
【深度学习】视频分类技术整理

最近在做多模态视频分类,本文整理了一下视频分类的技术,分享给大家。
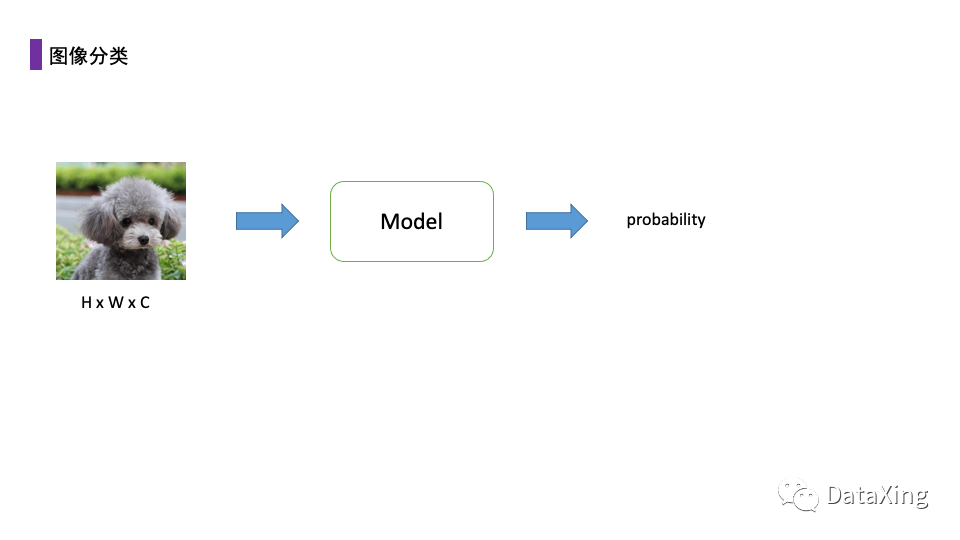
传统的图像分类任务中,一般输入的为一幅HxWxC的二维图像,经过卷积等操作后输出类别概率。
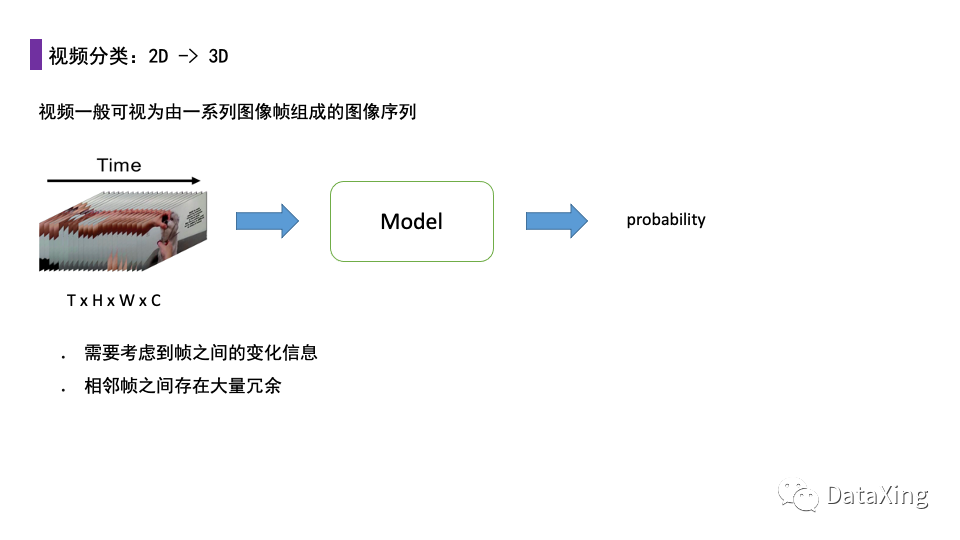
对于视频任务,输入是由连续的二维图像帧组成的一个存在时序关系的二维图像序列,或是视为一个TxHxWxC的四维张量。
这样的数据具有以下特点:
1. 帧之间的变化信息往往能反映视频的内容;
2. 相邻帧之间变化一般较小,存在大量的冗余。

最直观和最简单的做法是沿用静态图像分类的方法,直接将每个视频帧视为独立的二维图像看待,利用神经网络提取每个视频帧的特征,将这个视频所有帧的特征向量取平均得到整个视频的特征向量,然后进行分类识别,或是直接每个帧得到一个预测结果,最后在所有帧结果中取共识。
这种做法的好处是计算量很小,计算开销与一般的二维图像分类相近,并且实现非常简单。但是这种做法不会考虑帧之间的相互关系,平均池化或是取共识的方法都比较简单,会损失大量信息。在视频时长很短,帧间变化相对较小的时候不失为一种好的方法。

