
陈天奇高赞文章:新一代深度学习编译技术变革和展望
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
陈天奇是机器学习领域著名的青年华人学者之一,本科毕业于上海交通大学ACM班,博士毕业于华盛顿大学计算机系,研究方向为大规模机器学习。在本文中,陈天奇回答了目前深度学习编译技术的瓶颈在哪里,下一代技术是什么?
现状是什么:当前深度学习编译解决方案和瓶颈
四类抽象
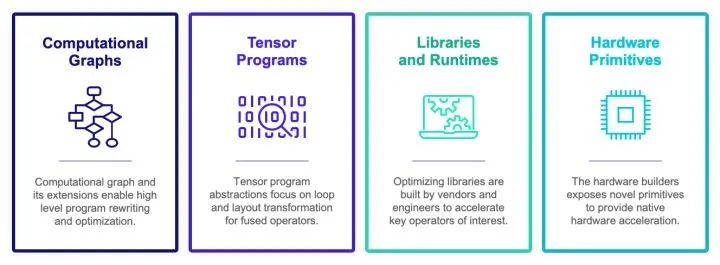
计算图表示(computational graph):计算图可以把深度学习程序表示成DAG,然后进行类似于算子融合,改写,并行等高级优化。Relay, XLA, Torch-MLIR,ONXX 等基本都在这一级别。
张量程序表示(tensor program): 在这个级别我们需要对子图进行循环优化,对于DSA支持还要包含张量化和内存搬移的优化。
算子库和运行环境(library and runtime): 算子库本身依然是我们快速引入专家输入优化性能的方式。同时运行环境快速支持数据结构运行库。
