
自注意力机制和全连接的图卷积网络(GCN)有什么区别联系?
本文整理自知乎问答,仅用于学术分享,著作权归作者所有。如有侵权,请联系后台作删文处理。加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
观点一
作者|Guohao Li
https://www.zhihu.com/question/366088445/answer/1023290162
来说一下自己的理解。首先结论是大部分GCN和Self-attention都属于Message Passing(消息传递)。GCN中的Message从节点的邻居节点传播来,Self-attention的Message从Query的Key-Value传播来。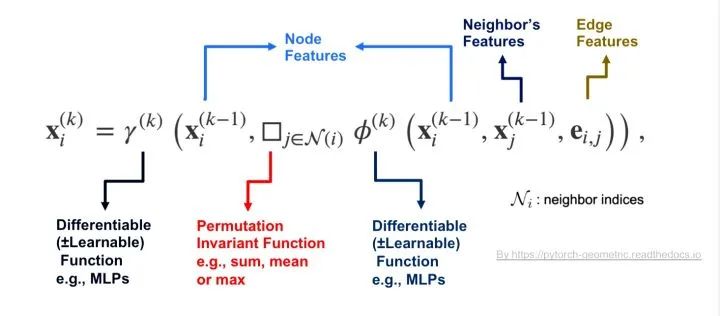 Message Passing[4]先看看什么是Message Passing。我们知道在实现和设计GCN的时候很多时候都是采用Message Passing的框架[3],其思想是把每个节点的领域的特征信息传递到节点上。在这里举例描述一个节点i在第k层GCN卷积的过程:1)把节点i的每一个邻居j与该节点的特征经过函数变换后形成一条Message(对应公示里函数\phi里面的操作);2)经过一个Permutation Invariant(置换不变性)函数把该节点领域的所有Message聚合在一起(对应函数\square);3)再经过函数\gamma把聚合的领域信息和节点特征做一次函数变化,得到该节点在第k层图卷积后的特征X_i。那么Self-attention是否也落在Message Passing的框架内呢?我们先回顾一下Self-attention一般是怎么计算的[2],这里举例一个Query i的经过attention的计算过程:1】Query i的特征x_i会和每一个Key j的特征计算一个相似度e_ij;
Message Passing[4]先看看什么是Message Passing。我们知道在实现和设计GCN的时候很多时候都是采用Message Passing的框架[3],其思想是把每个节点的领域的特征信息传递到节点上。在这里举例描述一个节点i在第k层GCN卷积的过程:1)把节点i的每一个邻居j与该节点的特征经过函数变换后形成一条Message(对应公示里函数\phi里面的操作);2)经过一个Permutation Invariant(置换不变性)函数把该节点领域的所有Message聚合在一起(对应函数\square);3)再经过函数\gamma把聚合的领域信息和节点特征做一次函数变化,得到该节点在第k层图卷积后的特征X_i。那么Self-attention是否也落在Message Passing的框架内呢?我们先回顾一下Self-attention一般是怎么计算的[2],这里举例一个Query i的经过attention的计算过程:1】Query i的特征x_i会和每一个Key j的特征计算一个相似度e_ij;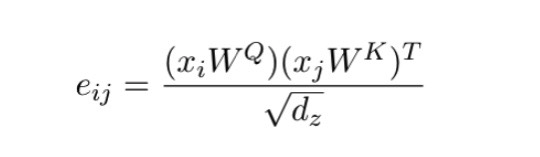 2】得到Query i与所有Key的相似度后经过SoftMax得到Attention coefficient(注意力系数)\alpha_ij;
2】得到Query i与所有Key的相似度后经过SoftMax得到Attention coefficient(注意力系数)\alpha_ij;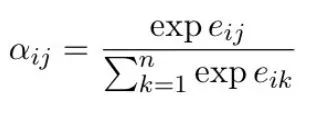 3】通过Attention coefficient加权Value j计算出Query i最后的输出z_j。
