量可用的监管资源,包括文本和在网上能够找到的图像配对。利用这些数据,CLIP可以训练出一个proxy,当给定一张图片时,便能预测在32768个随机采样的文本片段集中哪个片段更匹配。这里的方案是,CLIP模型将学习识别图像中的多种视觉概念,然后将它们与图像名字进行关联。 这种方式的结果是,CLIP模型在随后可以应用到几乎任意的视觉分类任务当中。 例如,如果数据集的任务是对“狗”和“猫”的图像进行分类,那么便可以针对每个图像进行检查,确认CLIP模型是否会预测响应的文本“狗的照片”、“猫的照片”来与之配对。 2、优缺点
CLIP的方法可以解决基于标准深度学习做计算机视觉所遇到的许多问题,例如: 数据集昂贵:深度学习需要大量人工标注的数据,这些数据集构建的成本很高。ImageNet 需要超过25000名工作人员为22000个对象标注1400万张图像;相比之下,CLIP 可以从互联网上已经公开可用的文本图像中学习。 应用范围狭窄:在ImageNet 上训练的模型,即使可以预测1000个 ImageNet 类别,但也仅限于此,如果想要执行其他新数据集上的任务,就还需要进行调整。相比之下,CLIP 可以适用于执行各种各样的视觉分类任务,而不需要额外的训练示例。 现实场景中表现不佳:现有模型多能够在实验室环境中超过人类,但一旦部署到现实场景,性能便会大幅下降,原因在于模型仅通过优化基准性能来“欺骗”,就像一个通过仅研究过去几年考试中的问题而通过考试的学生一样。相反,CLIP模型可以根据基准进行评估,而无需训练其数据,于是这种“欺骗”方式便不再存在。 当然 CLIP 的局限性也很明显,- 它在较为抽象或者系统性的任务(例如计算图像中的对象数量)和更为复杂的任务(例如预测图像中最近的汽车有多远)上,表现并不是很好,仅比随机猜测好一点点。
- 对于训练集未覆盖的图像的概括性较差,例如尽管CLIP学习了更为复杂的OCR系统的数据,但在对MNIST数据集进行评估时,准确率仅为88%(人类为99.95%)
- CLIP的zero-shot分类器对文本的措辞表现敏感。
代码地址:
https://github.com/openai/CLIP
论文地址:
https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language.pdf
参考链接:
https://openai.com/blog/dall-e/
https://techcrunch.com/2021/01/05/openais-dall-e-creates-plausible-images-of-literally-anything-you-ask-it-to/
推荐阅读
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
△长按添加极市小助手
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~

评论