硬件专用指令 (hardware primitive) :专用硬件和可编程深度学习加速器也引入了我们专用硬件张量指令的需求。
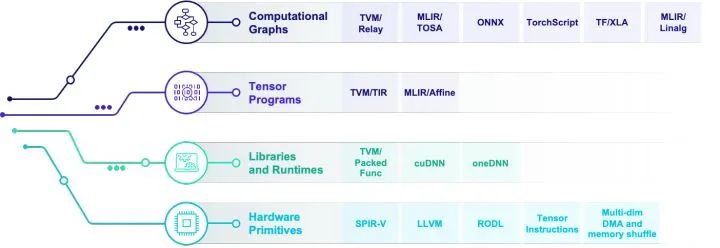
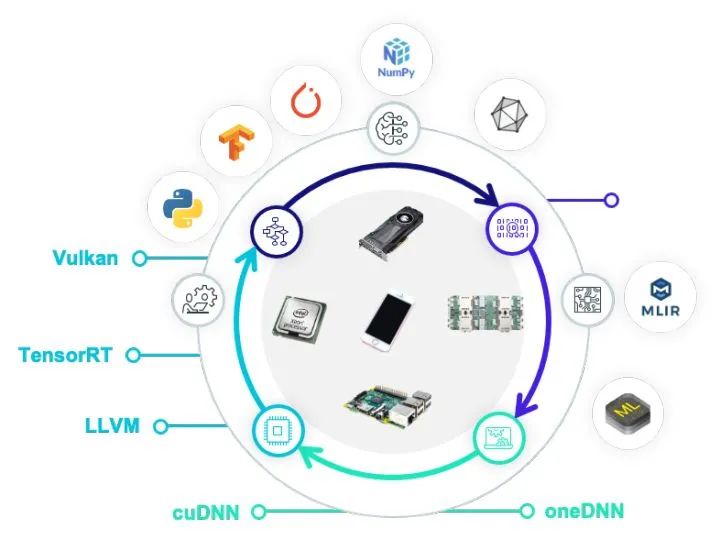
目前的解决方案
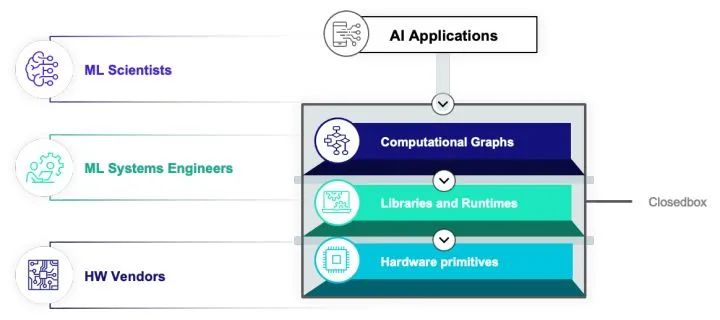
两种隔阂
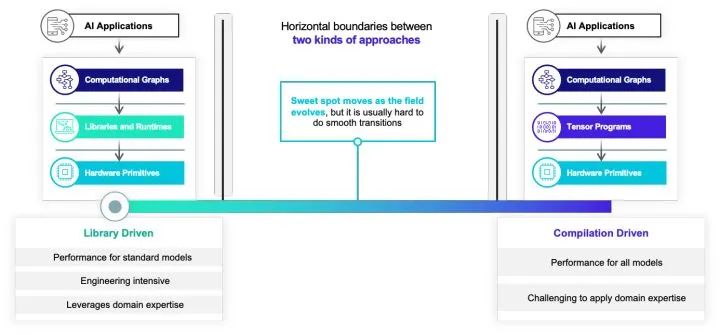
未来在哪里:从箭头到圈
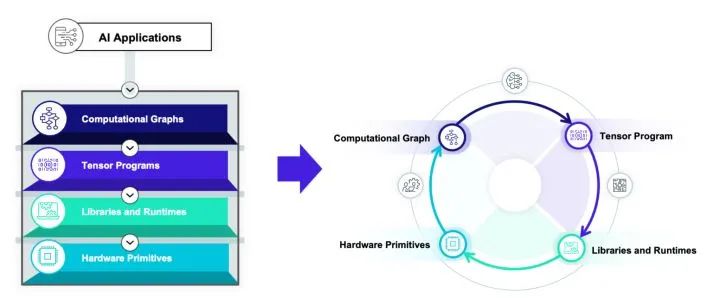
Unify: 统一多层抽象
Interact: 交互开放迭代
Automate: 自动优化整合
Unify: 统一多层抽象
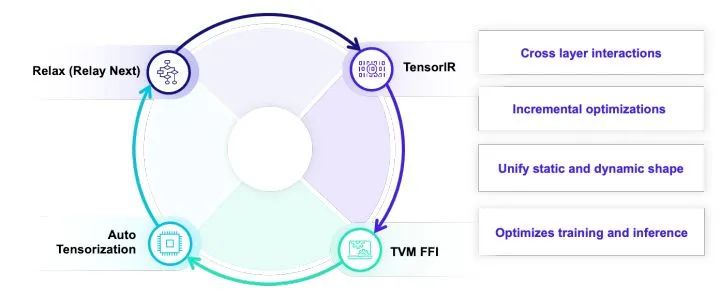

Interact: 交互开放迭代
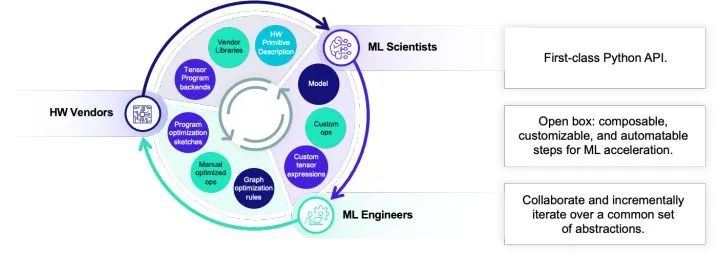
Automate: 自动优化整合
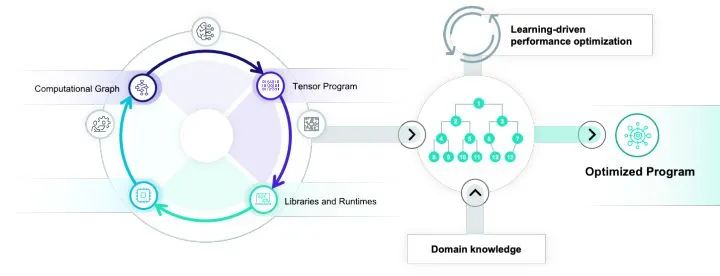
总结和未来展望
评论