3】通过Attention coefficient加权Value j计算出Query i最后的输出z_j。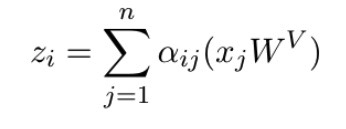 好了,那么我们来看看它们之间的对应关系。首先结论是Self-attention计算中的1】2】3】是对应Message Passing里的1)2)的。如果用Message Passing来实现Self-attention,那么我们可以这么一一对应:-1 每个Key-Value j可以看作是Query i的邻居;-2 相似度和注意力系数的计算和最后3】中Value j与注意力系数相乘的操作可以对应为Message Passing中第一步构成Message的过程;-3 最后Self-attention的求和运算对应Message Passing中第二步的Permutation Invariant函数,也就是说这里聚合领域信息的过程是通过Query对Key-Value聚合而来。那么也就是说,Attention的过程是把每一个Query和所有Key相连得到一个Complete Bipartite Graph(左边是Query右边的Key-Value),然后在这图上去对所有Query节点做Message Passing。当然Query和Key-Value一样的Self-attention就是在一般的Complete Graph上做Message Passing了。
好了,那么我们来看看它们之间的对应关系。首先结论是Self-attention计算中的1】2】3】是对应Message Passing里的1)2)的。如果用Message Passing来实现Self-attention,那么我们可以这么一一对应:-1 每个Key-Value j可以看作是Query i的邻居;-2 相似度和注意力系数的计算和最后3】中Value j与注意力系数相乘的操作可以对应为Message Passing中第一步构成Message的过程;-3 最后Self-attention的求和运算对应Message Passing中第二步的Permutation Invariant函数,也就是说这里聚合领域信息的过程是通过Query对Key-Value聚合而来。那么也就是说,Attention的过程是把每一个Query和所有Key相连得到一个Complete Bipartite Graph(左边是Query右边的Key-Value),然后在这图上去对所有Query节点做Message Passing。当然Query和Key-Value一样的Self-attention就是在一般的Complete Graph上做Message Passing了。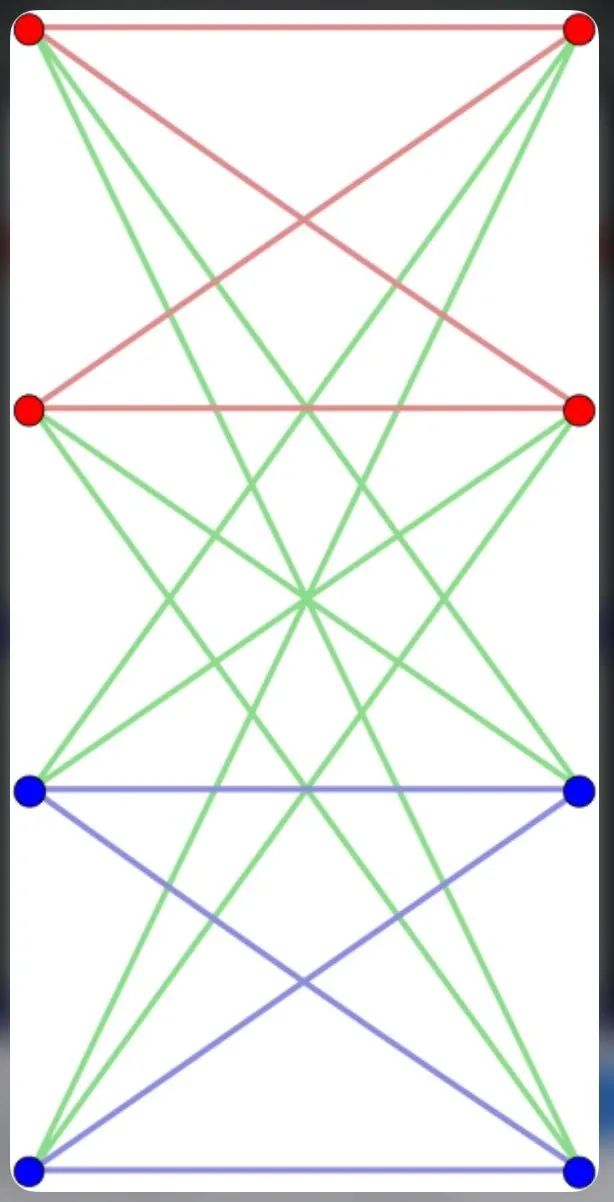 Complete Bipartite Graph看到这里大家可能疑问那么为什么Self attention里面没有了Message Passing中第三步把聚合的信息和节点信息经过\gamma函数做变换的过程呢。是的,如果没有了这一步很可能学习过程中Query的原来特征会丢失,其实这一步在Attention is all your need[1]里还是有的,不信你看:
Complete Bipartite Graph看到这里大家可能疑问那么为什么Self attention里面没有了Message Passing中第三步把聚合的信息和节点信息经过\gamma函数做变换的过程呢。是的,如果没有了这一步很可能学习过程中Query的原来特征会丢失,其实这一步在Attention is all your need[1]里还是有的,不信你看: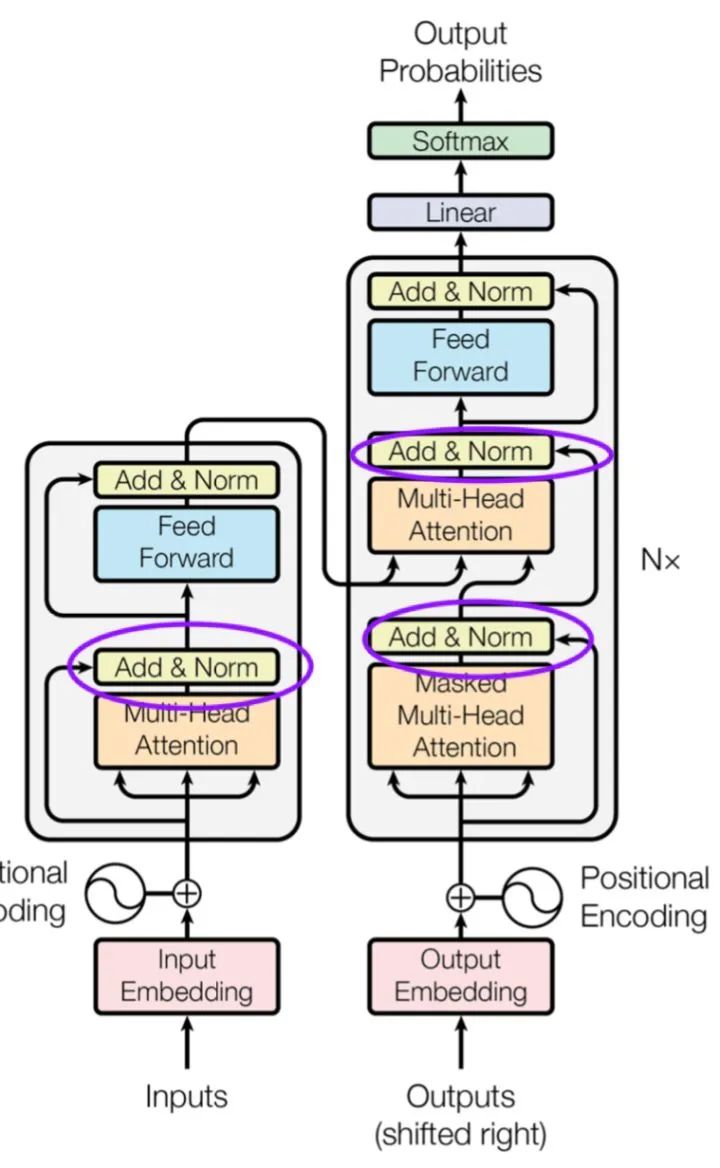 在每一次经过Self-Attention之后基本上都是有Skip connection+MLP的,这里某种程度上对应了Message Passing里的\gamma函数不是吗?