另一种方案同样是沿用静态图像分类的方法,直接将每个视频帧视为独立的二维图像看待,但是在融合时使用VLAD的方式。VLAD是2010年提出的一种大规模图像库中进行图像检索的算法,它可以将一个NxD的特征矩阵转换成KxD(K<d)。在这种方法下,我们对一个视频的各个帧特征进行聚类得到多个聚类中心,将所有的特征分配到指定的聚类中心中,对于每个聚类区域中的特征向量分别计算,最终concat或加权求和所有的聚类区域的特征向量作为整个视频的特征向量。
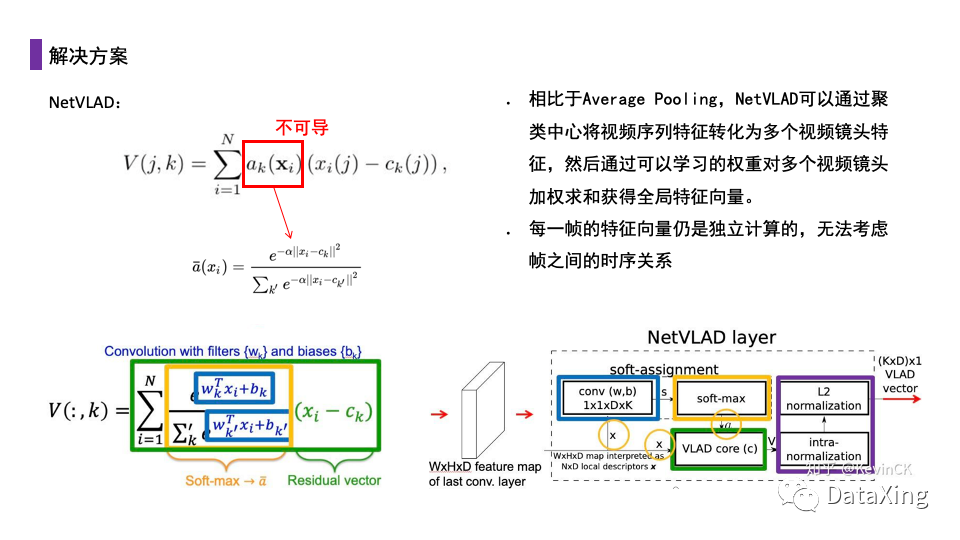
在原始的VLAD中ak项是一个不可导的项,同时聚类也是不可导的操作,我们使用NetVLAD的改进,将每个特征向量与所有聚类中心求距离的softmax获得该特征向量最近的聚类中心的概率,聚类中心用可学习的参数确定。
相比平均池化,NetVLAD可以通过聚类中心将视频序列特征转化为多个视频镜头特征,然后通过可以学习的权重对多个视频镜头加权求和获得全局特征向量。但是这种做法每一帧的特征向量仍是独立计算的,无法考虑帧之间的时序关系和变化信息。
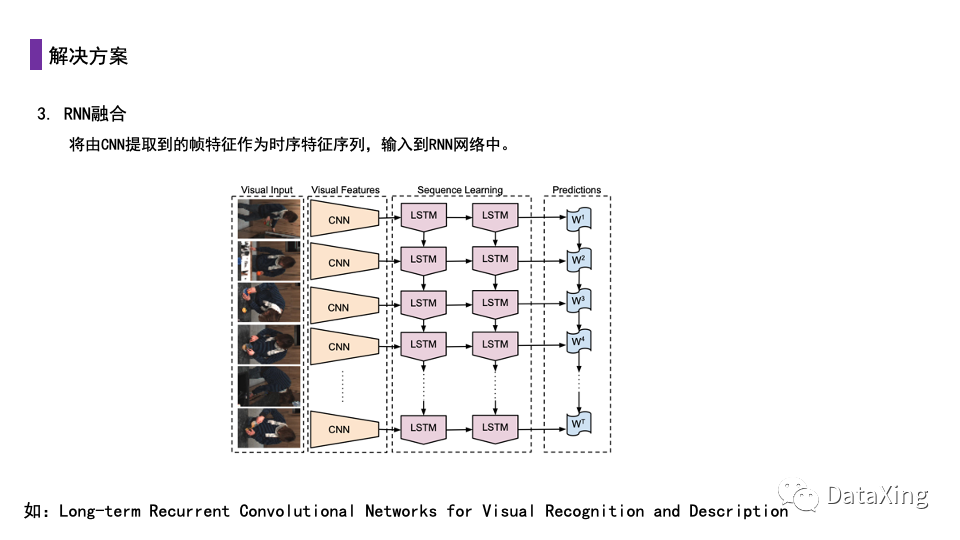
对于存在时序关系的序列,使用RNN是一种通用的做法。具体做法为使用网络(一般为CNN)将每个视频帧序列提取为特征序列,再将特征序列按时序顺序输入到如LSTM的RNN中,以RNN的最终输出作为分类输出。