那么说白了GCN和Self-attention都落在Message Passing(消息传递)框架里。GCN中的Message从节点的邻居节点传播来,Self-attention的Message从Query的Key-Value传播来。如果称所有的Message Passing函数都是GCN的话,那么Self-attention也就是GCN作用Query和Key-Value所构成Complete Garph上的一种特例。也正如乃岩@Naiyan Wang的回答一样。可以说NLP中GCN应该大有可为,毕竟Self-attention可以看出是GCN一种,那么肯定存在比Self-attention表达能力更强和适用范围更广的GCN。感谢评论里 @叶子豪的补充,DGL团队写了个很详尽的用Message Passing实现Transformer的教程。对具体实现感兴趣的同学可以去读一下:DGL Transformer Tutorial。Reference:1. Attention is All You Need2. Self-Attention with Relative Position Representations3. Pytorch Geometric4. DeepGCNs for Representation Learning on Graphs
在每一次经过Self-Attention之后基本上都是有Skip connection+MLP的,这里某种程度上对应了Message Passing里的\gamma函数不是吗?那么说白了GCN和Self-attention都落在Message Passing(消息传递)框架里。GCN中的Message从节点的邻居节点传播来,Self-attention的Message从Query的Key-Value传播来。如果称所有的Message Passing函数都是GCN的话,那么Self-attention也就是GCN作用Query和Key-Value所构成Complete Garph上的一种特例。也正如乃岩@Naiyan Wang的回答一样。可以说NLP中GCN应该大有可为,毕竟Self-attention可以看出是GCN一种,那么肯定存在比Self-attention表达能力更强和适用范围更广的GCN。感谢评论里 @叶子豪的补充,DGL团队写了个很详尽的用Message Passing实现Transformer的教程。对具体实现感兴趣的同学可以去读一下:DGL Transformer Tutorial。Reference:1. Attention is All You Need2. Self-Attention with Relative Position Representations3. Pytorch Geometric4. DeepGCNs for Representation Learning on Graphs观点二
作者|Houye
https://www.zhihu.com/question/366088445/answer/1022692208
来说一下自己的理解。GAT中的Attention就是self-attention,作者在论文中已经说了

推荐阅读
注意力机制在分类网络中的应用:SENet、SKNet、CBAM
极市干货 | 第60期直播回放-张航-ResNeSt:拆分注意力网络
通道注意力超强改进,轻量模块ECANet来了!即插即用,显著提高CNN性能|已开源
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~
△长按添加极市小助手
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ 
评论