这种做法可以考虑帧之间的时序关系,理论上具有更好的效果。但是在实际实验中,这种方案相比第一种解决方案并没有明显优势,这可能是因为RNN对于长序列存在遗忘问题,而短序列视频使用简单的静态方法效果就已经足够好。
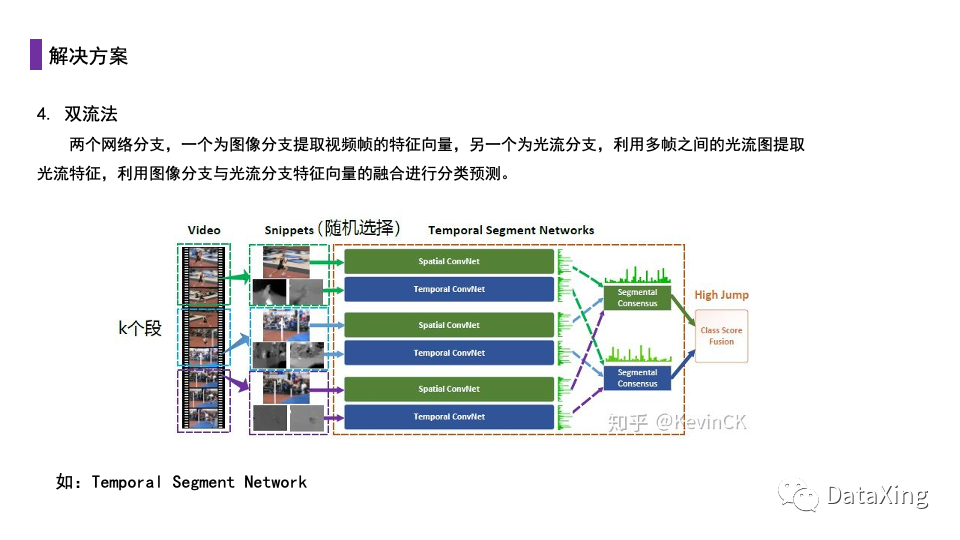
双流法是一种比较好的做法。这种方法使用两个网络分支一个为图像分支提取视频帧的特征向量,另一个为光流分支,利用多帧之间的光流图提取光流特征,利用图像分支与光流分支特征向量的融合进行分类预测。
这种做法由于是静态方法,计算量相对较小,从光流中也能提取到帧之间的变化信息。但是光流的计算会引入额外的开销。

我们也可以直接将传统的二维卷积核改造为三维卷积核,将输入的图像序列作为一个四维张量整体来对待。
代表做法有C3D,I3D,Slow-Fast等。
这种方法实验效果比较好,但是由于三维卷积复杂度提高了一个数量级,往往需要大量的数据才能取得不错的效果,在数据不够时可能使效果很差甚至训练失败。
基于此,也提出了一系列方法简化三维卷积的计算量,如基于低秩近似的P3D等。


TimeSformer在ViT的基础上,提出了五种不同的注意力计算方式,实现计算复杂度和Attention视野的trade-off:
1. 空间注意力机制(S):只取同一帧内的图像块进行自注意力机制;
2. 时空共同注意力机制(ST):取所有帧中的所有图像块进行注意力机制;
3. 分开的时空注意力机制(T+S):先对同一帧中的所有图像块进行自注意力机制,然后对不同帧中对应位置的图像块进行注意力机制;
4. 稀疏局部全局注意力机制(L+G):先利用所有帧中,相邻的 H/2 和 W/2 的图像块计算局部的注意力,然后在空间上,使用2个图像块的步长,在整个序列中计算自注意力机制,这个可以看做全局的时空注意力更快的近似;
5. 轴向的注意力机制(T+W+H):先在时间维度上进行自注意力机制,然后在纵坐标相同的图像块上进行自注意力机制,最后在横坐标相同的图像块上进行自注意力机制。
经过实验,作者发现T+S注意力方式的效果是最好的,在大大减少了Attention的计算开销的同时,效果甚至优于计算全部patch的ST注意力。
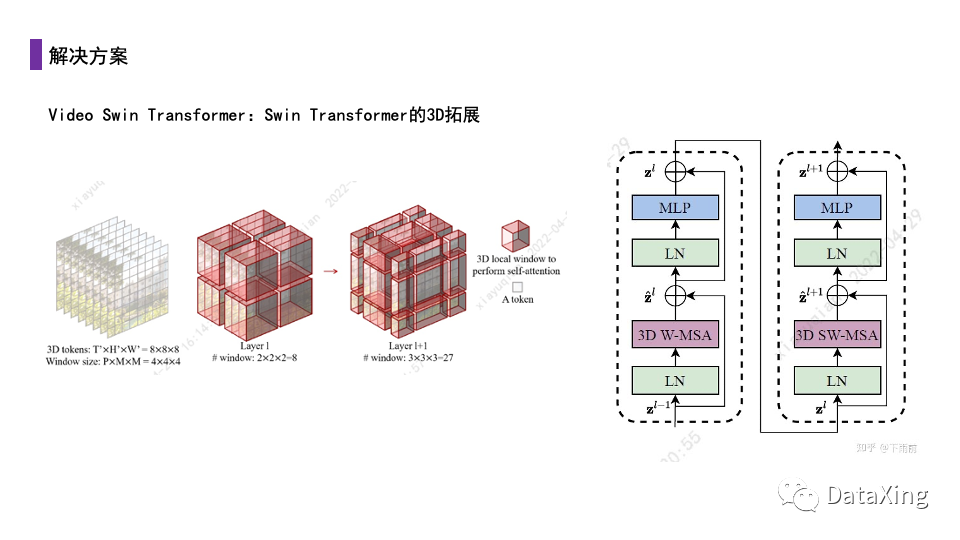
Video Swin Transformer是Swin Transformer的三维拓展版本,这种方法简单的将计算注意力的窗口从二维拓展至三维,在实验中就取得了相当不错的效果。
在我们的实验中,Video Swin Transformer是目前比较好的视频理解backbone,实验结果显著优于上面的方法。
完整版的源文件可以点击阅读原文获取。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码